 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSMIR: Chain Orchestrated Structured Memory for Iterative Reasoning over Long Context
Oct 06, 2025


Reasoning over very long inputs remains difficult for large language models (LLMs). Common workarounds either shrink the input via retrieval (risking missed evidence), enlarge the context window (straining selectivity), or stage multiple agents to read in pieces. In staged pipelines (e.g., Chain of Agents, CoA), free-form summaries passed between agents can discard crucial details and amplify early mistakes. We introduce COSMIR (Chain Orchestrated Structured Memory for Iterative Reasoning), a chain-style framework that replaces ad hoc messages with a structured memory. A Planner agent first turns a user query into concrete, checkable sub-questions. worker agents process chunks via a fixed micro-cycle: Extract, Infer, Refine, writing all updates to the shared memory. A Manager agent then Synthesizes the final answer directly from the memory. This preserves step-wise read-then-reason benefits while changing both the communication medium (structured memory) and the worker procedure (fixed micro-cycle), yielding higher faithfulness, better long-range aggregation, and auditability. On long-context QA from the HELMET suite, COSMIR reduces propagation-stage information loss and improves accuracy over a CoA baseline.
LLMs for Resource Allocation: A Participatory Budgeting Approach to Inferring Preferences
Aug 08, 2025Large Language Models (LLMs) are increasingly expected to handle complex decision-making tasks, yet their ability to perform structured resource allocation remains underexplored. Evaluating their reasoning is also difficult due to data contamination and the static nature of existing benchmarks. We present a dual-purpose framework leveraging Participatory Budgeting (PB) both as (i) a practical setting for LLM-based resource allocation and (ii) an adaptive benchmark for evaluating their reasoning capabilities. We task LLMs with selecting project subsets under feasibility (e.g., budget) constraints via three prompting strategies: greedy selection, direct optimization, and a hill-climbing-inspired refinement. We benchmark LLMs' allocations against a utility-maximizing oracle. Interestingly, we also test whether LLMs can infer structured preferences from natural-language voter input or metadata, without explicit votes. By comparing allocations based on inferred preferences to those from ground-truth votes, we evaluate LLMs' ability to extract preferences from open-ended input. Our results underscore the role of prompt design and show that LLMs hold promise for mechanism design with unstructured inputs.
Exploring Continual Fine-Tuning for Enhancing Language Ability in Large Language Model
Oct 21, 2024



A common challenge towards the adaptability of Large Language Models (LLMs) is their ability to learn new languages over time without hampering the model's performance on languages in which the model is already proficient (usually English). Continual fine-tuning (CFT) is the process of sequentially fine-tuning an LLM to enable the model to adapt to downstream tasks with varying data distributions and time shifts. This paper focuses on the language adaptability of LLMs through CFT. We study a two-phase CFT process in which an English-only end-to-end fine-tuned LLM from Phase 1 (predominantly Task Ability) is sequentially fine-tuned on a multilingual dataset -- comprising task data in new languages -- in Phase 2 (predominantly Language Ability). We observe that the ``similarity'' of Phase 2 tasks with Phase 1 determines the LLM's adaptability. For similar phase-wise datasets, the LLM after Phase 2 does not show deterioration in task ability. In contrast, when the phase-wise datasets are not similar, the LLM's task ability deteriorates. We test our hypothesis on the open-source \mis\ and \llm\ models with multiple phase-wise dataset pairs. To address the deterioration, we analyze tailored variants of two CFT methods: layer freezing and generative replay. Our findings demonstrate their effectiveness in enhancing the language ability of LLMs while preserving task performance, in comparison to relevant baselines.
Designing Redistribution Mechanisms for Reducing Transaction Fees in Blockchains
Jan 24, 2024Blockchains deploy Transaction Fee Mechanisms (TFMs) to determine which user transactions to include in blocks and determine their payments (i.e., transaction fees). Increasing demand and scarce block resources have led to high user transaction fees. As these blockchains are a public resource, it may be preferable to reduce these transaction fees. To this end, we introduce Transaction Fee Redistribution Mechanisms (TFRMs) -- redistributing VCG payments collected from such TFM as rebates to minimize transaction fees. Classic redistribution mechanisms (RMs) achieve this while ensuring Allocative Efficiency (AE) and User Incentive Compatibility (UIC). Our first result shows the non-triviality of applying RM in TFMs. More concretely, we prove that it is impossible to reduce transaction fees when (i) transactions that are not confirmed do not receive rebates and (ii) the miner can strategically manipulate the mechanism. Driven by this, we propose \emph{Robust} TFRM (\textsf{R-TFRM}): a mechanism that compromises on an honest miner's individual rationality to guarantee strictly positive rebates to the users. We then introduce \emph{robust} and \emph{rational} TFRM (\textsf{R}$^2$\textsf{-TFRM}) that uses trusted on-chain randomness that additionally guarantees miner's individual rationality (in expectation) and strictly positive rebates. Our results show that TFRMs provide a promising new direction for reducing transaction fees in public blockchains.
Combinatorial Civic Crowdfunding with Budgeted Agents: Welfare Optimality at Equilibrium and Optimal Deviation
Nov 25, 2022Civic Crowdfunding (CC) uses the ``power of the crowd'' to garner contributions towards public projects. As these projects are non-excludable, agents may prefer to ``free-ride,'' resulting in the project not being funded. For single project CC, researchers propose to provide refunds to incentivize agents to contribute, thereby guaranteeing the project's funding. These funding guarantees are applicable only when agents have an unlimited budget. This work focuses on a combinatorial setting, where multiple projects are available for CC and agents have a limited budget. We study certain specific conditions where funding can be guaranteed. Further, funding the optimal social welfare subset of projects is desirable when every available project cannot be funded due to budget restrictions. We prove the impossibility of achieving optimal welfare at equilibrium for any monotone refund scheme. We then study different heuristics that the agents can use to contribute to the projects in practice. Through simulations, we demonstrate the heuristics' performance as the average-case trade-off between welfare obtained and agent utility.
Differentially Private Federated Combinatorial Bandits with Constraints
Jun 27, 2022
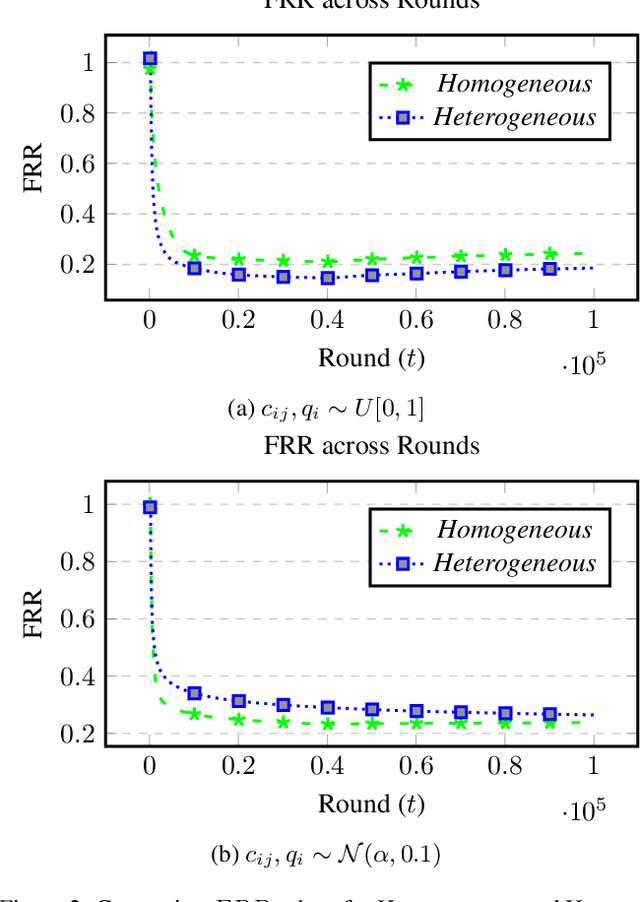
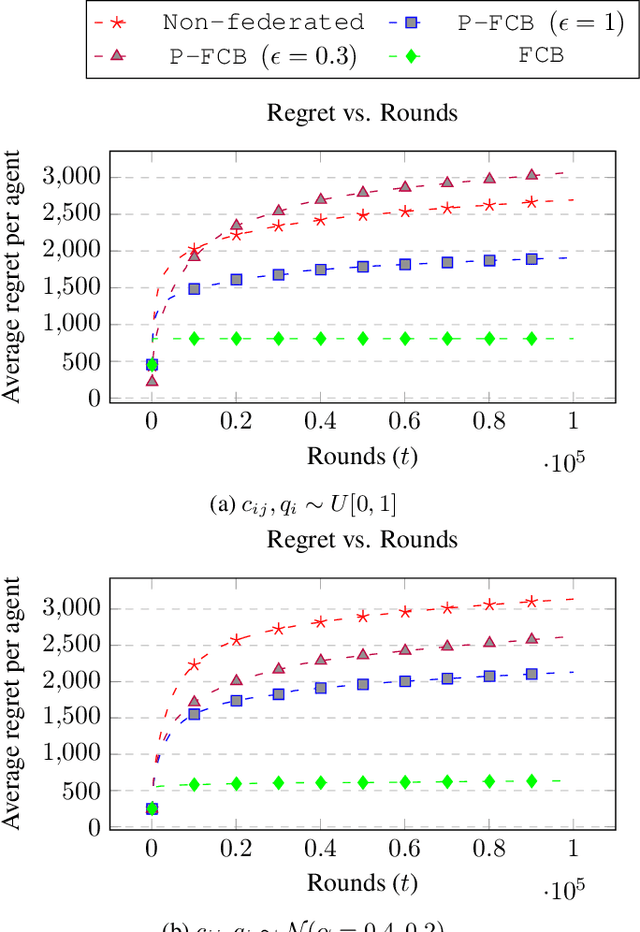

There is a rapid increase in the cooperative learning paradigm in online learning settings, i.e., federated learning (FL). Unlike most FL settings, there are many situations where the agents are competitive. Each agent would like to learn from others, but the part of the information it shares for others to learn from could be sensitive; thus, it desires its privacy. This work investigates a group of agents working concurrently to solve similar combinatorial bandit problems while maintaining quality constraints. Can these agents collectively learn while keeping their sensitive information confidential by employing differential privacy? We observe that communicating can reduce the regret. However, differential privacy techniques for protecting sensitive information makes the data noisy and may deteriorate than help to improve regret. Hence, we note that it is essential to decide when to communicate and what shared data to learn to strike a functional balance between regret and privacy. For such a federated combinatorial MAB setting, we propose a Privacy-preserving Federated Combinatorial Bandit algorithm, P-FCB. We illustrate the efficacy of P-FCB through simulations. We further show that our algorithm provides an improvement in terms of regret while upholding quality threshold and meaningful privacy guarantees.
Fair Federated Learning for Heterogeneous Face Data
Sep 06, 2021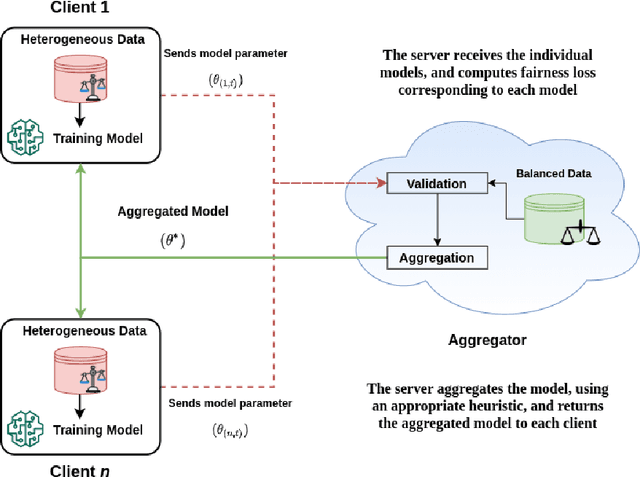
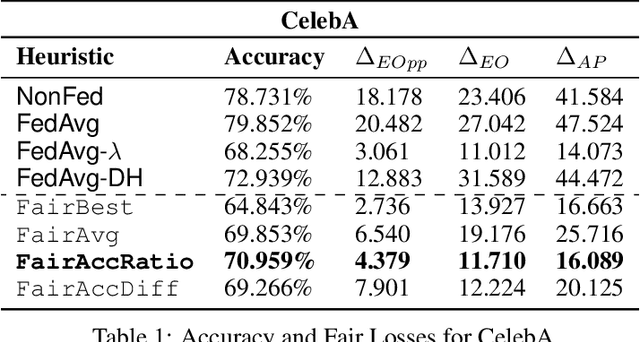

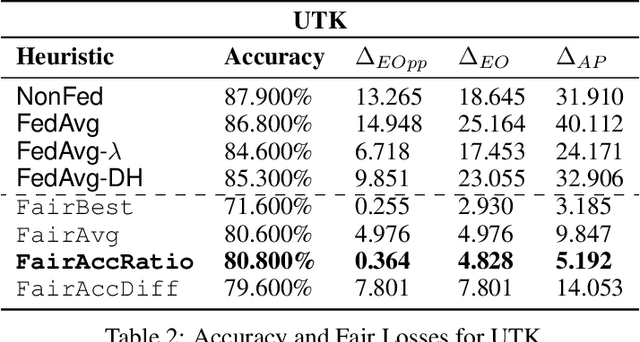
We consider the problem of achieving fair classification in Federated Learning (FL) under data heterogeneity. Most of the approaches proposed for fair classification require diverse data that represent the different demographic groups involved. In contrast, it is common for each client to own data that represents only a single demographic group. Hence the existing approaches cannot be adopted for fair classification models at the client level. To resolve this challenge, we propose several aggregation techniques. We empirically validate these techniques by comparing the resulting fairness metrics and accuracy on CelebA, UTK, and FairFace datasets.
Federated Learning Meets Fairness and Differential Privacy
Aug 23, 2021
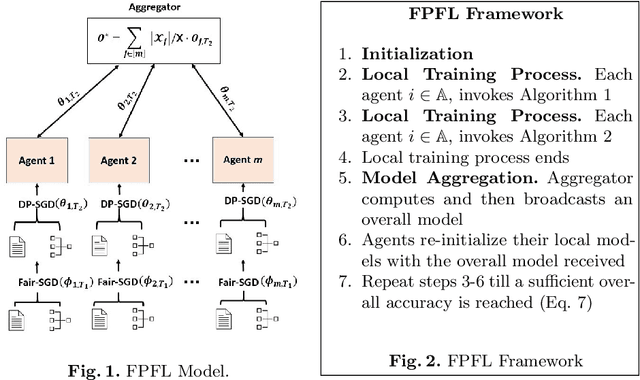
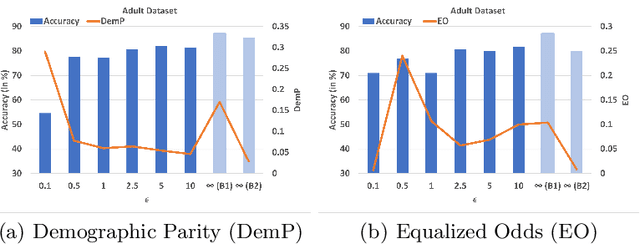
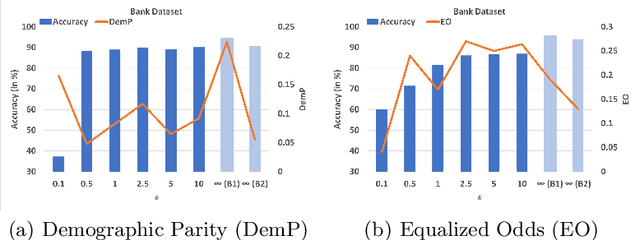
Deep learning's unprecedented success raises several ethical concerns ranging from biased predictions to data privacy. Researchers tackle these issues by introducing fairness metrics, or federated learning, or differential privacy. A first, this work presents an ethical federated learning model, incorporating all three measures simultaneously. Experiments on the Adult, Bank and Dutch datasets highlight the resulting ``empirical interplay" between accuracy, fairness, and privacy.