 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Less, Infer Faster: Efficient Model Finetuning and Compression via Structured Sparsity
Feb 09, 2026Fully finetuning foundation language models (LMs) with billions of parameters is often impractical due to high computational costs, memory requirements, and the risk of overfitting. Although methods like low-rank adapters help address these challenges by adding small trainable modules to the frozen LM, they also increase memory usage and do not reduce inference latency. We uncover an intriguing phenomenon: sparsifying specific model rows and columns enables efficient task adaptation without requiring weight tuning. We propose a scheme for effective finetuning via sparsification using training stochastic gates, which requires minimal trainable parameters, reduces inference time, and removes 20--40\% of model parameters without significant accuracy loss. Empirical results show it outperforms recent finetuning baselines in efficiency and performance. Additionally, we provide theoretical guarantees for the convergence of this stochastic gating process, and show that our method admits a simpler and better-conditioned optimization landscape compared to LoRA. Our results highlight sparsity as a compelling mechanism for task-specific adaptation in LMs.
SUMO: Subspace-Aware Moment-Orthogonalization for Accelerating Memory-Efficient LLM Training
May 30, 2025
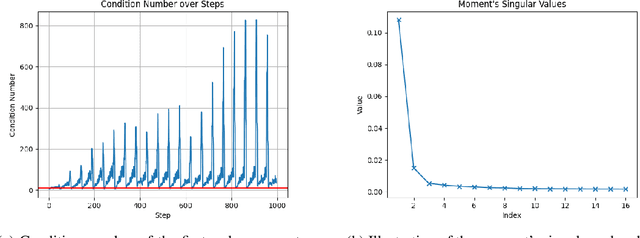
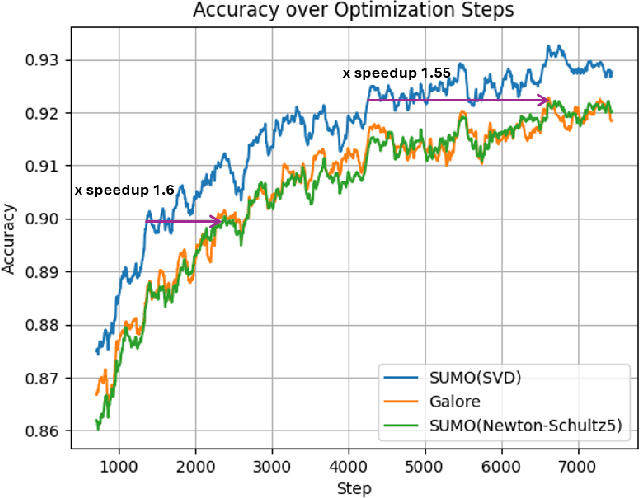
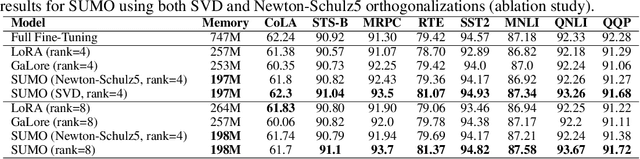
Low-rank gradient-based optimization methods have significantly improved memory efficiency during the training of large language models (LLMs), enabling operations within constrained hardware without sacrificing performance. However, these methods primarily emphasize memory savings, often overlooking potential acceleration in convergence due to their reliance on standard isotropic steepest descent techniques, which can perform suboptimally in the highly anisotropic landscapes typical of deep networks, particularly LLMs. In this paper, we propose SUMO (Subspace-Aware Moment-Orthogonalization), an optimizer that employs exact singular value decomposition (SVD) for moment orthogonalization within a dynamically adapted low-dimensional subspace, enabling norm-inducing steepest descent optimization steps. By explicitly aligning optimization steps with the spectral characteristics of the loss landscape, SUMO effectively mitigates approximation errors associated with commonly used methods like Newton-Schulz orthogonalization approximation. We theoretically establish an upper bound on these approximation errors, proving their dependence on the condition numbers of moments, conditions we analytically demonstrate are encountered during LLM training. Furthermore, we both theoretically and empirically illustrate that exact orthogonalization via SVD substantially improves convergence rates while reducing overall complexity. Empirical evaluations confirm that SUMO accelerates convergence, enhances stability, improves performance, and reduces memory requirements by up to 20% compared to state-of-the-art methods.
LORENZA: Enhancing Generalization in Low-Rank Gradient LLM Training via Efficient Zeroth-Order Adaptive SAM
Feb 26, 2025We study robust parameter-efficient fine-tuning (PEFT) techniques designed to improve accuracy and generalization while operating within strict computational and memory hardware constraints, specifically focusing on large-language models (LLMs). Existing PEFT methods often lack robustness and fail to generalize effectively across diverse tasks, leading to suboptimal performance in real-world scenarios. To address this, we present a new highly computationally efficient framework called AdaZo-SAM, combining Adam and Sharpness-Aware Minimization (SAM) while requiring only a single-gradient computation in every iteration. This is achieved using a stochastic zeroth-order estimation to find SAM's ascent perturbation. We provide a convergence guarantee for AdaZo-SAM and show that it improves the generalization ability of state-of-the-art PEFT methods. Additionally, we design a low-rank gradient optimization method named LORENZA, which is a memory-efficient version of AdaZo-SAM. LORENZA utilizes a randomized SVD scheme to efficiently compute the subspace projection matrix and apply optimization steps onto the selected subspace. This technique enables full-parameter fine-tuning with adaptive low-rank gradient updates, achieving the same reduced memory consumption as gradient-low-rank-projection methods. We provide a convergence analysis of LORENZA and demonstrate its merits for pre-training and fine-tuning LLMs.
FineGates: LLMs Finetuning with Compression using Stochastic Gates
Dec 17, 2024



Large Language Models (LLMs), with billions of parameters, present significant challenges for full finetuning due to the high computational demands, memory requirements, and impracticality of many real-world applications. When faced with limited computational resources or small datasets, updating all model parameters can often result in overfitting. To address this, lightweight finetuning techniques have been proposed, like learning low-rank adapter layers. These methods aim to train only a few additional parameters combined with the base model, which remains frozen, reducing resource usage and mitigating overfitting risks. In this work, we propose an adaptor model based on stochastic gates that simultaneously sparsify the frozen base model with task-specific adaptation. Our method comes with a small number of trainable parameters and allows us to speed up the base model inference with competitive accuracy. We evaluate it in additional variants by equipping it with additional low-rank parameters and comparing it to several recent baselines. Our results show that the proposed method improves the finetuned model accuracy comparatively to the several baselines and allows the removal of up to 20-40\% without significant accuracy loss.
TransformLLM: Adapting Large Language Models via LLM-Transformed Reading Comprehension Text
Oct 28, 2024
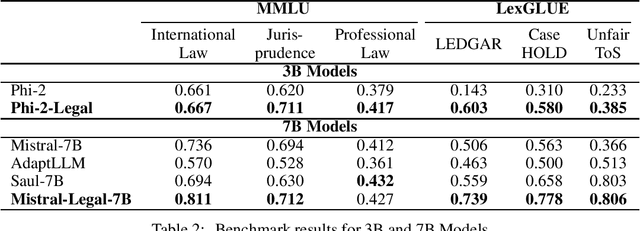
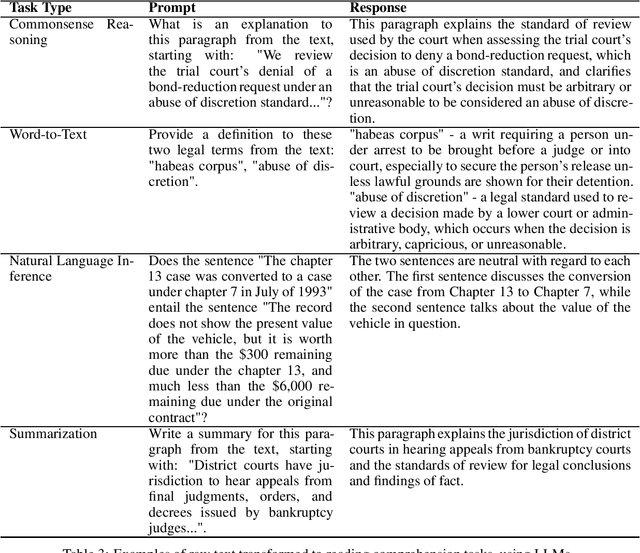
Large Language Models (LLMs) have shown promise in highly-specialized domains, however challenges are still present in aspects of accuracy and costs. These limitations restrict the usage of existing models in domain-specific tasks. While fine-tuning pre-trained models have shown promising results, this process can be computationally expensive and require massive datasets of the specialized application in hand. In this work, we bridge that gap. We have developed Phi-2-Legal and Mistral-Legal-7B, which are language models specifically designed for legal applications. These models are based on Phi-2 and Mistral-7B-v0.1, and have gone through continued pre-training with over 500 million tokens of legal texts. Our innovative approach significantly improves capabilities in legal tasks by using Large Language Models (LLMs) to convert raw training data into reading comprehension text. Our legal LLMs have demonstrated superior performance in legal benchmarks, even outperforming models trained on much larger datasets with more resources. This work emphasizes the effectiveness of continued pre-training on domain-specific texts, while using affordable LLMs for data conversion, which gives these models domain expertise while retaining general language understanding capabilities. While this work uses the legal domain as a test case, our method can be scaled and applied to any pre-training dataset, resulting in significant improvements across different tasks. These findings underscore the potential of domain-adaptive pre-training and reading comprehension for the development of highly effective domain-specific language models.
AdaRankGrad: Adaptive Gradient-Rank and Moments for Memory-Efficient LLMs Training and Fine-Tuning
Oct 23, 2024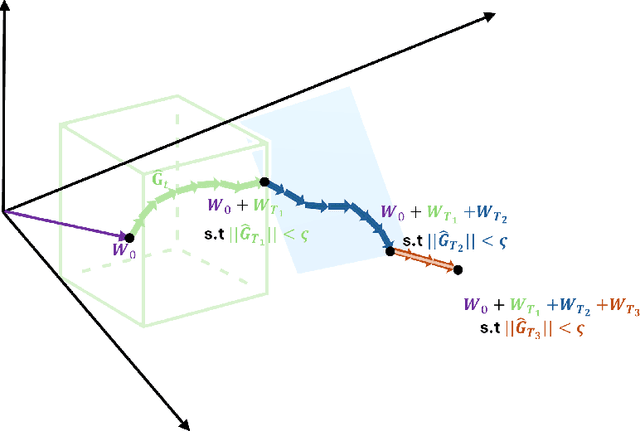
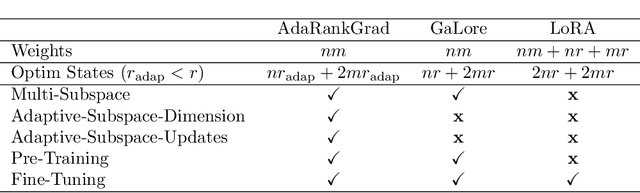
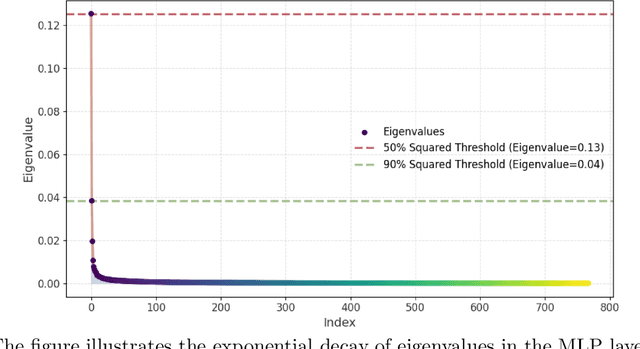

Training and fine-tuning large language models (LLMs) come with challenges related to memory and computational requirements due to the increasing size of the model weights and the optimizer states. Various techniques have been developed to tackle these challenges, such as low-rank adaptation (LoRA), which involves introducing a parallel trainable low-rank matrix to the fixed pre-trained weights at each layer. However, these methods often fall short compared to the full-rank weight training approach, as they restrict the parameter search to a low-rank subspace. This limitation can disrupt training dynamics and require a full-rank warm start to mitigate the impact. In this paper, we introduce a new method inspired by a phenomenon we formally prove: as training progresses, the rank of the estimated layer gradients gradually decreases, and asymptotically approaches rank one. Leveraging this, our approach involves adaptively reducing the rank of the gradients during Adam optimization steps, using an efficient online-updating low-rank projections rule. We further present a randomized SVD scheme for efficiently finding the projection matrix. Our technique enables full-parameter fine-tuning with adaptive low-rank gradient updates, significantly reducing overall memory requirements during training compared to state-of-the-art methods while improving model performance in both pretraining and fine-tuning. Finally, we provide a convergence analysis of our method and demonstrate its merits for training and fine-tuning language and biological foundation models.
SLIP: Securing LLMs IP Using Weights Decomposition
Jul 15, 2024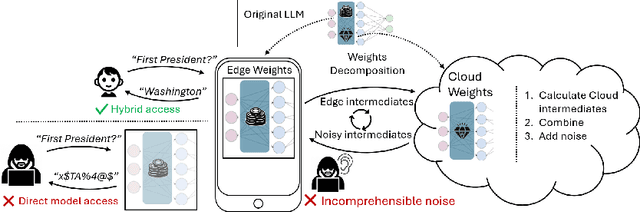
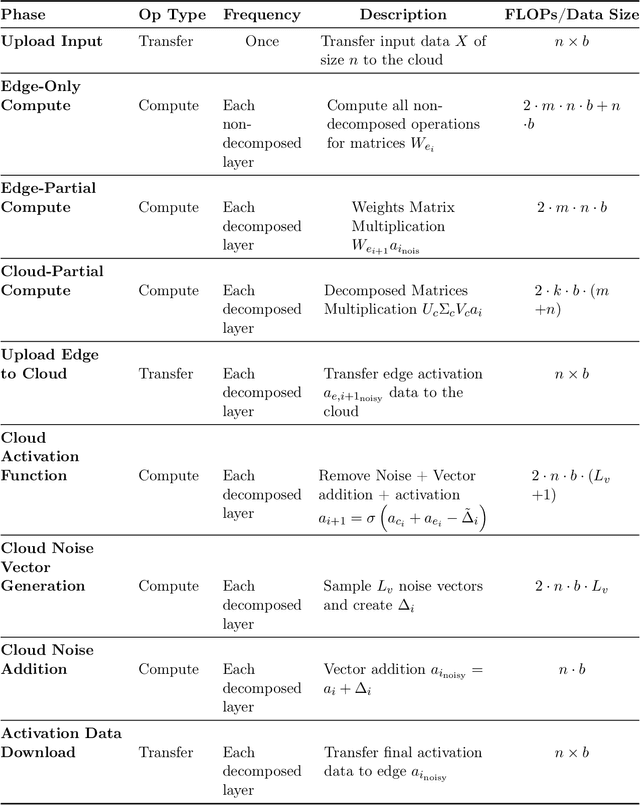
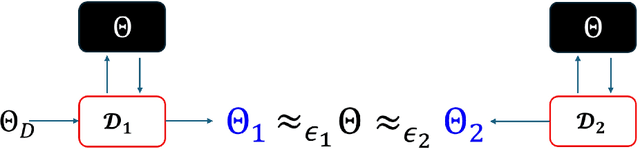
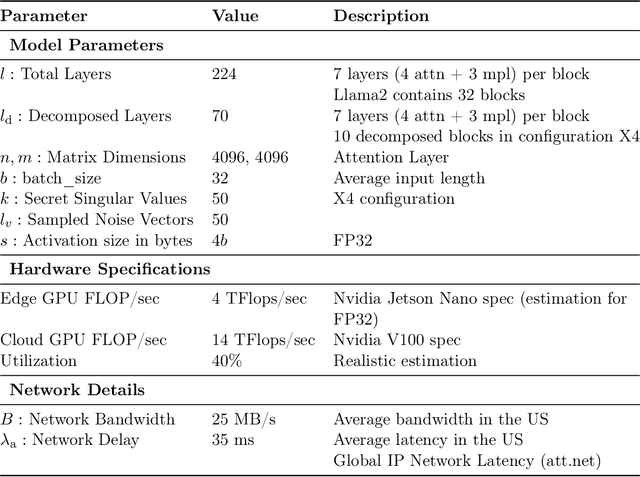
Large language models (LLMs) have recently seen widespread adoption, in both academia and industry. As these models grow, they become valuable intellectual property (IP), reflecting enormous investments by their owners. Moreover, the high cost of cloud-based deployment has driven interest towards deployment to edge devices, yet this risks exposing valuable parameters to theft and unauthorized use. Current methods to protect models' IP on the edge have limitations in terms of practicality, loss in accuracy, or suitability to requirements. In this paper, we introduce a novel hybrid inference algorithm, named SLIP, designed to protect edge-deployed models from theft. SLIP is the first hybrid protocol that is both practical for real-world applications and provably secure, while having zero accuracy degradation and minimal impact on latency. It involves partitioning the model between two computing resources, one secure but expensive, and another cost-effective but vulnerable. This is achieved through matrix decomposition, ensuring that the secure resource retains a maximally sensitive portion of the model's IP while performing a minimal amount of computations, and vice versa for the vulnerable resource. Importantly, the protocol includes security guarantees that prevent attackers from exploiting the partition to infer the secured information. Finally, we present experimental results that show the robustness and effectiveness of our method, positioning it as a compelling solution for protecting LLMs.
Learning k-Level Sparse Neural Networks Using a New Generalized Group Sparse Envelope Regularization
Dec 25, 2022We propose an efficient method to learn both unstructured and structured sparse neural networks during training, using a novel generalization of the sparse envelope function (SEF) used as a regularizer, termed {\itshape{group sparse envelope function}} (GSEF). The GSEF acts as a neuron group selector, which we leverage to induce structured pruning. Our method receives a hardware-friendly structured sparsity of a deep neural network (DNN) to efficiently accelerate the DNN's evaluation. This method is flexible in the sense that it allows any hardware to dictate the definition of a group, such as a filter, channel, filter shape, layer depth, a single parameter (unstructured), etc. By the nature of the GSEF, the proposed method is the first to make possible a pre-define sparsity level that is being achieved at the training convergence, while maintaining negligible network accuracy degradation. We propose an efficient method to calculate the exact value of the GSEF along with its proximal operator, in a worst-case complexity of $O(n)$, where $n$ is the total number of groups variables. In addition, we propose a proximal-gradient-based optimization method to train the model, that is, the non-convex minimization of the sum of the neural network loss and the GSEF. Finally, we conduct an experiment and illustrate the efficiency of our proposed technique in terms of the completion ratio, accuracy, and inference latency.
Mathematical Framework for Online Social Media Regulation
Sep 12, 2022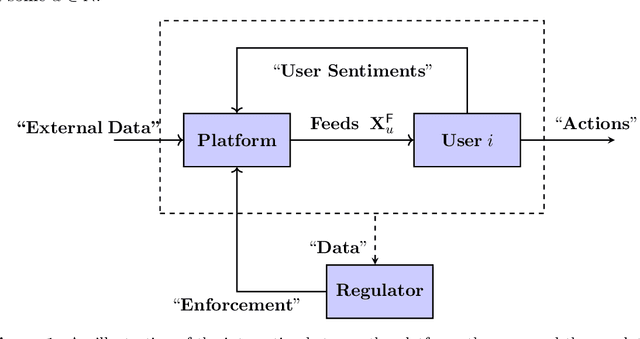
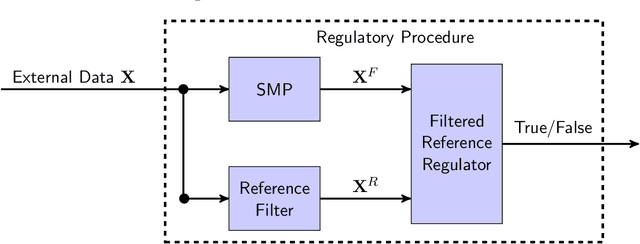

Social media platforms (SMPs) leverage algorithmic filtering (AF) as a means of selecting the content that constitutes a user's feed with the aim of maximizing their rewards. Selectively choosing the contents to be shown on the user's feed may yield a certain extent of influence, either minor or major, on the user's decision-making, compared to what it would have been under a natural/fair content selection. As we have witnessed over the past decade, algorithmic filtering can cause detrimental side effects, ranging from biasing individual decisions to shaping those of society as a whole, for example, diverting users' attention from whether to get the COVID-19 vaccine or inducing the public to choose a presidential candidate. The government's constant attempts to regulate the adverse effects of AF are often complicated, due to bureaucracy, legal affairs, and financial considerations. On the other hand SMPs seek to monitor their own algorithmic activities to avoid being fined for exceeding the allowable threshold. In this paper, we mathematically formalize this framework and utilize it to construct a data-driven statistical algorithm to regulate the AF from deflecting users' beliefs over time, along with sample and complexity guarantees. We show that our algorithm is robust against potential adversarial users. This state-of-the-art algorithm can be used either by authorities acting as external regulators or by SMPs for self-regulation.