 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering a Winning Lottery Ticket with Continuously Relaxed Bernoulli Gates
Mar 09, 2026Over-parameterized neural networks incur prohibitive memory and computational costs for resource-constrained deployment. The Strong Lottery Ticket (SLT) hypothesis suggests that randomly initialized networks contain sparse subnetworks achieving competitive accuracy without weight training. Existing SLT methods, notably edge-popup, rely on non-differentiable score-based selection, limiting optimization efficiency and scalability. We propose using continuously relaxed Bernoulli gates to discover SLTs through fully differentiable, end-to-end optimization - training only gating parameters while keeping all network weights frozen at their initialized values. Continuous relaxation enables direct gradient-based optimization of an $\ell_0$-regularization objective, eliminating the need for non-differentiable gradient estimators or iterative pruning cycles. To our knowledge, this is the first fully differentiable approach for SLT discovery that avoids straight-through estimator approximations. Experiments across fully connected networks, CNNs (ResNet, Wide-ResNet), and Vision Transformers (ViT, Swin-T) demonstrate up to 90% sparsity with minimal accuracy loss - nearly double the sparsity achieved by edge-popup at comparable accuracy - establishing a scalable framework for pre-training network sparsification.
Train Less, Infer Faster: Efficient Model Finetuning and Compression via Structured Sparsity
Feb 09, 2026Fully finetuning foundation language models (LMs) with billions of parameters is often impractical due to high computational costs, memory requirements, and the risk of overfitting. Although methods like low-rank adapters help address these challenges by adding small trainable modules to the frozen LM, they also increase memory usage and do not reduce inference latency. We uncover an intriguing phenomenon: sparsifying specific model rows and columns enables efficient task adaptation without requiring weight tuning. We propose a scheme for effective finetuning via sparsification using training stochastic gates, which requires minimal trainable parameters, reduces inference time, and removes 20--40\% of model parameters without significant accuracy loss. Empirical results show it outperforms recent finetuning baselines in efficiency and performance. Additionally, we provide theoretical guarantees for the convergence of this stochastic gating process, and show that our method admits a simpler and better-conditioned optimization landscape compared to LoRA. Our results highlight sparsity as a compelling mechanism for task-specific adaptation in LMs.
Unsupervised Feature Selection Through Group Discovery
Nov 12, 2025Unsupervised feature selection (FS) is essential for high-dimensional learning tasks where labels are not available. It helps reduce noise, improve generalization, and enhance interpretability. However, most existing unsupervised FS methods evaluate features in isolation, even though informative signals often emerge from groups of related features. For example, adjacent pixels, functionally connected brain regions, or correlated financial indicators tend to act together, making independent evaluation suboptimal. Although some methods attempt to capture group structure, they typically rely on predefined partitions or label supervision, limiting their applicability. We propose GroupFS, an end-to-end, fully differentiable framework that jointly discovers latent feature groups and selects the most informative groups among them, without relying on fixed a priori groups or label supervision. GroupFS enforces Laplacian smoothness on both feature and sample graphs and applies a group sparsity regularizer to learn a compact, structured representation. Across nine benchmarks spanning images, tabular data, and biological datasets, GroupFS consistently outperforms state-of-the-art unsupervised FS in clustering and selects groups of features that align with meaningful patterns.
Hybrid Autoencoders for Tabular Data: Leveraging Model-Based Augmentation in Low-Label Settings
Nov 10, 2025Deep neural networks often under-perform on tabular data due to their sensitivity to irrelevant features and a spectral bias toward smooth, low-frequency functions. These limitations hinder their ability to capture the sharp, high-frequency signals that often define tabular structure, especially under limited labeled samples. While self-supervised learning (SSL) offers promise in such settings, it remains challenging in tabular domains due to the lack of effective data augmentations. We propose a hybrid autoencoder that combines a neural encoder with an oblivious soft decision tree (OSDT) encoder, each guided by its own stochastic gating network that performs sample-specific feature selection. Together, these structurally different encoders and model-specific gating networks implement model-based augmentation, producing complementary input views tailored to each architecture. The two encoders, trained with a shared decoder and cross-reconstruction loss, learn distinct yet aligned representations that reflect their respective inductive biases. During training, the OSDT encoder (robust to noise and effective at modeling localized, high-frequency structure) guides the neural encoder toward representations more aligned with tabular data. At inference, only the neural encoder is used, preserving flexibility and SSL compatibility. Spectral analysis highlights the distinct inductive biases of each encoder. Our method achieves consistent gains in low-label classification and regression across diverse tabular datasets, outperforming deep and tree-based supervised baselines.
TempoControl: Temporal Attention Guidance for Text-to-Video Models
Oct 02, 2025Recent advances in generative video models have enabled the creation of high-quality videos based on natural language prompts. However, these models frequently lack fine-grained temporal control, meaning they do not allow users to specify when particular visual elements should appear within a generated sequence. In this work, we introduce TempoControl, a method that allows for temporal alignment of visual concepts during inference, without requiring retraining or additional supervision. TempoControl utilizes cross-attention maps, a key component of text-to-video diffusion models, to guide the timing of concepts through a novel optimization approach. Our method steers attention using three complementary principles: aligning its temporal shape with a control signal (via correlation), amplifying it where visibility is needed (via energy), and maintaining spatial focus (via entropy). TempoControl allows precise control over timing while ensuring high video quality and diversity. We demonstrate its effectiveness across various video generation applications, including temporal reordering for single and multiple objects, as well as action and audio-aligned generation.
SUMO: Subspace-Aware Moment-Orthogonalization for Accelerating Memory-Efficient LLM Training
May 30, 2025
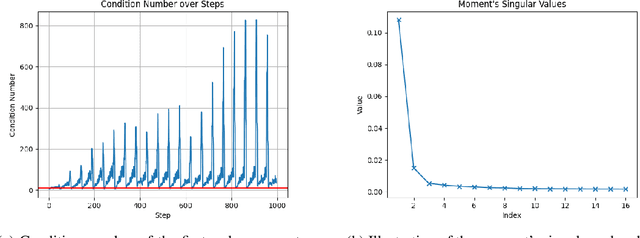
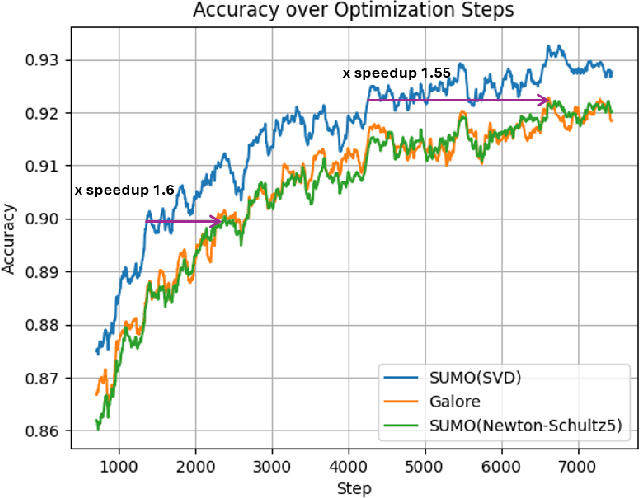
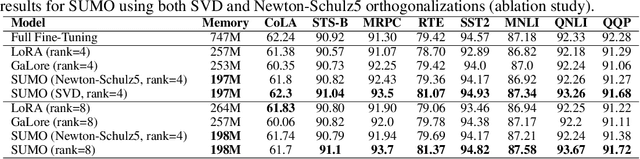
Low-rank gradient-based optimization methods have significantly improved memory efficiency during the training of large language models (LLMs), enabling operations within constrained hardware without sacrificing performance. However, these methods primarily emphasize memory savings, often overlooking potential acceleration in convergence due to their reliance on standard isotropic steepest descent techniques, which can perform suboptimally in the highly anisotropic landscapes typical of deep networks, particularly LLMs. In this paper, we propose SUMO (Subspace-Aware Moment-Orthogonalization), an optimizer that employs exact singular value decomposition (SVD) for moment orthogonalization within a dynamically adapted low-dimensional subspace, enabling norm-inducing steepest descent optimization steps. By explicitly aligning optimization steps with the spectral characteristics of the loss landscape, SUMO effectively mitigates approximation errors associated with commonly used methods like Newton-Schulz orthogonalization approximation. We theoretically establish an upper bound on these approximation errors, proving their dependence on the condition numbers of moments, conditions we analytically demonstrate are encountered during LLM training. Furthermore, we both theoretically and empirically illustrate that exact orthogonalization via SVD substantially improves convergence rates while reducing overall complexity. Empirical evaluations confirm that SUMO accelerates convergence, enhances stability, improves performance, and reduces memory requirements by up to 20% compared to state-of-the-art methods.
Detect and Correct: A Selective Noise Correction Method for Learning with Noisy Labels
May 19, 2025



Falsely annotated samples, also known as noisy labels, can significantly harm the performance of deep learning models. Two main approaches for learning with noisy labels are global noise estimation and data filtering. Global noise estimation approximates the noise across the entire dataset using a noise transition matrix, but it can unnecessarily adjust correct labels, leaving room for local improvements. Data filtering, on the other hand, discards potentially noisy samples but risks losing valuable data. Our method identifies potentially noisy samples based on their loss distribution. We then apply a selection process to separate noisy and clean samples and learn a noise transition matrix to correct the loss for noisy samples while leaving the clean data unaffected, thereby improving the training process. Our approach ensures robust learning and enhanced model performance by preserving valuable information from noisy samples and refining the correction process. We applied our method to standard image datasets (MNIST, CIFAR-10, and CIFAR-100) and a biological scRNA-seq cell-type annotation dataset. We observed a significant improvement in model accuracy and robustness compared to traditional methods.
LORENZA: Enhancing Generalization in Low-Rank Gradient LLM Training via Efficient Zeroth-Order Adaptive SAM
Feb 26, 2025We study robust parameter-efficient fine-tuning (PEFT) techniques designed to improve accuracy and generalization while operating within strict computational and memory hardware constraints, specifically focusing on large-language models (LLMs). Existing PEFT methods often lack robustness and fail to generalize effectively across diverse tasks, leading to suboptimal performance in real-world scenarios. To address this, we present a new highly computationally efficient framework called AdaZo-SAM, combining Adam and Sharpness-Aware Minimization (SAM) while requiring only a single-gradient computation in every iteration. This is achieved using a stochastic zeroth-order estimation to find SAM's ascent perturbation. We provide a convergence guarantee for AdaZo-SAM and show that it improves the generalization ability of state-of-the-art PEFT methods. Additionally, we design a low-rank gradient optimization method named LORENZA, which is a memory-efficient version of AdaZo-SAM. LORENZA utilizes a randomized SVD scheme to efficiently compute the subspace projection matrix and apply optimization steps onto the selected subspace. This technique enables full-parameter fine-tuning with adaptive low-rank gradient updates, achieving the same reduced memory consumption as gradient-low-rank-projection methods. We provide a convergence analysis of LORENZA and demonstrate its merits for pre-training and fine-tuning LLMs.
Conditional Deep Canonical Time Warping
Dec 24, 2024



Temporal alignment of sequences is a fundamental challenge in many applications, such as computer vision and bioinformatics, where local time shifting needs to be accounted for. Misalignment can lead to poor model generalization, especially in high-dimensional sequences. Existing methods often struggle with optimization when dealing with high-dimensional sparse data, falling into poor alignments. Feature selection is frequently used to enhance model performance for sparse data. However, a fixed set of selected features would not generally work for dynamically changing sequences and would need to be modified based on the state of the sequence. Therefore, modifying the selected feature based on contextual input would result in better alignment. Our suggested method, Conditional Deep Canonical Temporal Time Warping (CDCTW), is designed for temporal alignment in sparse temporal data to address these challenges. CDCTW enhances alignment accuracy for high dimensional time-dependent views be performing dynamic time warping on data embedded in maximally correlated subspace which handles sparsity with novel feature selection method. We validate the effectiveness of CDCTW through extensive experiments on various datasets, demonstrating superior performance over previous techniques.
FineGates: LLMs Finetuning with Compression using Stochastic Gates
Dec 17, 2024



Large Language Models (LLMs), with billions of parameters, present significant challenges for full finetuning due to the high computational demands, memory requirements, and impracticality of many real-world applications. When faced with limited computational resources or small datasets, updating all model parameters can often result in overfitting. To address this, lightweight finetuning techniques have been proposed, like learning low-rank adapter layers. These methods aim to train only a few additional parameters combined with the base model, which remains frozen, reducing resource usage and mitigating overfitting risks. In this work, we propose an adaptor model based on stochastic gates that simultaneously sparsify the frozen base model with task-specific adaptation. Our method comes with a small number of trainable parameters and allows us to speed up the base model inference with competitive accuracy. We evaluate it in additional variants by equipping it with additional low-rank parameters and comparing it to several recent baselines. Our results show that the proposed method improves the finetuned model accuracy comparatively to the several baselines and allows the removal of up to 20-40\% without significant accuracy loss.