 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Inferring Teachers' Geometric Content Knowledge: A Skills Based Approach
Apr 15, 2026Assessing teachers' geometric content knowledge is essential for geometry instructional quality and student learning, but difficult to scale. The Van Hiele model characterizes geometric reasoning through five hierarchical levels. Traditional Van Hiele assessment relies on manual expert analysis of open-ended responses. This process is time-consuming, costly, and prevents large-scale evaluation. This study develops an automated approach for diagnosing teachers' Van Hiele reasoning levels using large language models grounded in educational theory. Our central hypothesis is that integrating explicit skills information significantly improves Van Hiele classification. In collaboration with mathematics education researchers, we built a structured skills dictionary decomposing the Van Hiele levels into 33 fine-grained reasoning skills. Through a custom web platform, 31 pre-service teachers solved geometry problems, yielding 226 responses. Expert researchers then annotated each response with its Van Hiele level and demonstrated skills from the dictionary. Using this annotated dataset, we implemented two classification approaches: (1) retrieval-augmented generation (RAG) and (2) multi-task learning (MTL). Each approach compared a skills-aware variant incorporating the skills dictionary against a baseline without skills information. Results showed that for both methods, skills-aware variants significantly outperformed baselines across multiple evaluation metrics. This work provides the first automated approach for Van Hiele level classification from open-ended responses. It offers a scalable, theory-grounded method for assessing teachers' geometric reasoning that can enable large-scale evaluation and support adaptive, personalized teacher learning systems.
Detecting Struggling Student Programmers using Proficiency Taxonomies
Aug 24, 2025Early detection of struggling student programmers is crucial for providing them with personalized support. While multiple AI-based approaches have been proposed for this problem, they do not explicitly reason about students' programming skills in the model. This study addresses this gap by developing in collaboration with educators a taxonomy of proficiencies that categorizes how students solve coding tasks and is embedded in the detection model. Our model, termed the Proficiency Taxonomy Model (PTM), simultaneously learns the student's coding skills based on their coding history and predicts whether they will struggle on a new task. We extensively evaluated the effectiveness of the PTM model on two separate datasets from introductory Java and Python courses for beginner programmers. Experimental results demonstrate that PTM outperforms state-of-the-art models in predicting struggling students. The paper showcases the potential of combining structured insights from teachers for early identification of those needing assistance in learning to code.
Automatic Creativity Measurement in Scratch Programs Across Modalities
Nov 07, 2022Promoting creativity is considered an important goal of education, but creativity is notoriously hard to measure.In this paper, we make the journey fromdefining a formal measure of creativity that is efficientlycomputable to applying the measure in a practical domain. The measure is general and relies on coretheoretical concepts in creativity theory, namely fluency, flexibility, and originality, integratingwith prior cognitive science literature. We adapted the general measure for projects in the popular visual programming language Scratch.We designed a machine learning model for predicting the creativity of Scratch projects, trained and evaluated on human expert creativity assessments in an extensive user study. Our results show that opinions about creativity in Scratch varied widely across experts. The automatic creativity assessment aligned with the assessment of the human experts more than the experts agreed with each other. This is a first step in providing computational models for measuring creativity that can be applied to educational technologies, and to scale up the benefit of creativity education in schools.
Detecting Suicide Risk in Online Counseling Services: A Study in a Low-Resource Language
Sep 11, 2022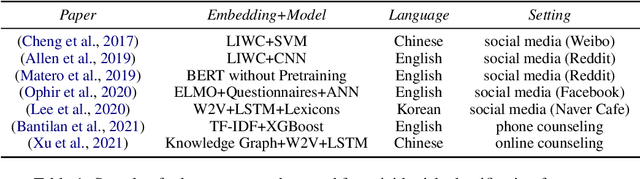
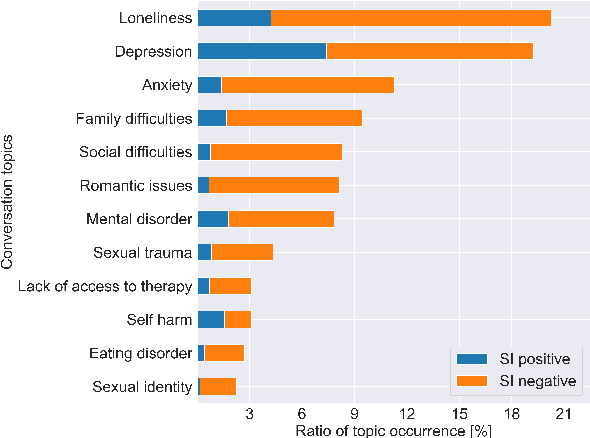

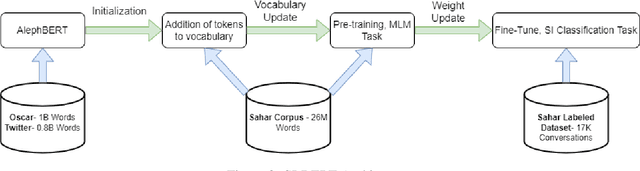
With the increased awareness of situations of mental crisis and their societal impact, online services providing emergency support are becoming commonplace in many countries. Computational models, trained on discussions between help-seekers and providers, can support suicide prevention by identifying at-risk individuals. However, the lack of domain-specific models, especially in low-resource languages, poses a significant challenge for the automatic detection of suicide risk. We propose a model that combines pre-trained language models (PLM) with a fixed set of manually crafted (and clinically approved) set of suicidal cues, followed by a two-stage fine-tuning process. Our model achieves 0.91 ROC-AUC and an F2-score of 0.55, significantly outperforming an array of strong baselines even early on in the conversation, which is critical for real-time detection in the field. Moreover, the model performs well across genders and age groups.
Revisiting Citizen Science Through the Lens of Hybrid Intelligence
Apr 30, 2021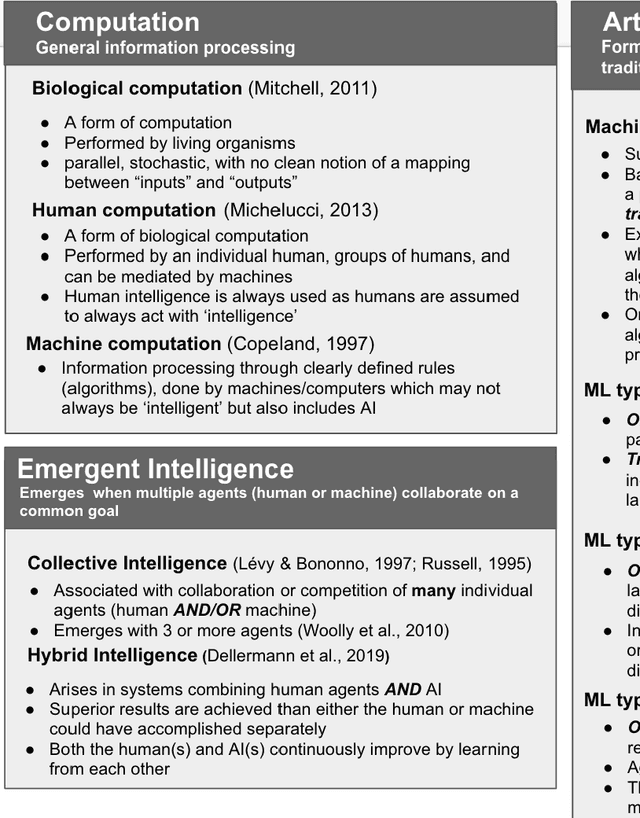
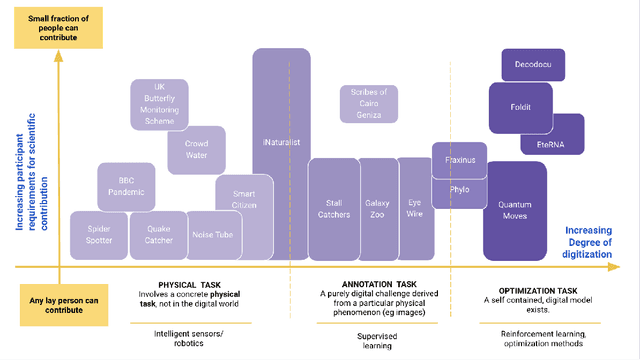
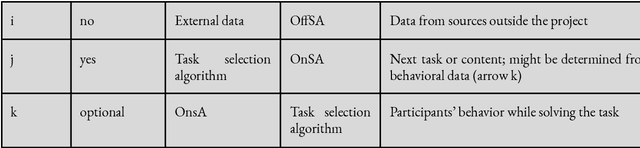
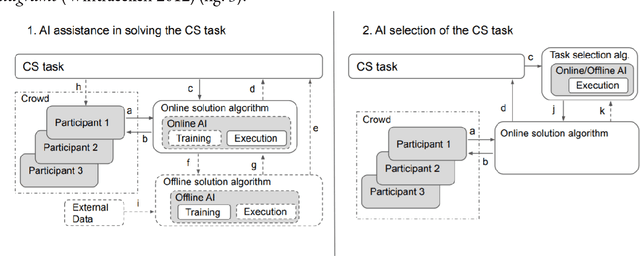
Artificial Intelligence (AI) can augment and sometimes even replace human cognition. Inspired by efforts to value human agency alongside productivity, we discuss the benefits of solving Citizen Science (CS) tasks with Hybrid Intelligence (HI), a synergetic mixture of human and artificial intelligence. Currently there is no clear framework or methodology on how to create such an effective mixture. Due to the unique participant-centered set of values and the abundance of tasks drawing upon both human common sense and complex 21st century skills, we believe that the field of CS offers an invaluable testbed for the development of HI and human-centered AI of the 21st century, while benefiting CS as well. In order to investigate this potential, we first relate CS to adjacent computational disciplines. Then, we demonstrate that CS projects can be grouped according to their potential for HI-enhancement by examining two key dimensions: the level of digitization and the amount of knowledge or experience required for participation. Finally, we propose a framework for types of human-AI interaction in CS based on established criteria of HI. This "HI lens" provides the CS community with an overview of several ways to utilize the combination of AI and human intelligence in their projects. It also allows the AI community to gain ideas on how developing AI in CS projects can further their own field.
Best Practices for Transparency in Machine Generated Personalization
Apr 02, 2020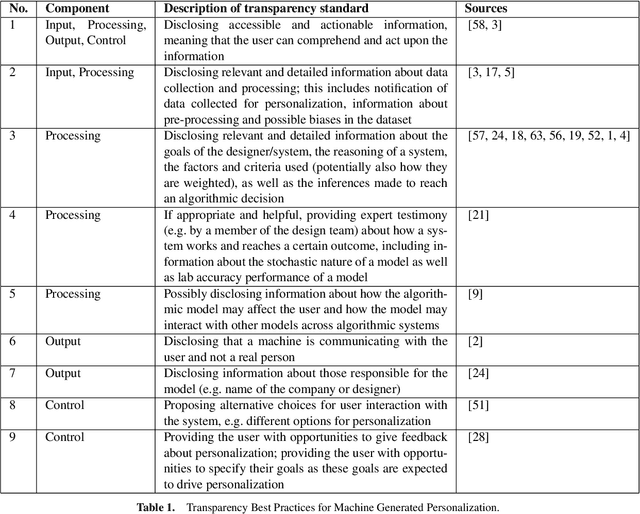
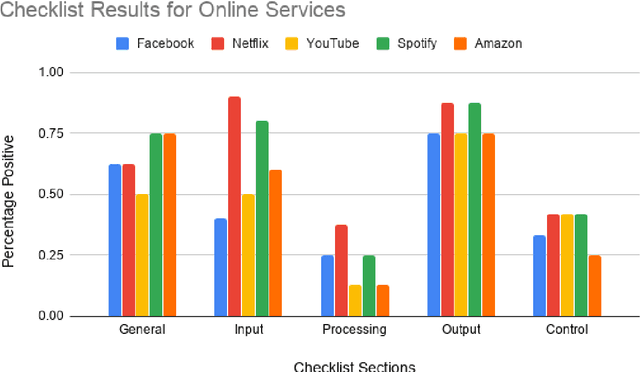
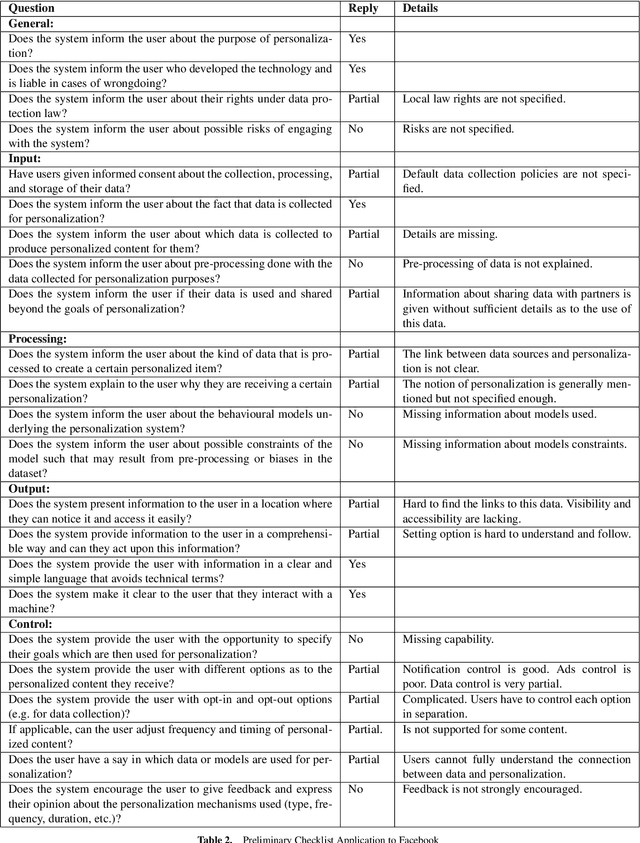
Machine generated personalization is increasingly used in online systems. Personalization is intended to provide users with relevant content, products, and solutions that address their respective needs and preferences. However, users are becoming increasingly vulnerable to online manipulation due to algorithmic advancements and lack of transparency. Such manipulation decreases users' levels of trust, autonomy, and satisfaction concerning the systems with which they interact. Increasing transparency is an important goal for personalization based systems. Unfortunately, system designers lack guidance in assessing and implementing transparency in their developed systems. In this work we combine insights from technology ethics and computer science to generate a list of transparency best practices for machine generated personalization. Based on these best practices, we develop a checklist to be used by designers wishing to evaluate and increase the transparency of their algorithmic systems. Adopting a designer perspective, we apply the checklist to prominent online services and discuss its advantages and shortcomings. We encourage researchers to adopt the checklist in various environments and to work towards a consensus-based tool for measuring transparency in the personalization community.
A difficulty ranking approach to personalization in E-learning
Jul 28, 2019
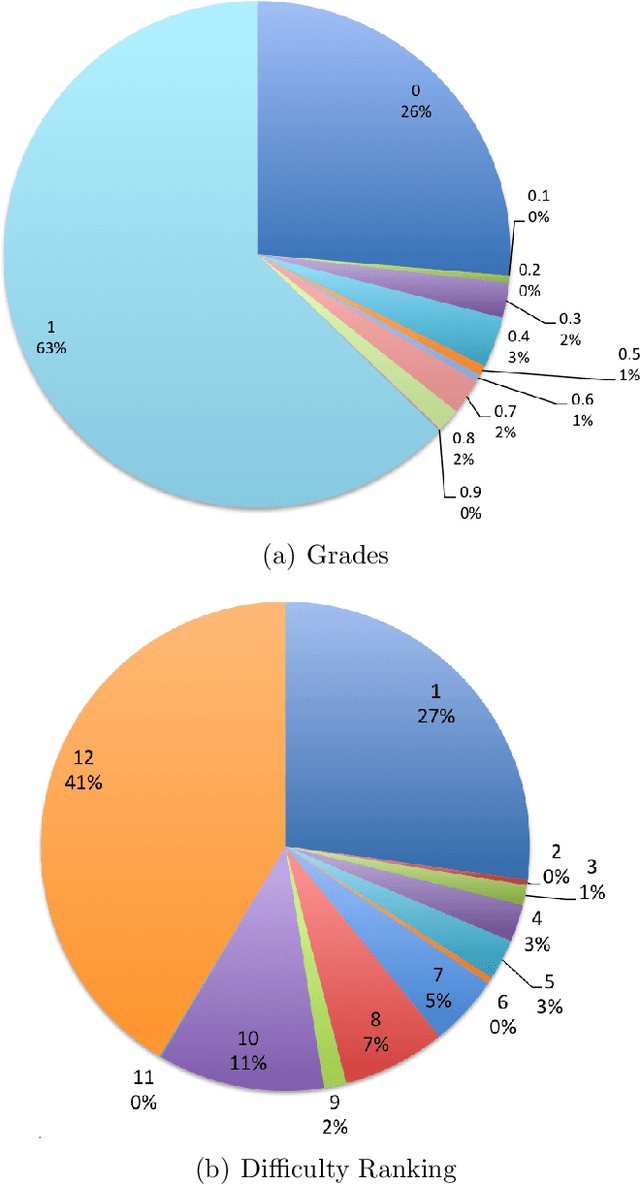

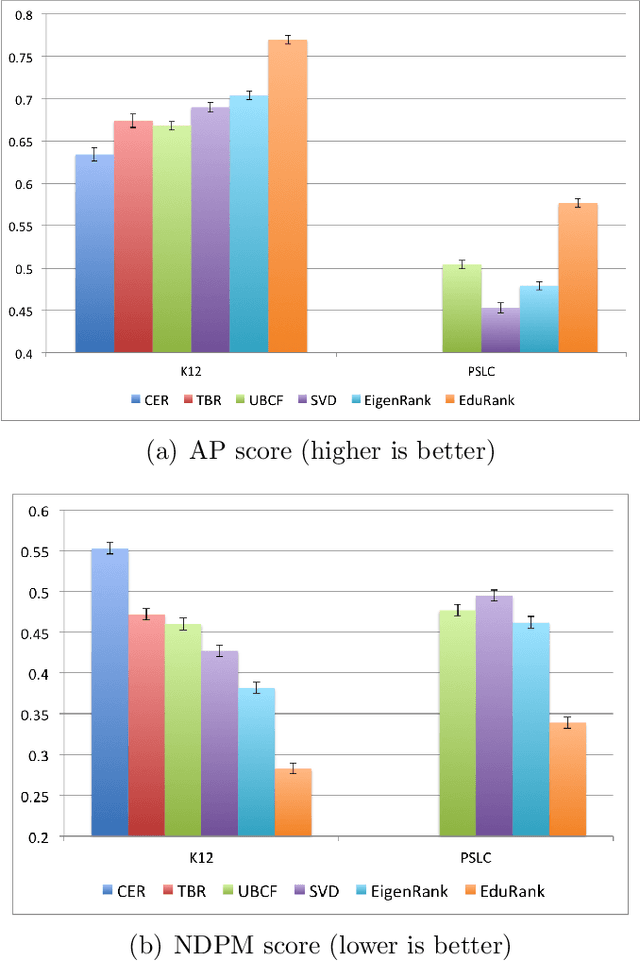
The prevalence of e-learning systems and on-line courses has made educational material widely accessible to students of varying abilities and backgrounds. There is thus a growing need to accommodate for individual differences in e-learning systems. This paper presents an algorithm called EduRank for personalizing educational content to students that combines a collaborative filtering algorithm with voting methods. EduRank constructs a difficulty ranking for each student by aggregating the rankings of similar students using different aspects of their performance on common questions. These aspects include grades, number of retries, and time spent solving questions. It infers a difficulty ranking directly over the questions for each student, rather than ordering them according to the student's predicted score. The EduRank algorithm was tested on two data sets containing thousands of students and a million records. It was able to outperform the state-of-the-art ranking approaches as well as a domain expert. EduRank was used by students in a classroom activity, where a prior model was incorporated to predict the difficulty rankings of students with no prior history in the system. It was shown to lead students to solve more difficult questions than an ordering by a domain expert, without reducing their performance.
Combining Difficulty Ranking with Multi-Armed Bandits to Sequence Educational Content
Apr 14, 2018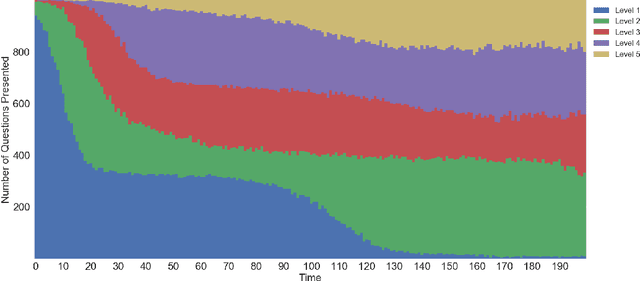

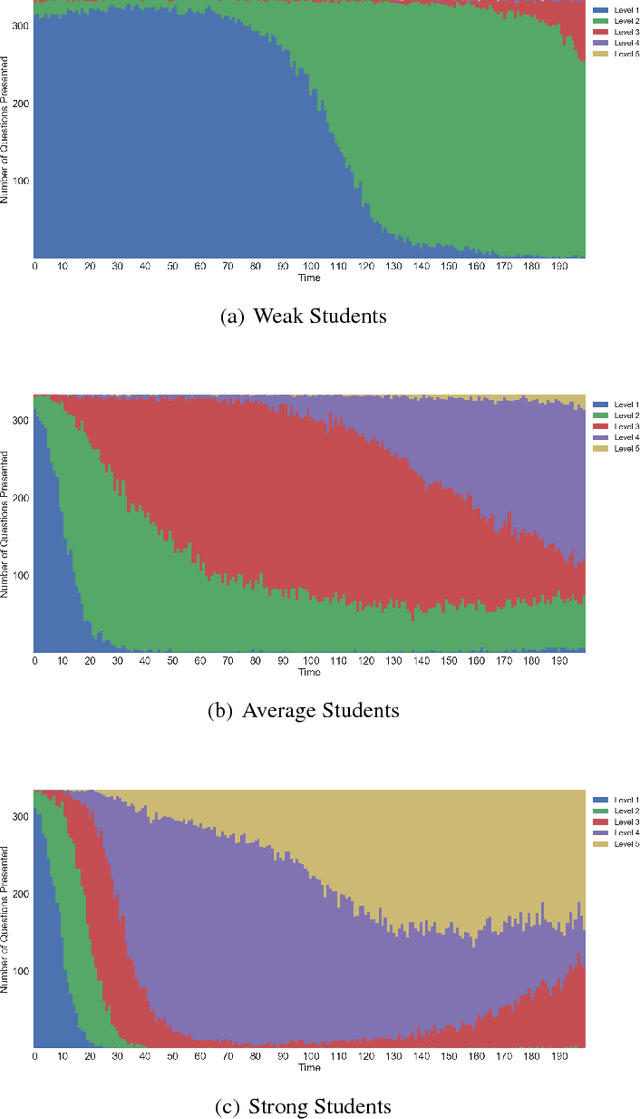
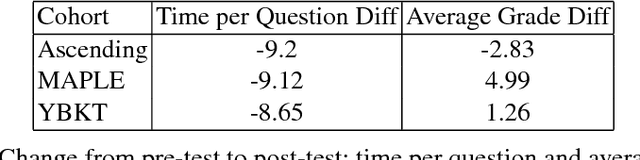
As e-learning systems become more prevalent, there is a growing need for them to accommodate individual differences between students. This paper addresses the problem of how to personalize educational content to students in order to maximize their learning gains over time. We present a new computational approach to this problem called MAPLE (Multi-Armed Bandits based Personalization for Learning Environments) that combines difficulty ranking with multi-armed bandits. Given a set of target questions MAPLE estimates the expected learning gains for each question and uses an exploration-exploitation strategy to choose the next question to pose to the student. It maintains a personalized ranking over the difficulties of question in the target set which is used in two ways: First, to obtain initial estimates over the learning gains for the set of questions. Second, to update the estimates over time based on the students responses. We show in simulations that MAPLE was able to improve students' learning gains compared to approaches that sequence questions in increasing level of difficulty, or rely on content experts. When implemented in a live e-learning system in the wild, MAPLE showed promising results. This work demonstrates the efficacy of using stochastic approaches to the sequencing problem when augmented with information about question difficulty.