 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Methods for Multi-label Classification
Jul 06, 2013
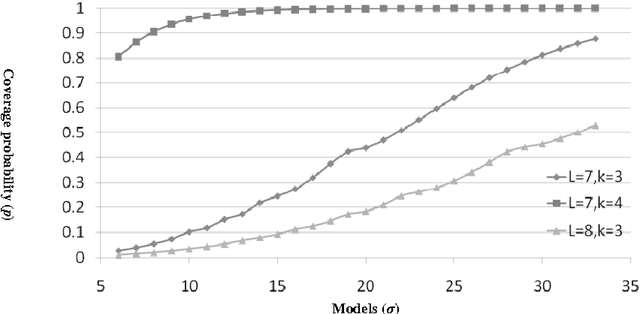
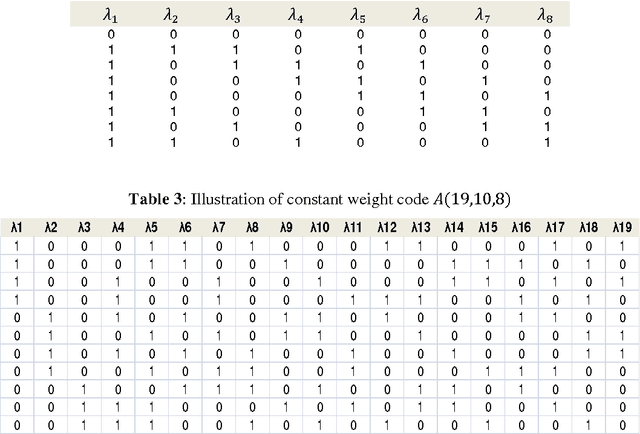

Ensemble methods have been shown to be an effective tool for solving multi-label classification tasks. In the RAndom k-labELsets (RAKEL) algorithm, each member of the ensemble is associated with a small randomly-selected subset of k labels. Then, a single label classifier is trained according to each combination of elements in the subset. In this paper we adopt a similar approach, however, instead of randomly choosing subsets, we select the minimum required subsets of k labels that cover all labels and meet additional constraints such as coverage of inter-label correlations. Construction of the cover is achieved by formulating the subset selection as a minimum set covering problem (SCP) and solving it by using approximation algorithms. Every cover needs only to be prepared once by offline algorithms. Once prepared, a cover may be applied to the classification of any given multi-label dataset whose properties conform with those of the cover. The contribution of this paper is two-fold. First, we introduce SCP as a general framework for constructing label covers while allowing the user to incorporate cover construction constraints. We demonstrate the effectiveness of this framework by proposing two construction constraints whose enforcement produces covers that improve the prediction performance of random selection. Second, we provide theoretical bounds that quantify the probabilities of random selection to produce covers that meet the proposed construction criteria. The experimental results indicate that the proposed methods improve multi-label classification accuracy and stability compared with the RAKEL algorithm and to other state-of-the-art algorithms.
Securing Your Transactions: Detecting Anomalous Patterns In XML Documents
Jun 05, 2013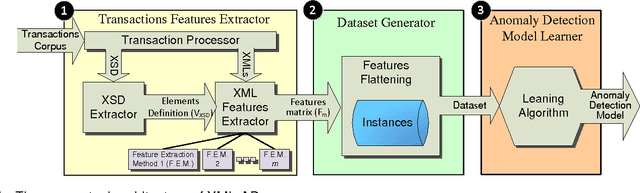
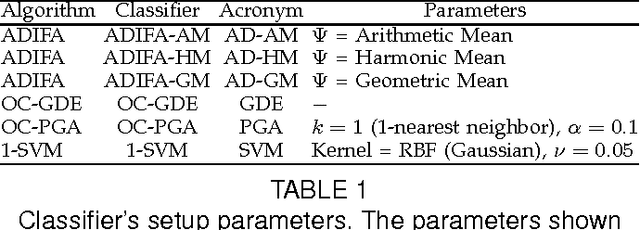

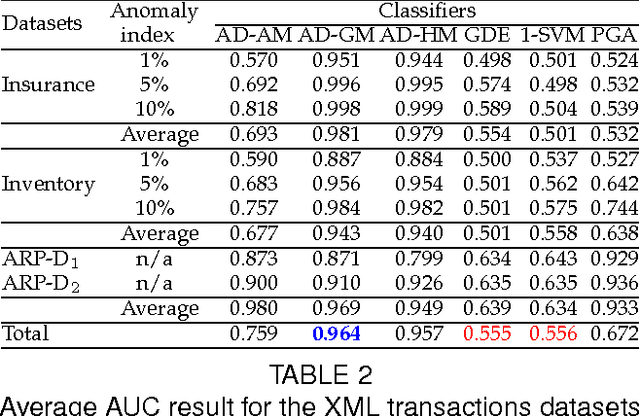
XML transactions are used in many information systems to store data and interact with other systems. Abnormal transactions, the result of either an on-going cyber attack or the actions of a benign user, can potentially harm the interacting systems and therefore they are regarded as a threat. In this paper we address the problem of anomaly detection and localization in XML transactions using machine learning techniques. We present a new XML anomaly detection framework, XML-AD. Within this framework, an automatic method for extracting features from XML transactions was developed as well as a practical method for transforming XML features into vectors of fixed dimensionality. With these two methods in place, the XML-AD framework makes it possible to utilize general learning algorithms for anomaly detection. Central to the functioning of the framework is a novel multi-univariate anomaly detection algorithm, ADIFA. The framework was evaluated on four XML transactions datasets, captured from real information systems, in which it achieved over 89% true positive detection rate with less than a 0.2% false positive rate.
Ensembles of Classifiers based on Dimensionality Reduction
May 19, 2013
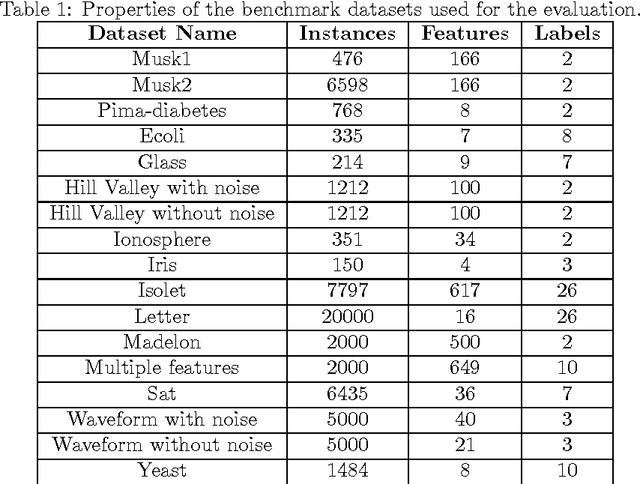
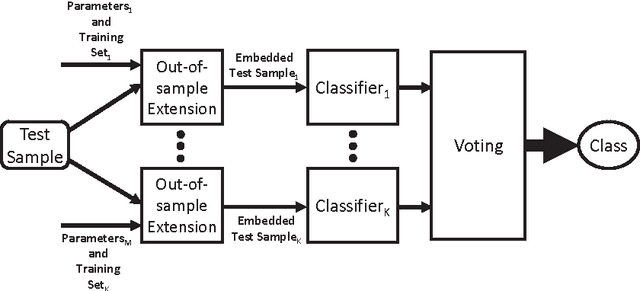
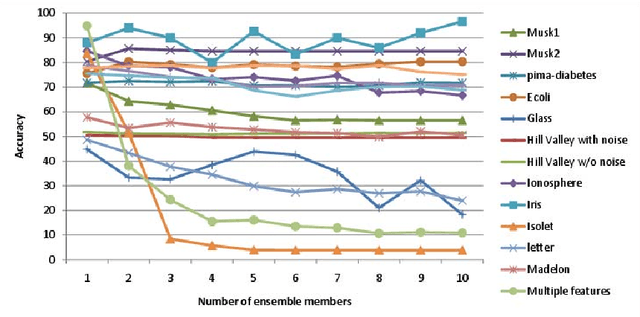
We present a novel approach for the construction of ensemble classifiers based on dimensionality reduction. Dimensionality reduction methods represent datasets using a small number of attributes while preserving the information conveyed by the original dataset. The ensemble members are trained based on dimension-reduced versions of the training set. These versions are obtained by applying dimensionality reduction to the original training set using different values of the input parameters. This construction meets both the diversity and accuracy criteria which are required to construct an ensemble classifier where the former criterion is obtained by the various input parameter values and the latter is achieved due to the decorrelation and noise reduction properties of dimensionality reduction. In order to classify a test sample, it is first embedded into the dimension reduced space of each individual classifier by using an out-of-sample extension algorithm. Each classifier is then applied to the embedded sample and the classification is obtained via a voting scheme. We present three variations of the proposed approach based on the Random Projections, the Diffusion Maps and the Random Subspaces dimensionality reduction algorithms. We also present a multi-strategy ensemble which combines AdaBoost and Diffusion Maps. A comparison is made with the Bagging, AdaBoost, Rotation Forest ensemble classifiers and also with the base classifier which does not incorporate dimensionality reduction. Our experiments used seventeen benchmark datasets from the UCI repository. The results obtained by the proposed algorithms were superior in many cases to other algorithms.
Video Segmentation via Diffusion Bases
May 01, 2013


Identifying moving objects in a video sequence, which is produced by a static camera, is a fundamental and critical task in many computer-vision applications. A common approach performs background subtraction, which identifies moving objects as the portion of a video frame that differs significantly from a background model. A good background subtraction algorithm has to be robust to changes in the illumination and it should avoid detecting non-stationary background objects such as moving leaves, rain, snow, and shadows. In addition, the internal background model should quickly respond to changes in background such as objects that start to move or stop. We present a new algorithm for video segmentation that processes the input video sequence as a 3D matrix where the third axis is the time domain. Our approach identifies the background by reducing the input dimension using the \emph{diffusion bases} methodology. Furthermore, we describe an iterative method for extracting and deleting the background. The algorithm has two versions and thus covers the complete range of backgrounds: one for scenes with static backgrounds and the other for scenes with dynamic (moving) backgrounds.
Boosting Simple Collaborative Filtering Models Using Ensemble Methods
Nov 13, 2012
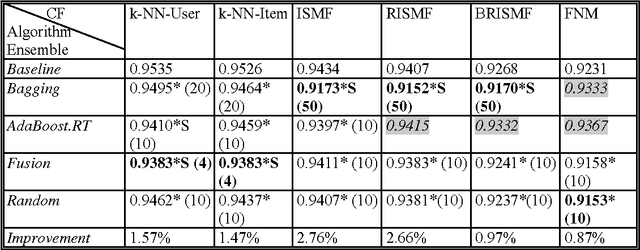

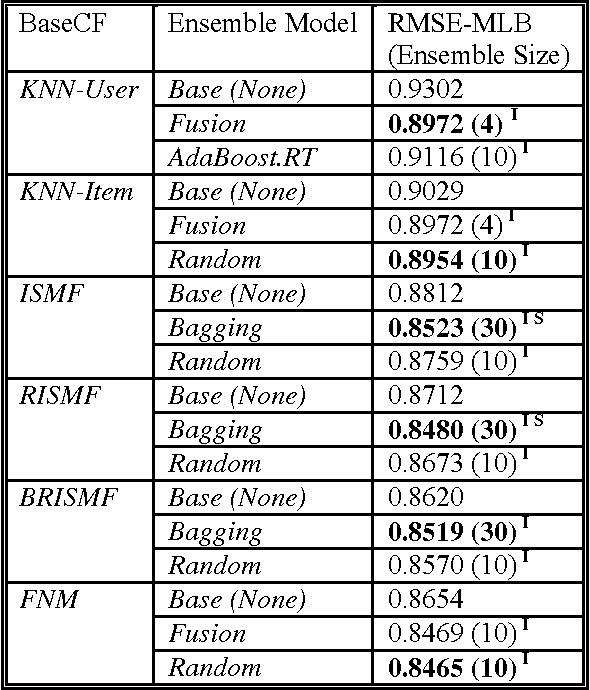
In this paper we examine the effect of applying ensemble learning to the performance of collaborative filtering methods. We present several systematic approaches for generating an ensemble of collaborative filtering models based on a single collaborative filtering algorithm (single-model or homogeneous ensemble). We present an adaptation of several popular ensemble techniques in machine learning for the collaborative filtering domain, including bagging, boosting, fusion and randomness injection. We evaluate the proposed approach on several types of collaborative filtering base models: k- NN, matrix factorization and a neighborhood matrix factorization model. Empirical evaluation shows a prediction improvement compared to all base CF algorithms. In particular, we show that the performance of an ensemble of simple (weak) CF models such as k-NN is competitive compared with a single strong CF model (such as matrix factorization) while requiring an order of magnitude less computational cost.
Multi-Sensor Fusion via Reduction of Dimensionality
Nov 13, 2012

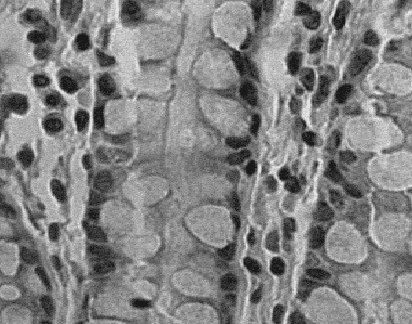
Large high-dimensional datasets are becoming more and more popular in an increasing number of research areas. Processing the high dimensional data incurs a high computational cost and is inherently inefficient since many of the values that describe a data object are redundant due to noise and inner correlations. Consequently, the dimensionality, i.e. the number of values that are used to describe a data object, needs to be reduced prior to any other processing of the data. The dimensionality reduction removes, in most cases, noise from the data and reduces substantially the computational cost of algorithms that are applied to the data. In this thesis, a novel coherent integrated methodology is introduced (theory, algorithm and applications) to reduce the dimensionality of high-dimensional datasets. The method constructs a diffusion process among the data coordinates via a random walk. The dimensionality reduction is obtained based on the eigen-decomposition of the Markov matrix that is associated with the random walk. The proposed method is utilized for: (a) segmentation and detection of anomalies in hyper-spectral images; (b) segmentation of multi-contrast MRI images; and (c) segmentation of video sequences. We also present algorithms for: (a) the characterization of materials using their spectral signatures to enable their identification; (b) detection of vehicles according to their acoustic signatures; and (c) classification of vascular vessels recordings to detect hyper-tension and cardio-vascular diseases. The proposed methodology and algorithms produce excellent results that successfully compete with current state-of-the-art algorithms.