 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristics for Partially Observable Stochastic Contingent Planning
Paper and Code
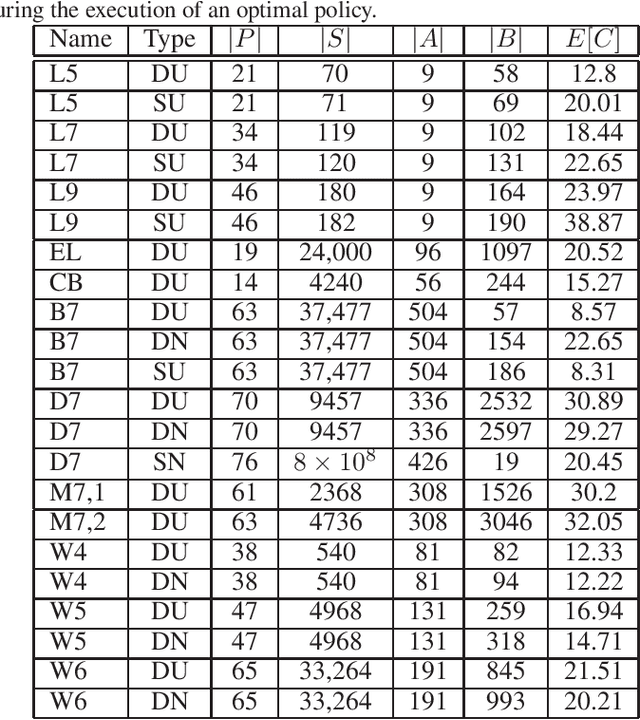
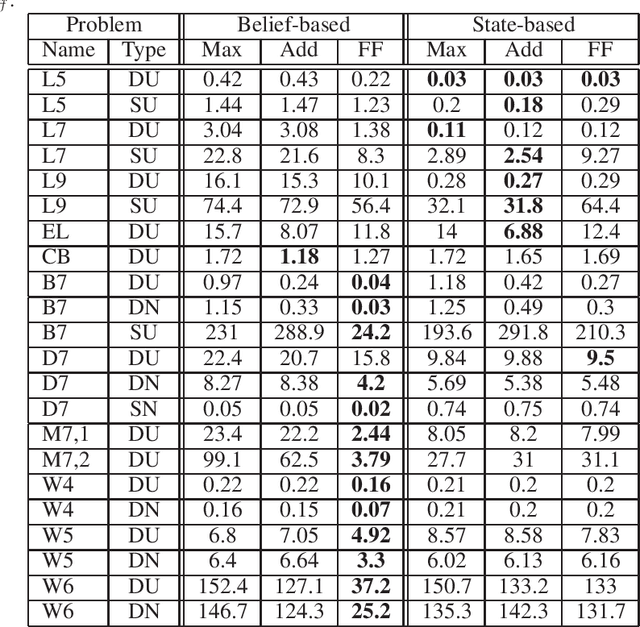
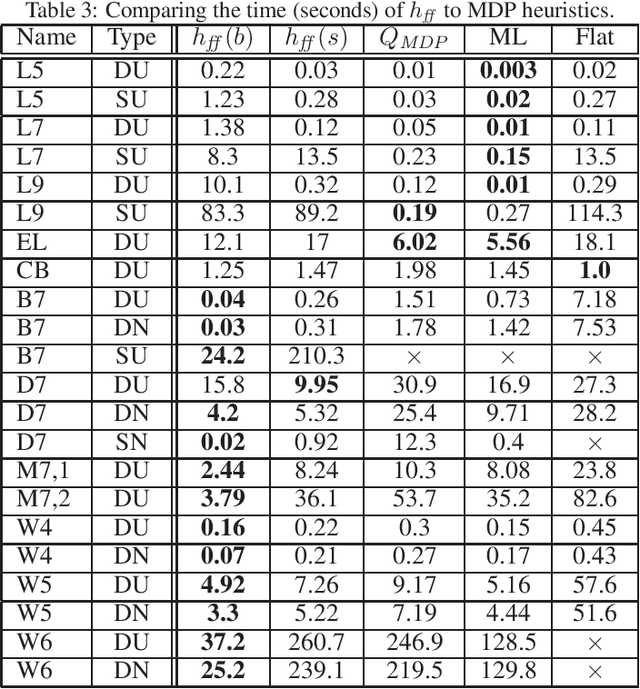
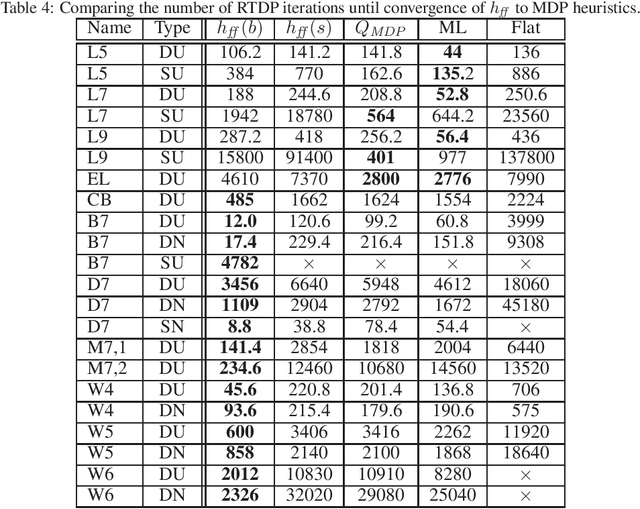
Acting to complete tasks in stochastic partially observable domains is an important problem in artificial intelligence, and is often formulated as a goal-based POMDP. Goal-based POMDPs can be solved using the RTDP-BEL algorithm, that operates by running forward trajectories from the initial belief to the goal. These trajectories can be guided by a heuristic, and more accurate heuristics can result in significantly faster convergence. In this paper, we develop a heuristic function that leverages the structured representation of domain models. We compute, in a relaxed space, a plan to achieve the goal, while taking into account the value of information, as well as the stochastic effects. We provide experiments showing that while our heuristic is slower to compute, it requires an order of magnitude less trajectories before convergence. Overall, it thus speeds up RTDP-BEL, particularly in problems where significant information gathering is needed.