 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness and Privacy Guarantees in Federated Contextual Bandits
Feb 05, 2024This paper considers the contextual multi-armed bandit (CMAB) problem with fairness and privacy guarantees in a federated environment. We consider merit-based exposure as the desired fair outcome, which provides exposure to each action in proportion to the reward associated. We model the algorithm's effectiveness using fairness regret, which captures the difference between fair optimal policy and the policy output by the algorithm. Applying fair CMAB algorithm to each agent individually leads to fairness regret linear in the number of agents. We propose that collaborative -- federated learning can be more effective and provide the algorithm Fed-FairX-LinUCB that also ensures differential privacy. The primary challenge in extending the existing privacy framework is designing the communication protocol for communicating required information across agents. A naive protocol can either lead to weaker privacy guarantees or higher regret. We design a novel communication protocol that allows for (i) Sub-linear theoretical bounds on fairness regret for Fed-FairX-LinUCB and comparable bounds for the private counterpart, Priv-FairX-LinUCB (relative to single-agent learning), (ii) Effective use of privacy budget in Priv-FairX-LinUCB. We demonstrate the efficacy of our proposed algorithm with extensive simulations-based experiments. We show that both Fed-FairX-LinUCB and Priv-FairX-LinUCB achieve near-optimal fairness regret.
Differentially Private Federated Combinatorial Bandits with Constraints
Jun 27, 2022
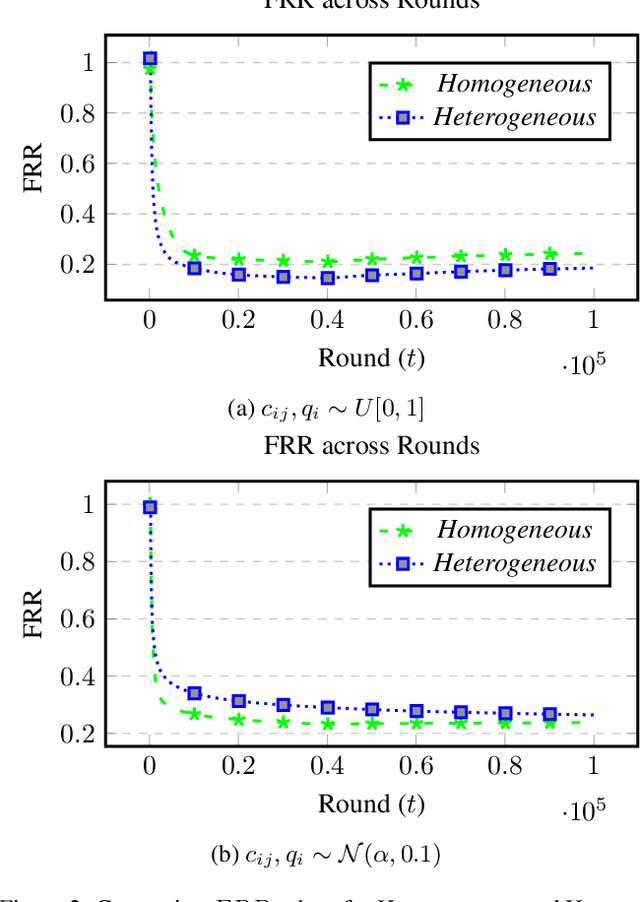
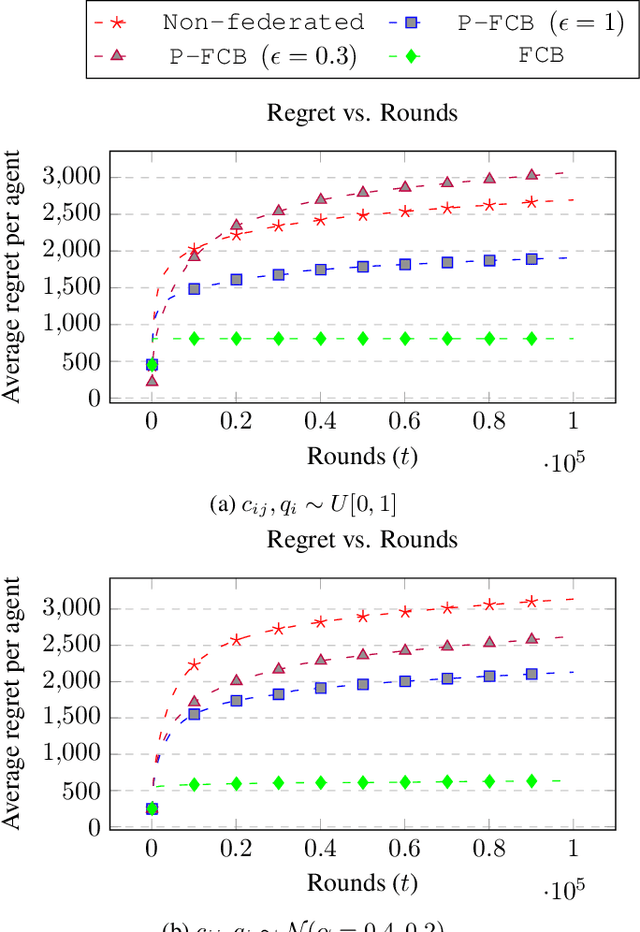

There is a rapid increase in the cooperative learning paradigm in online learning settings, i.e., federated learning (FL). Unlike most FL settings, there are many situations where the agents are competitive. Each agent would like to learn from others, but the part of the information it shares for others to learn from could be sensitive; thus, it desires its privacy. This work investigates a group of agents working concurrently to solve similar combinatorial bandit problems while maintaining quality constraints. Can these agents collectively learn while keeping their sensitive information confidential by employing differential privacy? We observe that communicating can reduce the regret. However, differential privacy techniques for protecting sensitive information makes the data noisy and may deteriorate than help to improve regret. Hence, we note that it is essential to decide when to communicate and what shared data to learn to strike a functional balance between regret and privacy. For such a federated combinatorial MAB setting, we propose a Privacy-preserving Federated Combinatorial Bandit algorithm, P-FCB. We illustrate the efficacy of P-FCB through simulations. We further show that our algorithm provides an improvement in terms of regret while upholding quality threshold and meaningful privacy guarantees.