 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEL-CIE: Knowledge-Guided Self-Supervised Learning Framework for CIE-XYZ Reconstruction from Non-Linear sRGB Images
May 20, 2024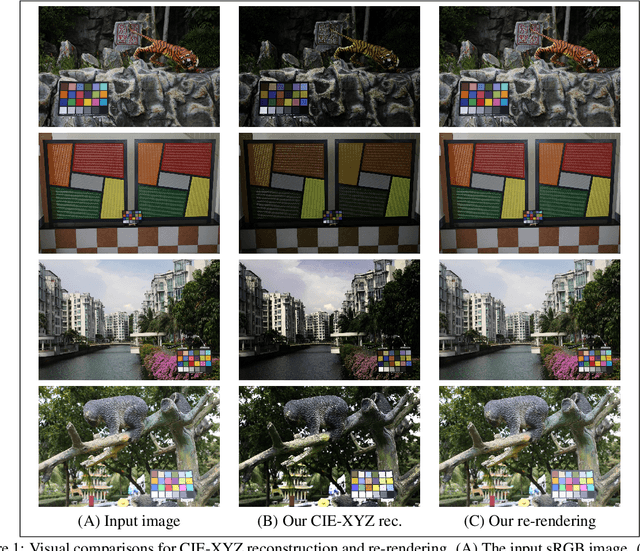


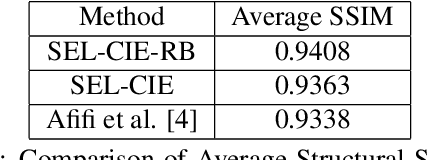
Modern cameras typically offer two types of image states: a minimally processed linear raw RGB image representing the raw sensor data, and a highly-processed non-linear image state, such as the sRGB state. The CIE-XYZ color space is a device-independent linear space used as part of the camera pipeline and can be helpful for computer vision tasks, such as image deblurring, dehazing, and color recognition tasks in medical applications, where color accuracy is important. However, images are usually saved in non-linear states, and achieving CIE-XYZ color images using conventional methods is not always possible. To tackle this issue, classical methodologies have been developed that focus on reversing the acquisition pipeline. More recently, supervised learning has been employed, using paired CIE-XYZ and sRGB representations of identical images. However, obtaining a large-scale dataset of CIE-XYZ and sRGB pairs can be challenging. To overcome this limitation and mitigate the reliance on large amounts of paired data, self-supervised learning (SSL) can be utilized as a substitute for relying solely on paired data. This paper proposes a framework for using SSL methods alongside paired data to reconstruct CIE-XYZ images and re-render sRGB images, outperforming existing approaches. The proposed framework is applied to the sRGB2XYZ dataset.
TabADM: Unsupervised Tabular Anomaly Detection with Diffusion Models
Jul 23, 2023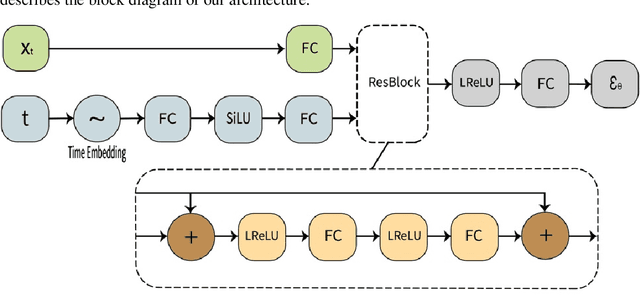
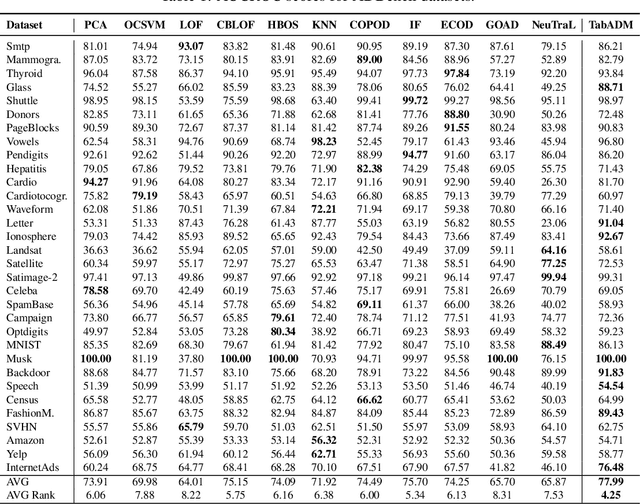
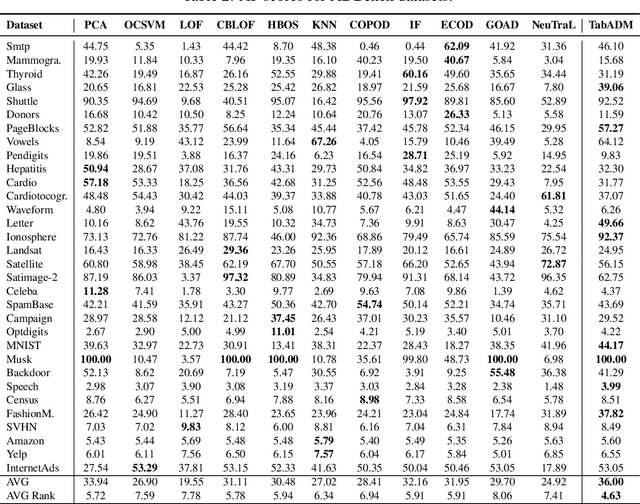
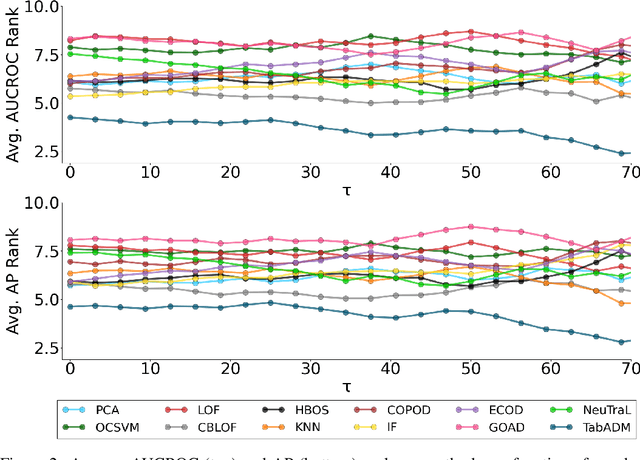
Tables are an abundant form of data with use cases across all scientific fields. Real-world datasets often contain anomalous samples that can negatively affect downstream analysis. In this work, we only assume access to contaminated data and present a diffusion-based probabilistic model effective for unsupervised anomaly detection. Our model is trained to learn the density of normal samples by utilizing a unique rejection scheme to attenuate the influence of anomalies on the density estimation. At inference, we identify anomalies as samples in low-density regions. We use real data to demonstrate that our method improves detection capabilities over baselines. Furthermore, our method is relatively stable to the dimension of the data and does not require extensive hyperparameter tuning.
Cross-boosting of WNNM Image Denoising method by Directional Wavelet Packets
Jun 09, 2022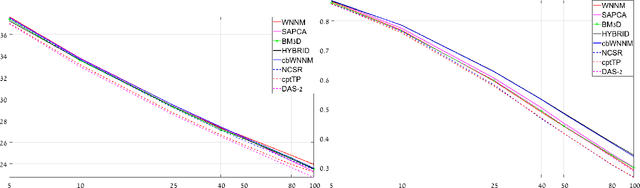
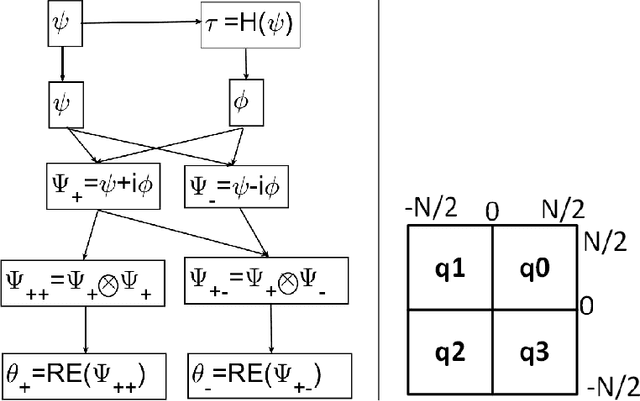
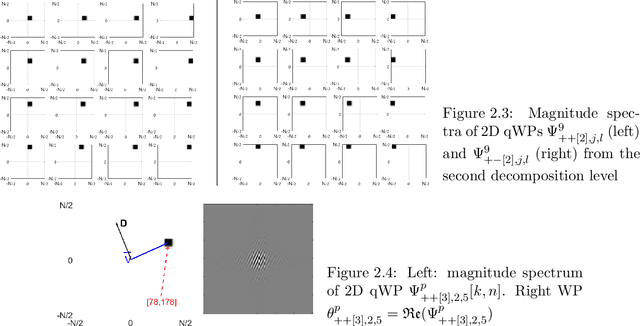
The paper presents an image denoising scheme by combining a method that is based on directional quasi-analytic wavelet packets (qWPs) with the state-of-the-art Weighted Nuclear Norm Minimization (WNNM) denoising algorithm. The qWP-based denoising method (qWPdn) consists of multiscale qWP transform of the degraded image, application of adaptive localized soft thresholding to the transform coefficients using the Bivariate Shrinkage methodology, and restoration of the image from the thresholded coefficients from several decomposition levels. The combined method consists of several iterations of qWPdn and WNNM algorithms in a way that at each iteration the output from one algorithm boosts the input to the other. The proposed methodology couples the qWPdn capabilities to capture edges and fine texture patterns even in the severely corrupted images with utilizing the non-local self-similarity in real images that is inherent in the WNNM algorithm. Multiple experiments, which compared the proposed methodology with six advanced denoising algorithms, including WNNM, confirmed that the combined cross-boosting algorithm outperforms most of them in terms of both quantitative measure and visual perception quality.
Imbalanced Classification via a Tabular Translation GAN
Apr 19, 2022
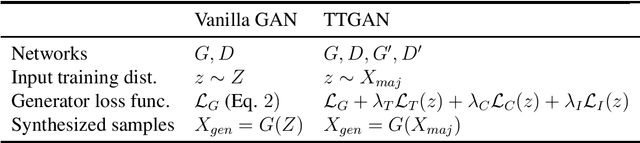

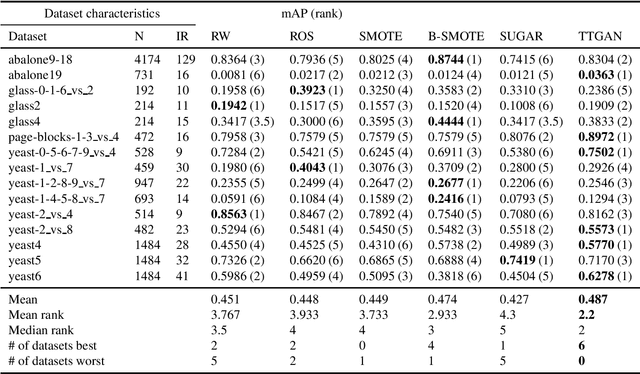
When presented with a binary classification problem where the data exhibits severe class imbalance, most standard predictive methods may fail to accurately model the minority class. We present a model based on Generative Adversarial Networks which uses additional regularization losses to map majority samples to corresponding synthetic minority samples. This translation mechanism encourages the synthesized samples to be close to the class boundary. Furthermore, we explore a selection criterion to retain the most useful of the synthesized samples. Experimental results using several downstream classifiers on a variety of tabular class-imbalanced datasets show that the proposed method improves average precision when compared to alternative re-weighting and oversampling techniques.
Automated identification of transiting exoplanet candidates in NASA Transiting Exoplanets Survey Satellite (TESS) data with machine learning methods
Feb 20, 2021



A novel artificial intelligence (AI) technique that uses machine learning (ML) methodologies combines several algorithms, which were developed by ThetaRay, Inc., is applied to NASA's Transiting Exoplanets Survey Satellite (TESS) dataset to identify exoplanetary candidates. The AI/ML ThetaRay system is trained initially with Kepler exoplanetary data and validated with confirmed exoplanets before its application to TESS data. Existing and new features of the data, based on various observational parameters, are constructed and used in the AI/ML analysis by employing semi-supervised and unsupervised machine learning techniques. By the application of ThetaRay system to 10,803 light curves of threshold crossing events (TCEs) produced by the TESS mission, obtained from the Mikulski Archive for Space Telescopes, we uncover 39 new exoplanetary candidates (EPC) targets. This study demonstrates for the first time the successful application of combined multiple AI/ML-based methodologies to a large astrophysical dataset for rapid automated classification of EPCs.
Deep Gated Canonical Correlation Analysis
Oct 12, 2020
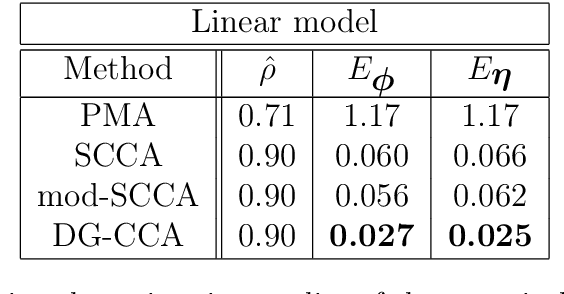
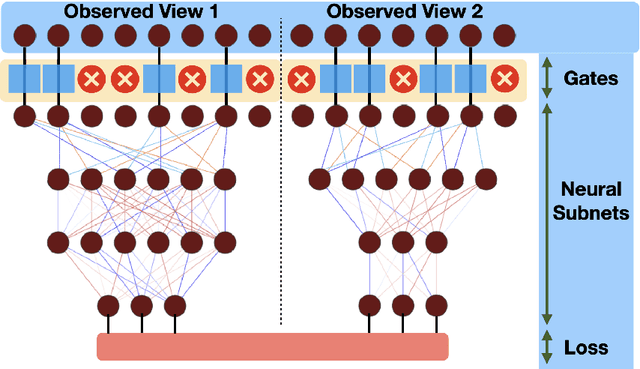
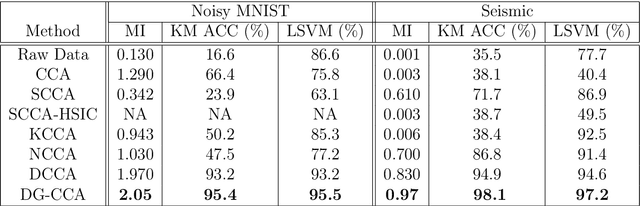
Canonical Correlation Analysis (CCA) models can extract informative correlated representations from multimodal unlabelled data. Despite their success, CCA models may break if the number of variables exceeds the number of samples. We propose Deep Gated-CCA, a method for learning correlated representations based on a sparse subset of variables from two observed modalities. The proposed procedure learns two non-linear transformations and simultaneously gates the input variables to identify a subset of most correlated variables. The non-linear transformations are learned by training two neural networks to maximize a shared correlation loss defined based on their outputs. Gating is obtained by adding an approximate $\ell_0$ regularization term applied to the input variables. This approximation relies on a recently proposed continuous Gaussian based relaxation for Bernoulli variables which act as gates. We demonstrate the efficacy of the method using several synthetic and real examples. Most notably, the method outperforms other linear and non-linear CCA models.
Randomized LU decomposition: An Algorithm for Dictionaries Construction
Jan 27, 2018In recent years, distinctive-dictionary construction has gained importance due to his usefulness in data processing. Usually, one or more dictionaries are constructed from a training data and then they are used to classify signals that did not participate in the training process. A new dictionary construction algorithm is introduced. It is based on a low-rank matrix factorization being achieved by the application of the randomized LU decomposition to a training data. This method is fast, scalable, parallelizable, consumes low memory, outperforms SVD in these categories and works also extremely well on large sparse matrices. In contrast to existing methods, the randomized LU decomposition constructs an under-complete dictionary, which simplifies both the construction and the classification processes of newly arrived signals. The dictionary construction is generic and general that fits different applications. We demonstrate the capabilities of this algorithm for file type identification, which is a fundamental task in digital security arena, performed nowadays for example by sandboxing mechanism, deep packet inspection, firewalls and anti-virus systems. We propose a content-based method that detects file types that neither depend on file extension nor on metadata. Such approach is harder to deceive and we show that only a few file fragments from a whole file are needed for a successful classification. Based on the constructed dictionaries, we show that the proposed method can effectively identify execution code fragments in PDF files. $\textbf{Keywords.}$ Dictionary construction, classification, LU decomposition, randomized LU decomposition, content-based file detection, computer security.
Similarity Search Over Graphs Using Localized Spectral Analysis
Jul 11, 2017
This paper provides a new similarity detection algorithm. Given an input set of multi-dimensional data points, where each data point is assumed to be multi-dimensional, and an additional reference data point for similarity finding, the algorithm uses kernel method that embeds the data points into a low dimensional manifold. Unlike other kernel methods, which consider the entire data for the embedding, our method selects a specific set of kernel eigenvectors. The eigenvectors are chosen to separate between the data points and the reference data point so that similar data points can be easily identified as being distinct from most of the members in the dataset.
Kernel Scaling for Manifold Learning and Classification
Jul 04, 2017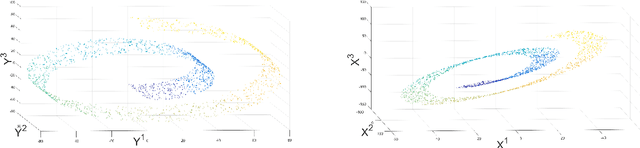
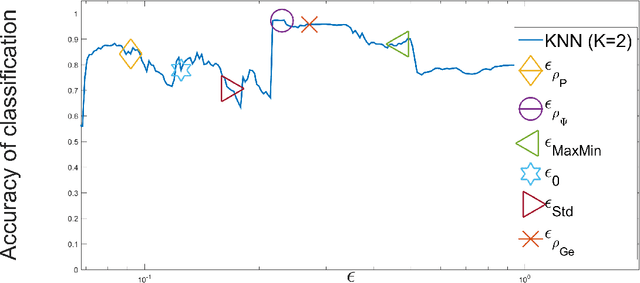
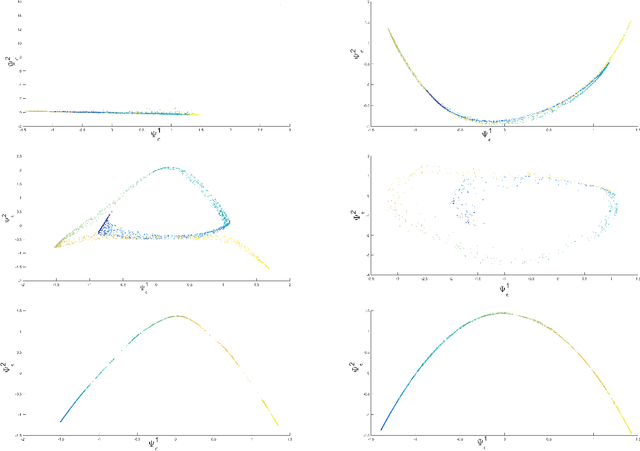
Kernel methods play a critical role in many dimensionality reduction algorithms. They are useful in manifold learning, classification, clustering and other machine learning tasks. Setting the kernel's scale parameter, also referred as the kernel's bandwidth, highly affects the extracted low-dimensional representation. We propose to set a scale parameter that is tailored to the desired application such as classification and manifold learning. The scale computation for the manifold learning task enables that the dimension of the extracted embedding equals the intrinsic dimension estimation. Three methods are proposed for scale computation in a classification task. The proposed frameworks are simulated on artificial and real datasets. The results show a high correlation between optimal classification rates and the computed scaling.
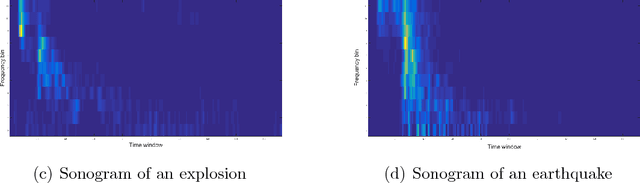
Multi-View Kernels for Low-Dimensional Modeling of Seismic Events
Jun 06, 2017
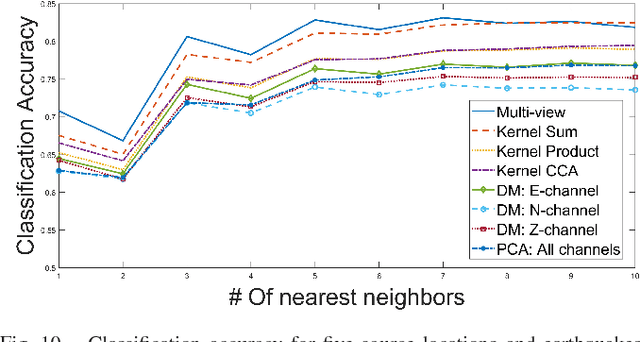


The problem of learning from seismic recordings has been studied for years. There is a growing interest in developing automatic mechanisms for identifying the properties of a seismic event. One main motivation is the ability have a reliable identification of man-made explosions. The availability of multiple high-dimensional observations has increased the use of machine learning techniques in a variety of fields. In this work, we propose to use a kernel-fusion based dimensionality reduction framework for generating meaningful seismic representations from raw data. The proposed method is tested on 2023 events that were recorded in Israel and in Jordan. The method achieves promising results in classification of event type as well as in estimating the location of the event. The proposed fusion and dimensionality reduction tools may be applied to other types of geophysical data.