 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deeper Approach to Non-Convergent Discourse Parsing
May 21, 2023Online social platforms provide a bustling arena for information-sharing and for multi-party discussions. Various frameworks for dialogic discourse parsing were developed and used for the processing of discussions and for predicting the productivity of a dialogue. However, most of these frameworks are not suitable for the analysis of contentious discussions that are commonplace in many online platforms. A novel multi-label scheme for contentious dialog parsing was recently introduced by Zakharov et al. (2021). While the schema is well developed, the computational approach they provide is both naive and inefficient, as a different model (architecture) using a different representation of the input, is trained for each of the 31 tags in the annotation scheme. Moreover, all their models assume full knowledge of label collocations and context, which is unlikely in any realistic setting. In this work, we present a unified model for Non-Convergent Discourse Parsing that does not require any additional input other than the previous dialog utterances. We fine-tuned a RoBERTa backbone, combining embeddings of the utterance, the context and the labels through GRN layers and an asymmetric loss function. Overall, our model achieves results comparable with SOTA, without using label collocation and without training a unique architecture/model for each label.
Imbalanced Classification via a Tabular Translation GAN
Apr 19, 2022
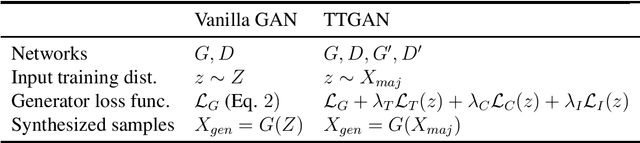

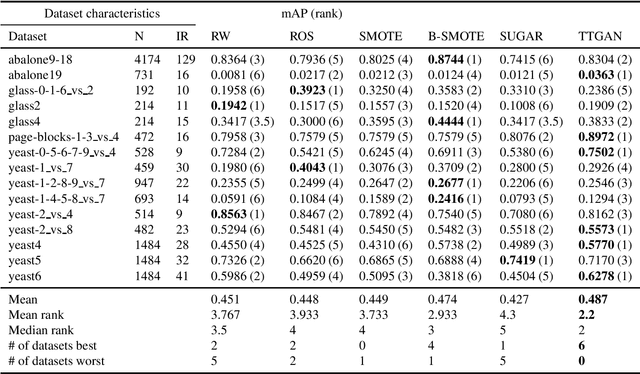
When presented with a binary classification problem where the data exhibits severe class imbalance, most standard predictive methods may fail to accurately model the minority class. We present a model based on Generative Adversarial Networks which uses additional regularization losses to map majority samples to corresponding synthetic minority samples. This translation mechanism encourages the synthesized samples to be close to the class boundary. Furthermore, we explore a selection criterion to retain the most useful of the synthesized samples. Experimental results using several downstream classifiers on a variety of tabular class-imbalanced datasets show that the proposed method improves average precision when compared to alternative re-weighting and oversampling techniques.