 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining One-Class Classifiers via Meta-Learning
Jul 21, 2013
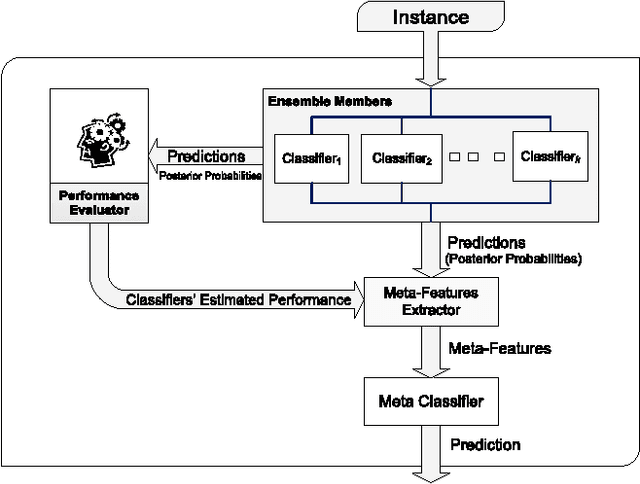
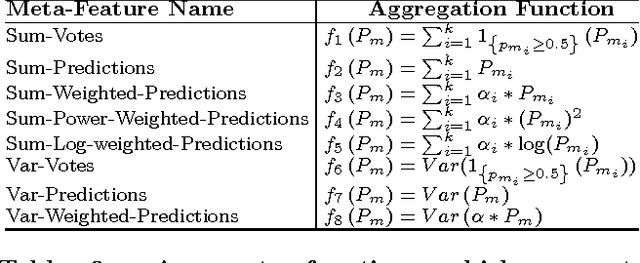
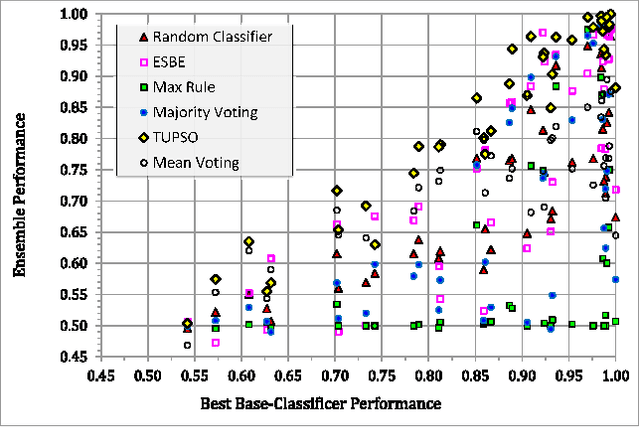
Selecting the best classifier among the available ones is a difficult task, especially when only instances of one class exist. In this work we examine the notion of combining one-class classifiers as an alternative for selecting the best classifier. In particular, we propose two new one-class classification performance measures to weigh classifiers and show that a simple ensemble that implements these measures can outperform the most popular one-class ensembles. Furthermore, we propose a new one-class ensemble scheme, TUPSO, which uses meta-learning to combine one-class classifiers. Our experiments demonstrate the superiority of TUPSO over all other tested ensembles and show that the TUPSO performance is statistically indistinguishable from that of the hypothetical best classifier.
Securing Your Transactions: Detecting Anomalous Patterns In XML Documents
Jun 05, 2013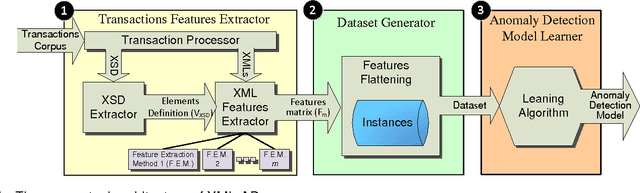
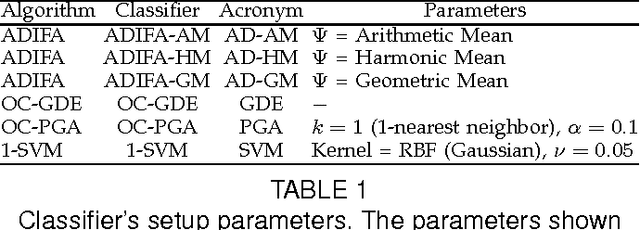

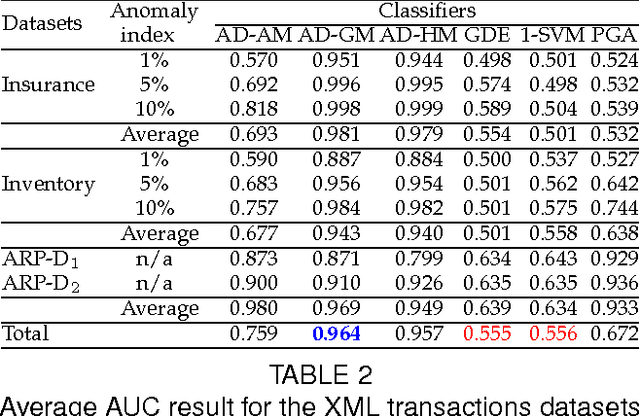
XML transactions are used in many information systems to store data and interact with other systems. Abnormal transactions, the result of either an on-going cyber attack or the actions of a benign user, can potentially harm the interacting systems and therefore they are regarded as a threat. In this paper we address the problem of anomaly detection and localization in XML transactions using machine learning techniques. We present a new XML anomaly detection framework, XML-AD. Within this framework, an automatic method for extracting features from XML transactions was developed as well as a practical method for transforming XML features into vectors of fixed dimensionality. With these two methods in place, the XML-AD framework makes it possible to utilize general learning algorithms for anomaly detection. Central to the functioning of the framework is a novel multi-univariate anomaly detection algorithm, ADIFA. The framework was evaluated on four XML transactions datasets, captured from real information systems, in which it achieved over 89% true positive detection rate with less than a 0.2% false positive rate.
Detecting Spammers via Aggregated Historical Data Set
May 07, 2012
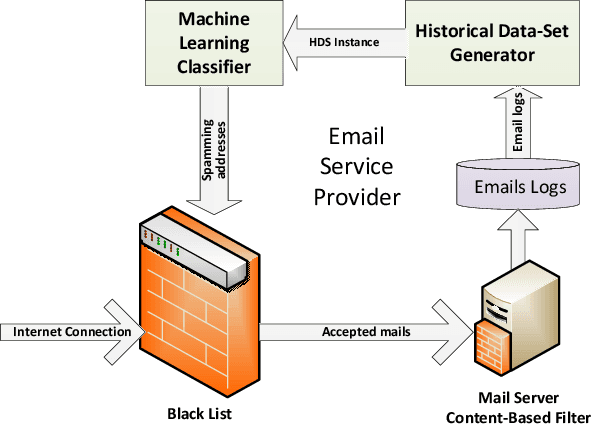
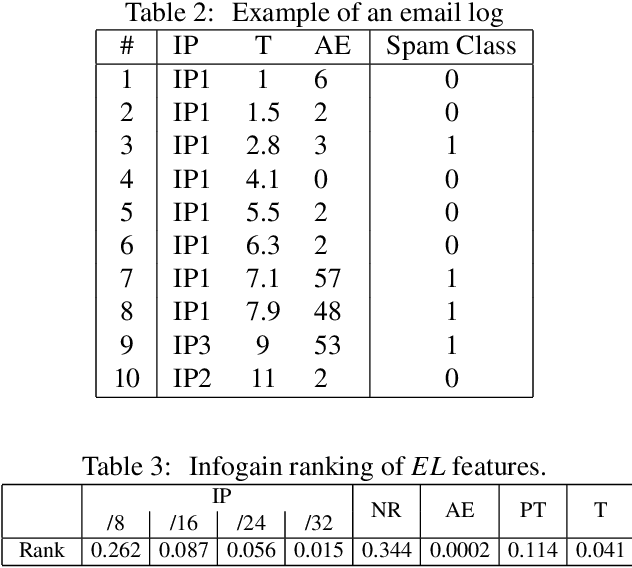
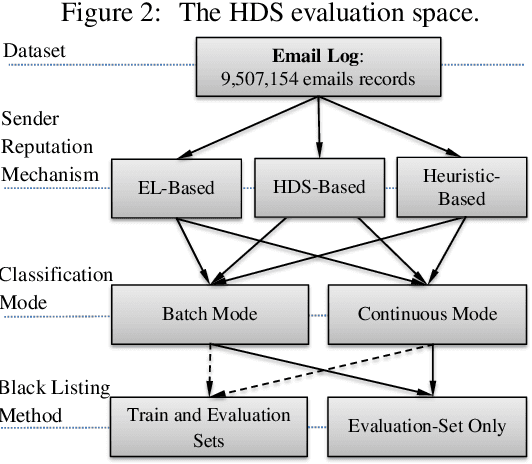
The battle between email service providers and senders of mass unsolicited emails (Spam) continues to gain traction. Vast numbers of Spam emails are sent mainly from automatic botnets distributed over the world. One method for mitigating Spam in a computationally efficient manner is fast and accurate blacklisting of the senders. In this work we propose a new sender reputation mechanism that is based on an aggregated historical data-set which encodes the behavior of mail transfer agents over time. A historical data-set is created from labeled logs of received emails. We use machine learning algorithms to build a model that predicts the \emph{spammingness} of mail transfer agents in the near future. The proposed mechanism is targeted mainly at large enterprises and email service providers and can be used for updating both the black and the white lists. We evaluate the proposed mechanism using 9.5M anonymized log entries obtained from the biggest Internet service provider in Europe. Experiments show that proposed method detects more than 94% of the Spam emails that escaped the blacklist (i.e., TPR), while having less than 0.5% false-alarms. Therefore, the effectiveness of the proposed method is much higher than of previously reported reputation mechanisms, which rely on emails logs. In addition, the proposed method, when used for updating both the black and white lists, eliminated the need in automatic content inspection of 4 out of 5 incoming emails, which resulted in dramatic reduction in the filtering computational load.