 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUMO: Subspace-Aware Moment-Orthogonalization for Accelerating Memory-Efficient LLM Training
May 30, 2025
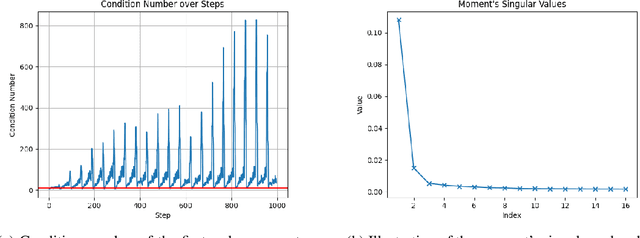
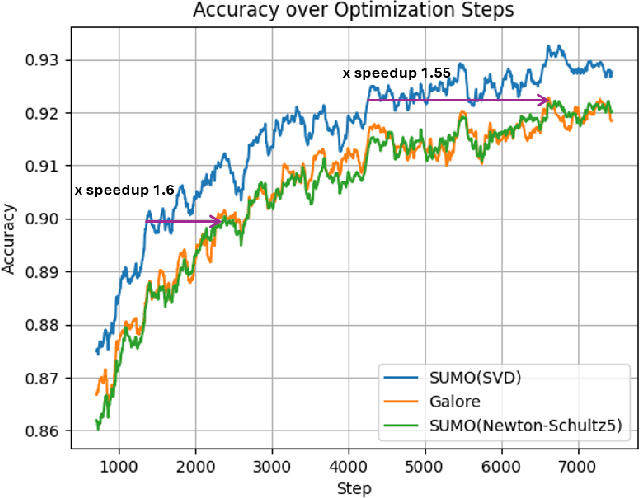
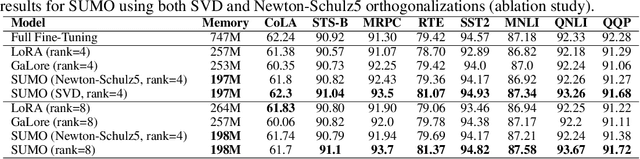
Low-rank gradient-based optimization methods have significantly improved memory efficiency during the training of large language models (LLMs), enabling operations within constrained hardware without sacrificing performance. However, these methods primarily emphasize memory savings, often overlooking potential acceleration in convergence due to their reliance on standard isotropic steepest descent techniques, which can perform suboptimally in the highly anisotropic landscapes typical of deep networks, particularly LLMs. In this paper, we propose SUMO (Subspace-Aware Moment-Orthogonalization), an optimizer that employs exact singular value decomposition (SVD) for moment orthogonalization within a dynamically adapted low-dimensional subspace, enabling norm-inducing steepest descent optimization steps. By explicitly aligning optimization steps with the spectral characteristics of the loss landscape, SUMO effectively mitigates approximation errors associated with commonly used methods like Newton-Schulz orthogonalization approximation. We theoretically establish an upper bound on these approximation errors, proving their dependence on the condition numbers of moments, conditions we analytically demonstrate are encountered during LLM training. Furthermore, we both theoretically and empirically illustrate that exact orthogonalization via SVD substantially improves convergence rates while reducing overall complexity. Empirical evaluations confirm that SUMO accelerates convergence, enhances stability, improves performance, and reduces memory requirements by up to 20% compared to state-of-the-art methods.
Provable Privacy Attacks on Trained Shallow Neural Networks
Oct 10, 2024We study what provable privacy attacks can be shown on trained, 2-layer ReLU neural networks. We explore two types of attacks; data reconstruction attacks, and membership inference attacks. We prove that theoretical results on the implicit bias of 2-layer neural networks can be used to provably reconstruct a set of which at least a constant fraction are training points in a univariate setting, and can also be used to identify with high probability whether a given point was used in the training set in a high dimensional setting. To the best of our knowledge, our work is the first to show provable vulnerabilities in this setting.