 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Continual Fine-Tuning for Enhancing Language Ability in Large Language Model
Oct 21, 2024



A common challenge towards the adaptability of Large Language Models (LLMs) is their ability to learn new languages over time without hampering the model's performance on languages in which the model is already proficient (usually English). Continual fine-tuning (CFT) is the process of sequentially fine-tuning an LLM to enable the model to adapt to downstream tasks with varying data distributions and time shifts. This paper focuses on the language adaptability of LLMs through CFT. We study a two-phase CFT process in which an English-only end-to-end fine-tuned LLM from Phase 1 (predominantly Task Ability) is sequentially fine-tuned on a multilingual dataset -- comprising task data in new languages -- in Phase 2 (predominantly Language Ability). We observe that the ``similarity'' of Phase 2 tasks with Phase 1 determines the LLM's adaptability. For similar phase-wise datasets, the LLM after Phase 2 does not show deterioration in task ability. In contrast, when the phase-wise datasets are not similar, the LLM's task ability deteriorates. We test our hypothesis on the open-source \mis\ and \llm\ models with multiple phase-wise dataset pairs. To address the deterioration, we analyze tailored variants of two CFT methods: layer freezing and generative replay. Our findings demonstrate their effectiveness in enhancing the language ability of LLMs while preserving task performance, in comparison to relevant baselines.
SLIP: Securing LLMs IP Using Weights Decomposition
Jul 15, 2024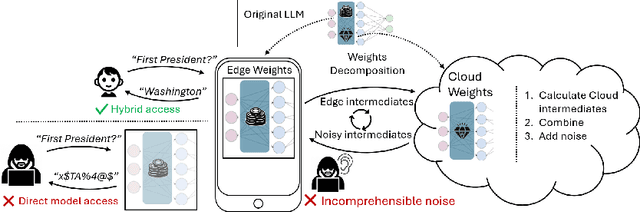
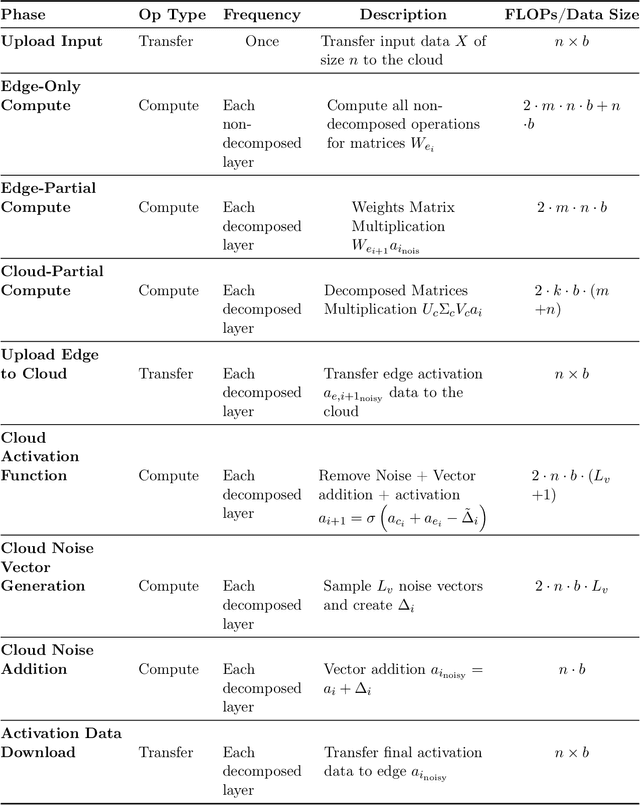
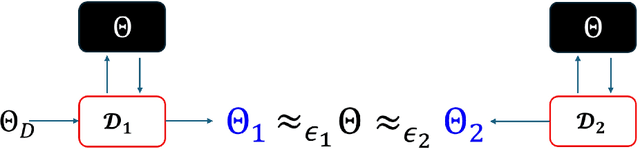
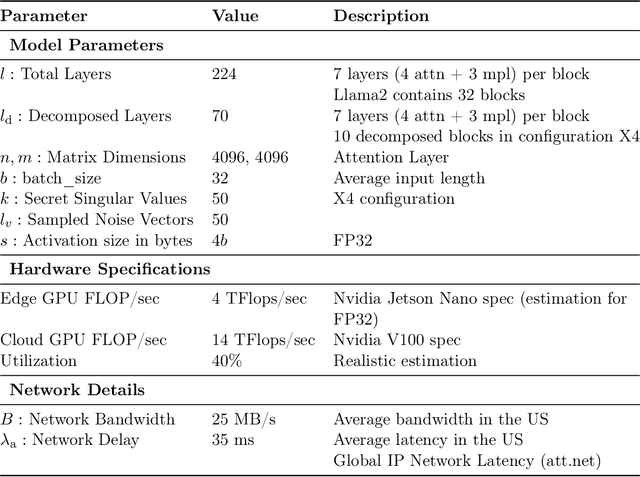
Large language models (LLMs) have recently seen widespread adoption, in both academia and industry. As these models grow, they become valuable intellectual property (IP), reflecting enormous investments by their owners. Moreover, the high cost of cloud-based deployment has driven interest towards deployment to edge devices, yet this risks exposing valuable parameters to theft and unauthorized use. Current methods to protect models' IP on the edge have limitations in terms of practicality, loss in accuracy, or suitability to requirements. In this paper, we introduce a novel hybrid inference algorithm, named SLIP, designed to protect edge-deployed models from theft. SLIP is the first hybrid protocol that is both practical for real-world applications and provably secure, while having zero accuracy degradation and minimal impact on latency. It involves partitioning the model between two computing resources, one secure but expensive, and another cost-effective but vulnerable. This is achieved through matrix decomposition, ensuring that the secure resource retains a maximally sensitive portion of the model's IP while performing a minimal amount of computations, and vice versa for the vulnerable resource. Importantly, the protocol includes security guarantees that prevent attackers from exploiting the partition to infer the secured information. Finally, we present experimental results that show the robustness and effectiveness of our method, positioning it as a compelling solution for protecting LLMs.
Non-Asymptotic Lower Bounds For Training Data Reconstruction
Apr 11, 2023We investigate semantic guarantees of private learning algorithms for their resilience to training Data Reconstruction Attacks (DRAs) by informed adversaries. To this end, we derive non-asymptotic minimax lower bounds on the adversary's reconstruction error against learners that satisfy differential privacy (DP) and metric differential privacy (mDP). Furthermore, we demonstrate that our lower bound analysis for the latter also covers the high dimensional regime, wherein, the input data dimensionality may be larger than the adversary's query budget. Motivated by the theoretical improvements conferred by metric DP, we extend the privacy analysis of popular deep learning algorithms such as DP-SGD and Projected Noisy SGD to cover the broader notion of metric differential privacy.