 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristics for Partially Observable Stochastic Contingent Planning
Oct 08, 2024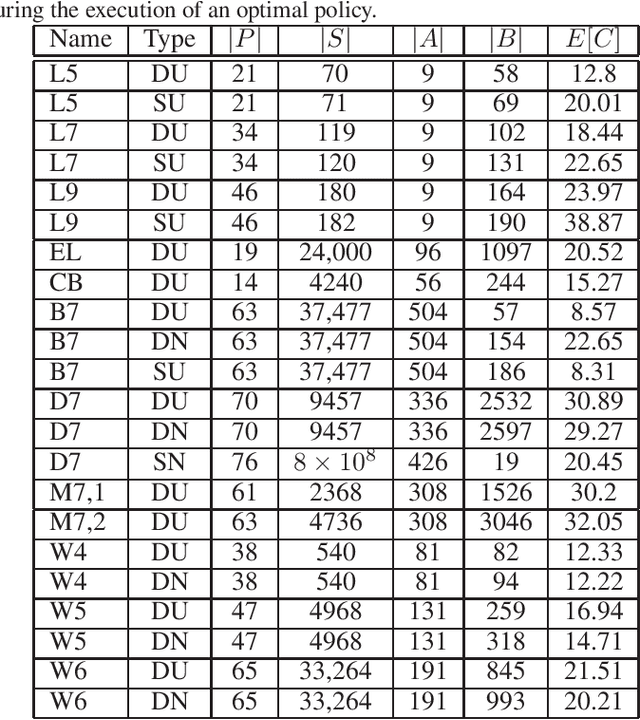
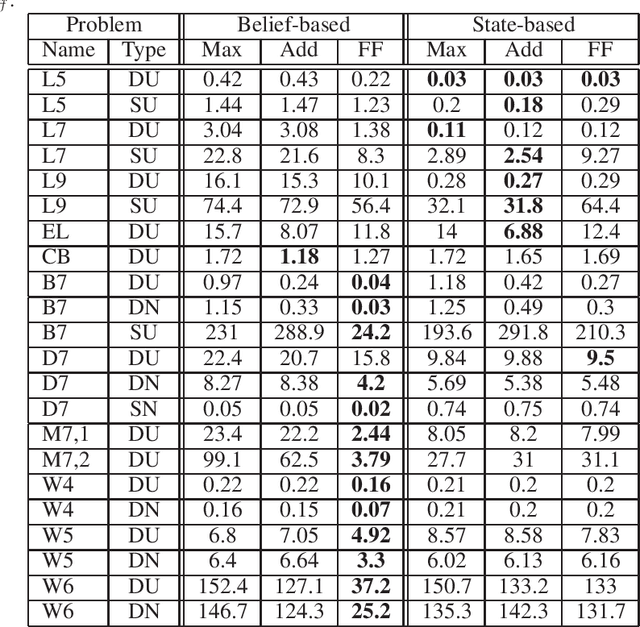
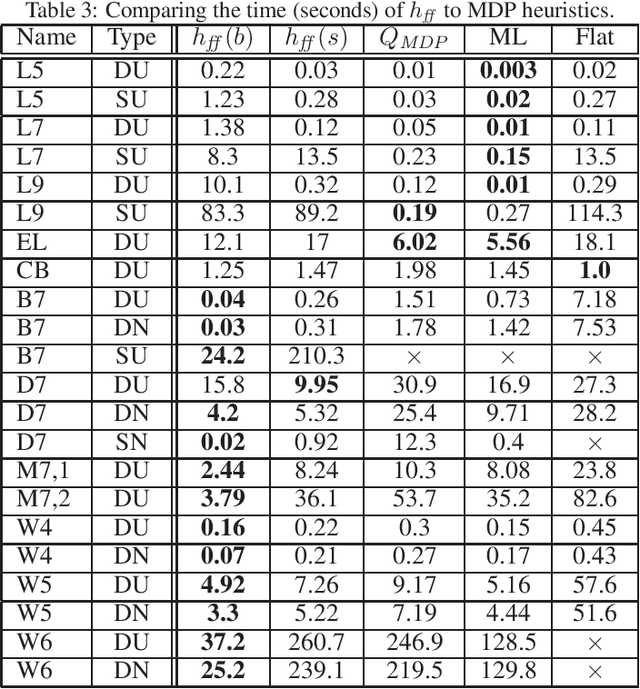
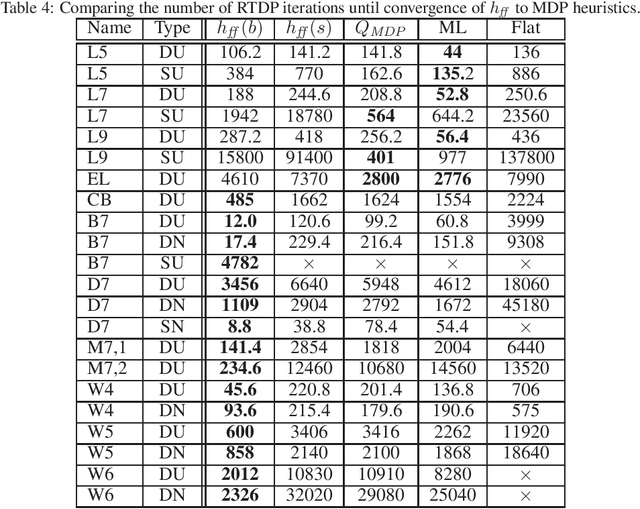
Acting to complete tasks in stochastic partially observable domains is an important problem in artificial intelligence, and is often formulated as a goal-based POMDP. Goal-based POMDPs can be solved using the RTDP-BEL algorithm, that operates by running forward trajectories from the initial belief to the goal. These trajectories can be guided by a heuristic, and more accurate heuristics can result in significantly faster convergence. In this paper, we develop a heuristic function that leverages the structured representation of domain models. We compute, in a relaxed space, a plan to achieve the goal, while taking into account the value of information, as well as the stochastic effects. We provide experiments showing that while our heuristic is slower to compute, it requires an order of magnitude less trajectories before convergence. Overall, it thus speeds up RTDP-BEL, particularly in problems where significant information gathering is needed.
Rollout Heuristics for Online Stochastic Contingent Planning
Oct 03, 2023Partially observable Markov decision processes (POMDP) are a useful model for decision-making under partial observability and stochastic actions. Partially Observable Monte-Carlo Planning is an online algorithm for deciding on the next action to perform, using a Monte-Carlo tree search approach, based on the UCT (UCB applied to trees) algorithm for fully observable Markov-decision processes. POMCP develops an action-observation tree, and at the leaves, uses a rollout policy to provide a value estimate for the leaf. As such, POMCP is highly dependent on the rollout policy to compute good estimates, and hence identify good actions. Thus, many practitioners who use POMCP are required to create strong, domain-specific heuristics. In this paper, we model POMDPs as stochastic contingent planning problems. This allows us to leverage domain-independent heuristics that were developed in the planning community. We suggest two heuristics, the first is based on the well-known h_add heuristic from classical planning, and the second is computed in belief space, taking the value of information into account.
* In Proceedings AREA 2023, arXiv:2310.00333
Dyadic Reinforcement Learning
Aug 27, 2023Mobile health aims to enhance health outcomes by delivering interventions to individuals as they go about their daily life. The involvement of care partners and social support networks often proves crucial in helping individuals managing burdensome medical conditions. This presents opportunities in mobile health to design interventions that target the dyadic relationship -- the relationship between a target person and their care partner -- with the aim of enhancing social support. In this paper, we develop dyadic RL, an online reinforcement learning algorithm designed to personalize intervention delivery based on contextual factors and past responses of a target person and their care partner. Here, multiple sets of interventions impact the dyad across multiple time intervals. The developed dyadic RL is Bayesian and hierarchical. We formally introduce the problem setup, develop dyadic RL and establish a regret bound. We demonstrate dyadic RL's empirical performance through simulation studies on both toy scenarios and on a realistic test bed constructed from data collected in a mobile health study.
Patient-level Microsatellite Stability Assessment from Whole Slide Images By Combining Momentum Contrast Learning and Group Patch Embeddings
Aug 22, 2022
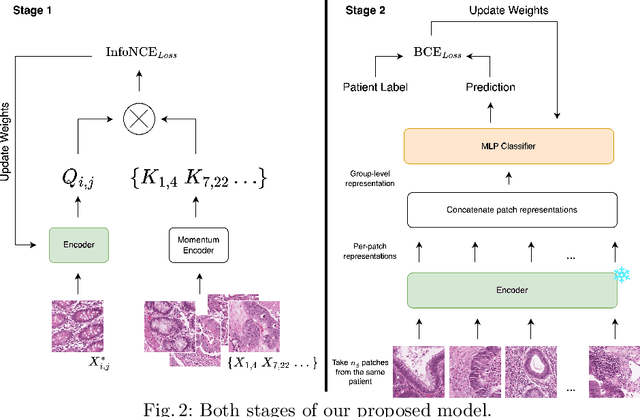
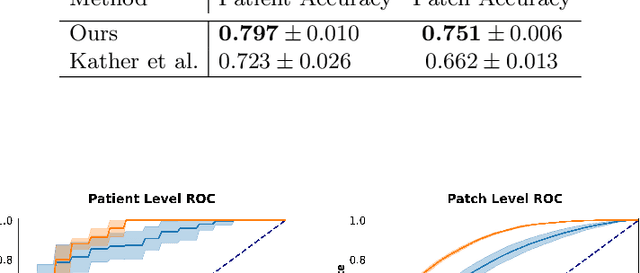
Assessing microsatellite stability status of a patient's colorectal cancer is crucial in personalizing treatment regime. Recently, convolutional-neural-networks (CNN) combined with transfer-learning approaches were proposed to circumvent traditional laboratory testing for determining microsatellite status from hematoxylin and eosin stained biopsy whole slide images (WSI). However, the high resolution of WSI practically prevent direct classification of the entire WSI. Current approaches bypass the WSI high resolution by first classifying small patches extracted from the WSI, and then aggregating patch-level classification logits to deduce the patient-level status. Such approaches limit the capacity to capture important information which resides at the high resolution WSI data. We introduce an effective approach to leverage WSI high resolution information by momentum contrastive learning of patch embeddings along with training a patient-level classifier on groups of those embeddings. Our approach achieves up to 7.4\% better accuracy compared to the straightforward patch-level classification and patient level aggregation approach with a higher stability (AUC, $0.91 \pm 0.01$ vs. $0.85 \pm 0.04$, p-value$<0.01$). Our code can be found at https://github.com/TechnionComputationalMRILab/colorectal_cancer_ai.
Partial Disclosure of Private Dependencies in Privacy Preserving Planning
Feb 14, 2021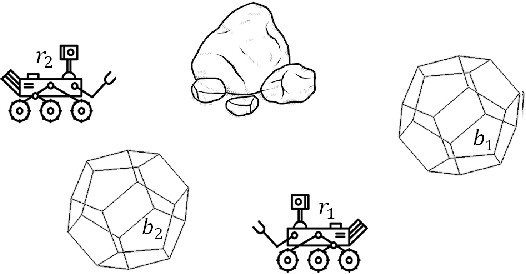

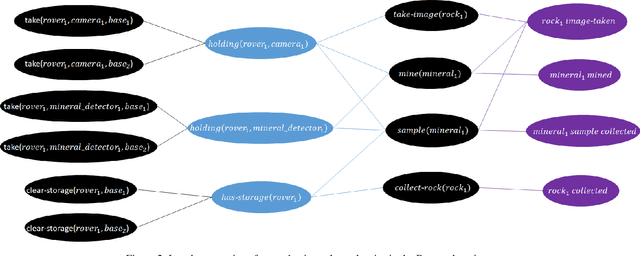
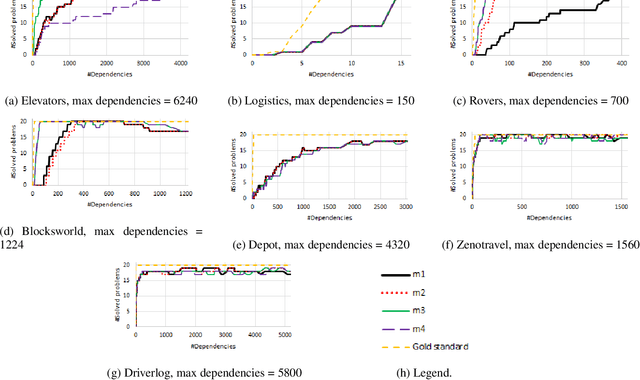
In collaborative privacy preserving planning (CPPP), a group of agents jointly creates a plan to achieve a set of goals while preserving each others' privacy. During planning, agents often reveal the private dependencies between their public actions to other agents, that is, which public action facilitates the preconditions of another public action. Previous work in CPPP does not limit the disclosure of such dependencies. In this paper, we explicitly limit the amount of disclosed dependencies, allowing agents to publish only a part of their private dependencies. We investigate different strategies for deciding which dependencies to publish, and how they affect the ability to find solutions. We evaluate the ability of two solvers -- distribute forward search and centralized planning based on a single-agent projection -- to produce plans under this constraint. Experiments over standard CPPP domains show that the proposed dependency-sharing strategies enable generating plans while sharing only a small fraction of all private dependencies.
A difficulty ranking approach to personalization in E-learning
Jul 28, 2019
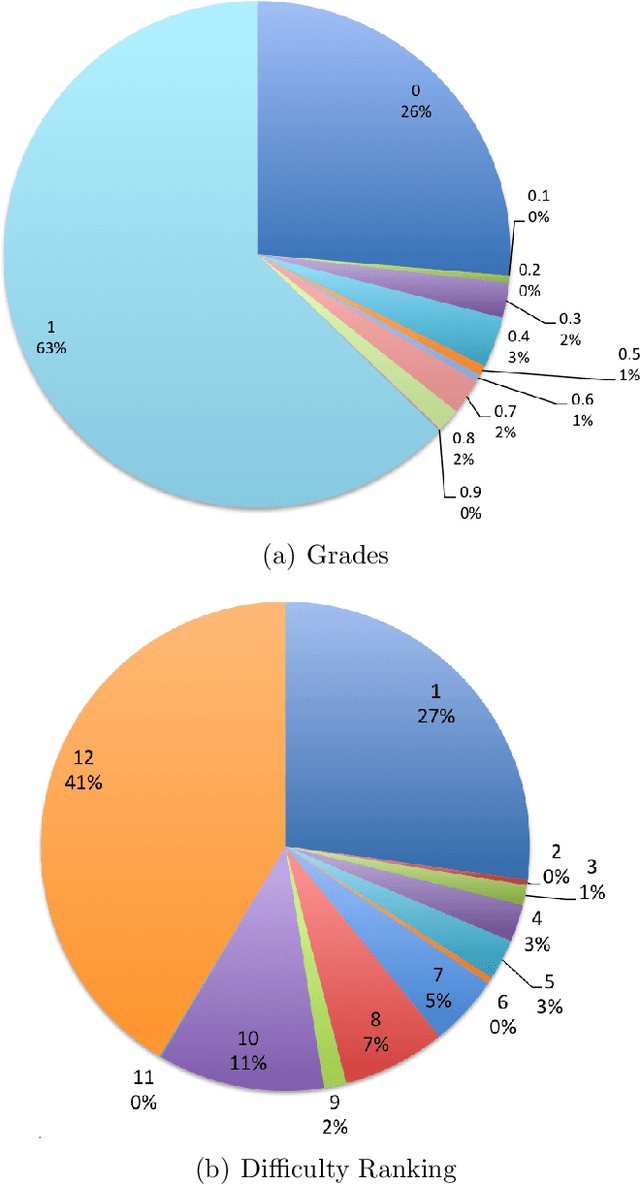

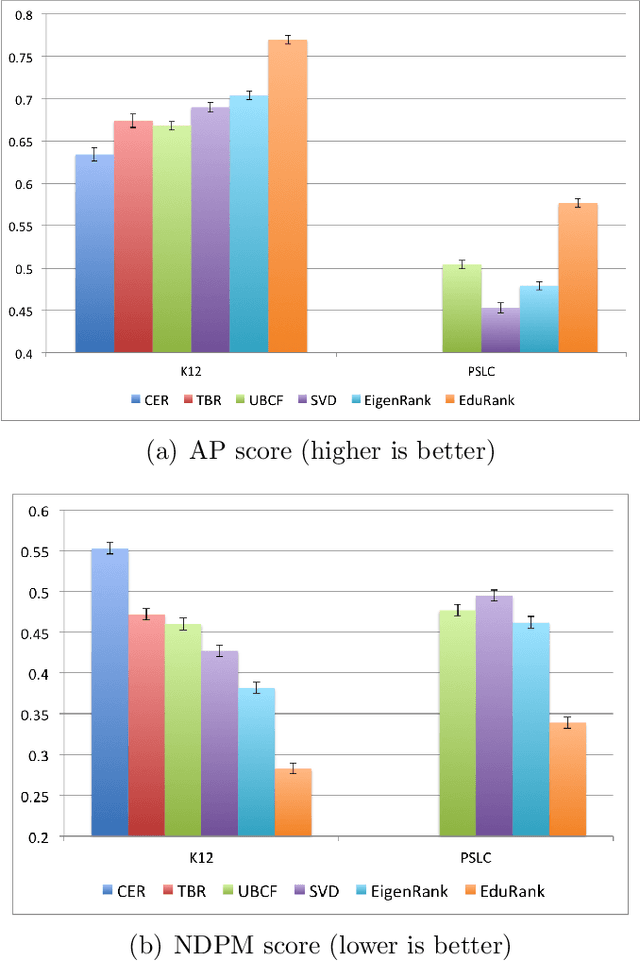
The prevalence of e-learning systems and on-line courses has made educational material widely accessible to students of varying abilities and backgrounds. There is thus a growing need to accommodate for individual differences in e-learning systems. This paper presents an algorithm called EduRank for personalizing educational content to students that combines a collaborative filtering algorithm with voting methods. EduRank constructs a difficulty ranking for each student by aggregating the rankings of similar students using different aspects of their performance on common questions. These aspects include grades, number of retries, and time spent solving questions. It infers a difficulty ranking directly over the questions for each student, rather than ordering them according to the student's predicted score. The EduRank algorithm was tested on two data sets containing thousands of students and a million records. It was able to outperform the state-of-the-art ranking approaches as well as a domain expert. EduRank was used by students in a classroom activity, where a prior model was incorporated to predict the difficulty rankings of students with no prior history in the system. It was shown to lead students to solve more difficult questions than an ordering by a domain expert, without reducing their performance.
An MDP-based Recommender System
May 16, 2015
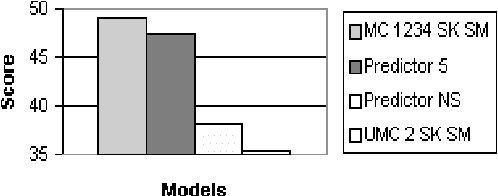

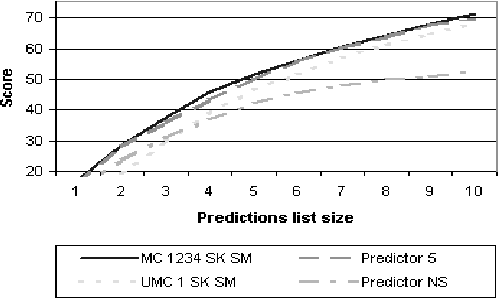
Typical Recommender systems adopt a static view of the recommendation process and treat it as a prediction problem. We argue that it is more appropriate to view the problem of generating recommendations as a sequential decision problem and, consequently, that Markov decision processes (MDP) provide a more appropriate model for Recommender systems. MDPs introduce two benefits: they take into account the long-term effects of each recommendation, and they take into account the expected value of each recommendation. To succeed in practice, an MDP-based Recommender system must employ a strong initial model; and the bulk of this paper is concerned with the generation of such a model. In particular, we suggest the use of an n-gram predictive model for generating the initial MDP. Our n-gram model induces a Markov-chain model of user behavior whose predictive accuracy is greater than that of existing predictive models. We describe our predictive model in detail and evaluate its performance on real data. In addition, we show how the model can be used in an MDP-based Recommender system.
Replanning in Domains with Partial Information and Sensing Actions
Jan 23, 2014


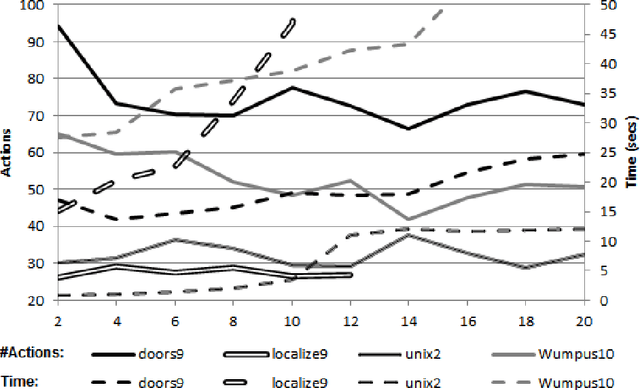
Replanning via determinization is a recent, popular approach for online planning in MDPs. In this paper we adapt this idea to classical, non-stochastic domains with partial information and sensing actions, presenting a new planner: SDR (Sample, Determinize, Replan). At each step we generate a solution plan to a classical planning problem induced by the original problem. We execute this plan as long as it is safe to do so. When this is no longer the case, we replan. The classical planning problem we generate is based on the translation-based approach for conformant planning introduced by Palacios and Geffner. The state of the classical planning problem generated in this approach captures the belief state of the agent in the original problem. Unfortunately, when this method is applied to planning problems with sensing, it yields a non-deterministic planning problem that is typically very large. Our main contribution is the introduction of state sampling techniques for overcoming these two problems. In addition, we introduce a novel, lazy, regression-based method for querying the agents belief state during run-time. We provide a comprehensive experimental evaluation of the planner, showing that it scales better than the state-of-the-art CLG planner on existing benchmark problems, but also highlighting its weaknesses with new domains. We also discuss its theoretical guarantees.
Using Wikipedia to Boost SVD Recommender Systems
Dec 05, 2012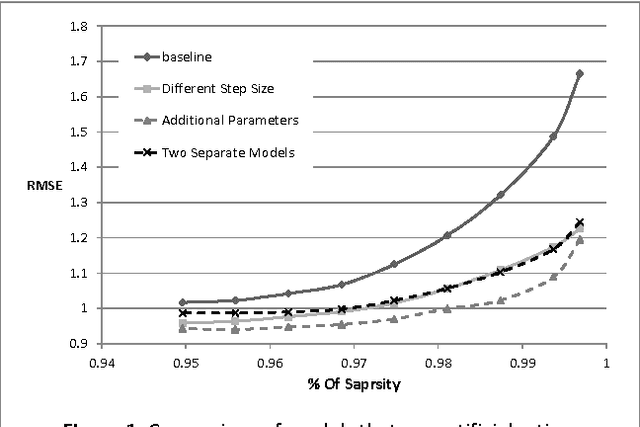

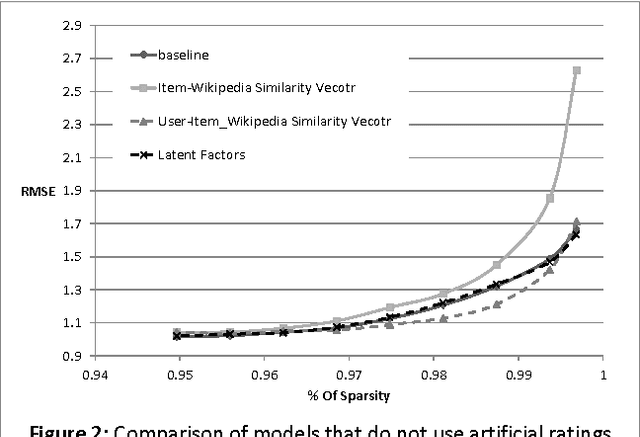

Singular Value Decomposition (SVD) has been used successfully in recent years in the area of recommender systems. In this paper we present how this model can be extended to consider both user ratings and information from Wikipedia. By mapping items to Wikipedia pages and quantifying their similarity, we are able to use this information in order to improve recommendation accuracy, especially when the sparsity is high. Another advantage of the proposed approach is the fact that it can be easily integrated into any other SVD implementation, regardless of additional parameters that may have been added to it. Preliminary experimental results on the MovieLens dataset are encouraging.
Boosting Simple Collaborative Filtering Models Using Ensemble Methods
Nov 13, 2012
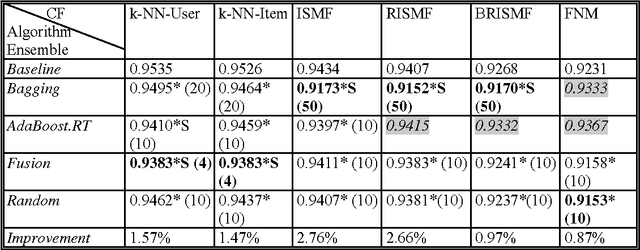

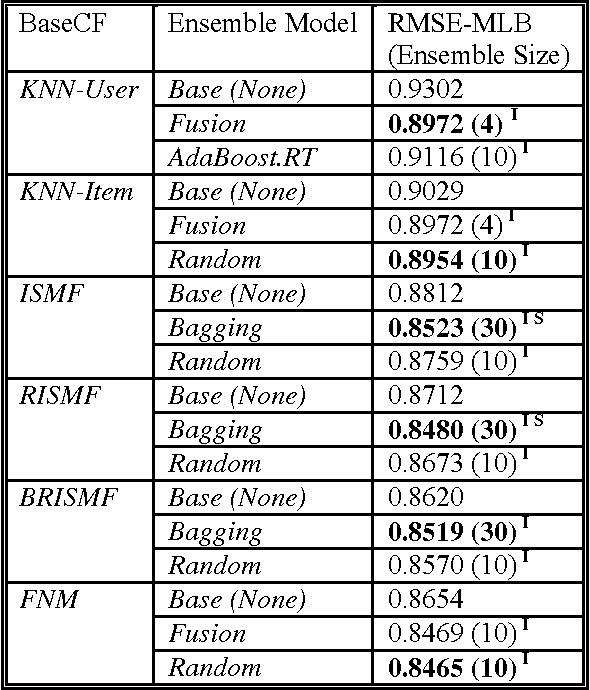
In this paper we examine the effect of applying ensemble learning to the performance of collaborative filtering methods. We present several systematic approaches for generating an ensemble of collaborative filtering models based on a single collaborative filtering algorithm (single-model or homogeneous ensemble). We present an adaptation of several popular ensemble techniques in machine learning for the collaborative filtering domain, including bagging, boosting, fusion and randomness injection. We evaluate the proposed approach on several types of collaborative filtering base models: k- NN, matrix factorization and a neighborhood matrix factorization model. Empirical evaluation shows a prediction improvement compared to all base CF algorithms. In particular, we show that the performance of an ensemble of simple (weak) CF models such as k-NN is competitive compared with a single strong CF model (such as matrix factorization) while requiring an order of magnitude less computational cost.