 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipschitz Dueling Bandits over Continuous Action Spaces
Apr 01, 2026We study for the first time, stochastic dueling bandits over continuous action spaces with Lipschitz structure, where feedback is purely comparative. While dueling bandits and Lipschitz bandits have been studied separately, their combination has remained unexplored. We propose the first algorithm for Lipschitz dueling bandits, using round-based exploration and recursive region elimination guided by an adaptive reference arm. We develop new analytical tools for relative feedback and prove a regret bound of $\tilde O\left(T^{\frac{d_z+1}{d_z+2}}\right)$, where $d_z$ is the zooming dimension of the near-optimal region. Further, our algorithm takes only logarithmic space in terms of the total time horizon, best achievable by any bandit algorithm over a continuous action space.
Multi-Agent Combinatorial-Multi-Armed-Bandit framework for the Submodular Welfare Problem under Bandit Feedback
Feb 18, 2026We study the \emph{Submodular Welfare Problem} (SWP), where items are partitioned among agents with monotone submodular utilities to maximize the total welfare under \emph{bandit feedback}. Classical SWP assumes full value-oracle access, achieving $(1-1/e)$ approximations via continuous-greedy algorithms. We extend this to a \emph{multi-agent combinatorial bandit} framework (\textsc{MA-CMAB}), where actions are partitions under full-bandit feedback with non-communicating agents. Unlike prior single-agent or separable multi-agent CMAB models, our setting couples agents through shared allocation constraints. We propose an explore-then-commit strategy with randomized assignments, achieving $\tilde{\mathcal{O}}(T^{2/3})$ regret against a $(1-1/e)$ benchmark, the first such guarantee for partition-based submodular welfare problem under bandit feedback.
Cooperative SGD with Dynamic Mixing Matrices
Aug 21, 2025One of the most common methods to train machine learning algorithms today is the stochastic gradient descent (SGD). In a distributed setting, SGD-based algorithms have been shown to converge theoretically under specific circumstances. A substantial number of works in the distributed SGD setting assume a fixed topology for the edge devices. These papers also assume that the contribution of nodes to the global model is uniform. However, experiments have shown that such assumptions are suboptimal and a non uniform aggregation strategy coupled with a dynamically shifting topology and client selection can significantly improve the performance of such models. This paper details a unified framework that covers several Local-Update SGD-based distributed algorithms with dynamic topologies and provides improved or matching theoretical guarantees on convergence compared to existing work.
Bi-Criteria Optimization for Combinatorial Bandits: Sublinear Regret and Constraint Violation under Bandit Feedback
Mar 15, 2025In this paper, we study bi-criteria optimization for combinatorial multi-armed bandits (CMAB) with bandit feedback. We propose a general framework that transforms discrete bi-criteria offline approximation algorithms into online algorithms with sublinear regret and cumulative constraint violation (CCV) guarantees. Our framework requires the offline algorithm to provide an $(\alpha, \beta)$-bi-criteria approximation ratio with $\delta$-resilience and utilize $\texttt{N}$ oracle calls to evaluate the objective and constraint functions. We prove that the proposed framework achieves sub-linear regret and CCV, with both bounds scaling as ${O}\left(\delta^{2/3} \texttt{N}^{1/3}T^{2/3}\log^{1/3}(T)\right)$. Crucially, the framework treats the offline algorithm with $\delta$-resilience as a black box, enabling flexible integration of existing approximation algorithms into the CMAB setting. To demonstrate its versatility, we apply our framework to several combinatorial problems, including submodular cover, submodular cost covering, and fair submodular maximization. These applications highlight the framework's broad utility in adapting offline guarantees to online bi-criteria optimization under bandit feedback.
Fair Federated Data Clustering through Personalization: Bridging the Gap between Diverse Data Distributions
Jul 05, 2024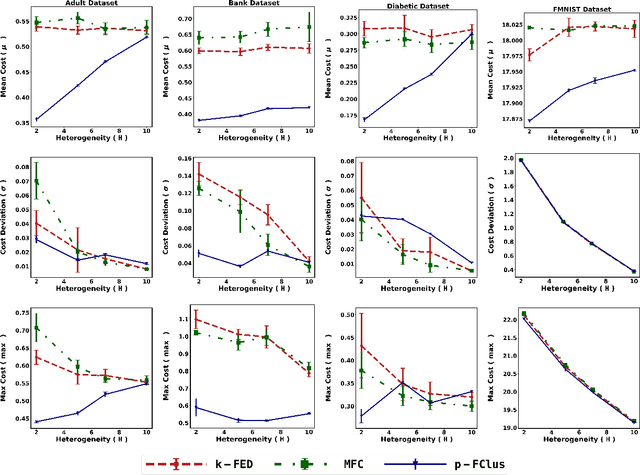
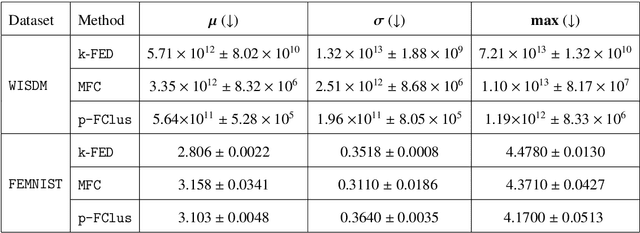
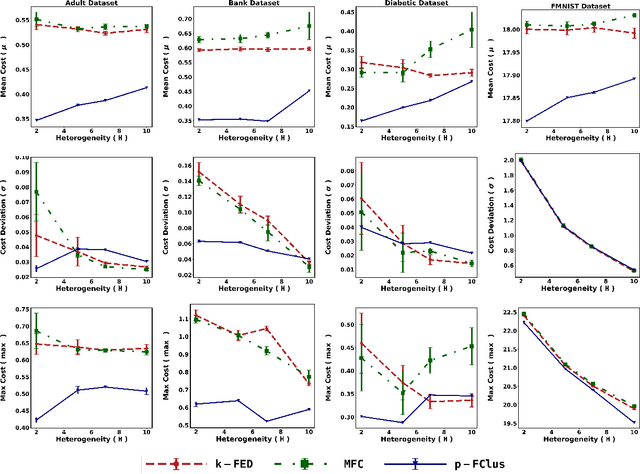
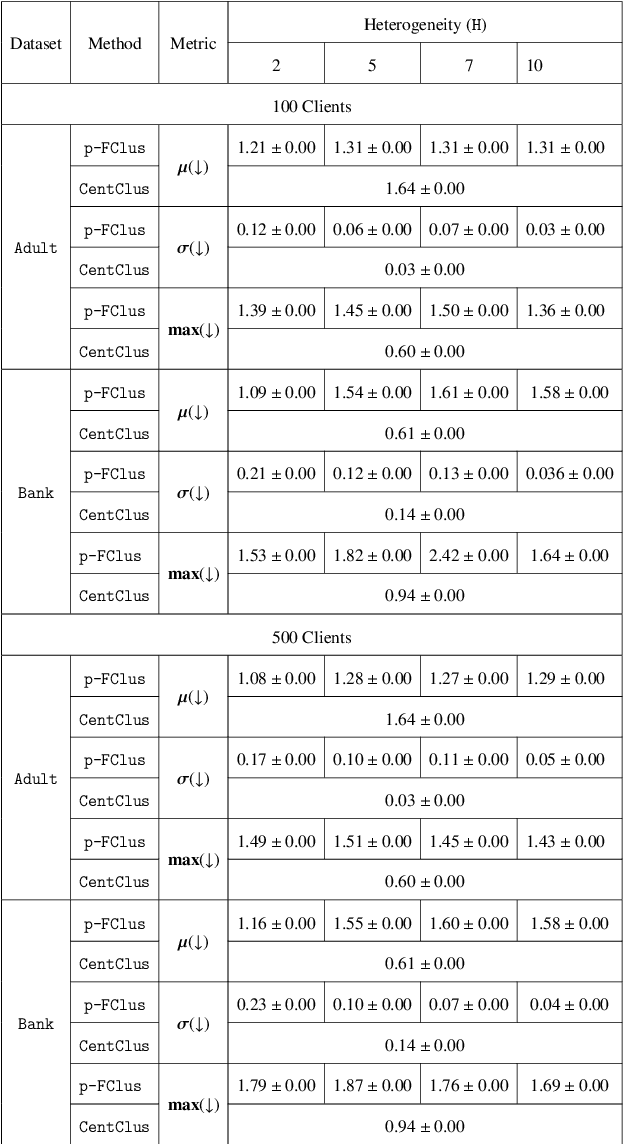
The rapid growth of data from edge devices has catalyzed the performance of machine learning algorithms. However, the data generated resides at client devices thus there are majorly two challenge faced by traditional machine learning paradigms - centralization of data for training and secondly for most the generated data the class labels are missing and there is very poor incentives to clients to manually label their data owing to high cost and lack of expertise. To overcome these issues, there have been initial attempts to handle unlabelled data in a privacy preserving distributed manner using unsupervised federated data clustering. The goal is partition the data available on clients into $k$ partitions (called clusters) without actual exchange of data. Most of the existing algorithms are highly dependent on data distribution patterns across clients or are computationally expensive. Furthermore, due to presence of skewed nature of data across clients in most of practical scenarios existing models might result in clients suffering high clustering cost making them reluctant to participate in federated process. To this, we are first to introduce the idea of personalization in federated clustering. The goal is achieve balance between achieving lower clustering cost and at same time achieving uniform cost across clients. We propose p-FClus that addresses these goal in a single round of communication between server and clients. We validate the efficacy of p-FClus against variety of federated datasets showcasing it's data independence nature, applicability to any finite $\ell$-norm, while simultaneously achieving lower cost and variance.
Fairness of Exposure in Online Restless Multi-armed Bandits
Feb 09, 2024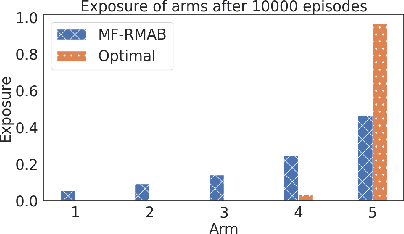


Restless multi-armed bandits (RMABs) generalize the multi-armed bandits where each arm exhibits Markovian behavior and transitions according to their transition dynamics. Solutions to RMAB exist for both offline and online cases. However, they do not consider the distribution of pulls among the arms. Studies have shown that optimal policies lead to unfairness, where some arms are not exposed enough. Existing works in fairness in RMABs focus heavily on the offline case, which diminishes their application in real-world scenarios where the environment is largely unknown. In the online scenario, we propose the first fair RMAB framework, where each arm receives pulls in proportion to its merit. We define the merit of an arm as a function of its stationary reward distribution. We prove that our algorithm achieves sublinear fairness regret in the single pull case $O(\sqrt{T\ln T})$, with $T$ being the total number of episodes. Empirically, we show that our algorithm performs well in the multi-pull scenario as well.
Simultaneously Achieving Group Exposure Fairness and Within-Group Meritocracy in Stochastic Bandits
Feb 08, 2024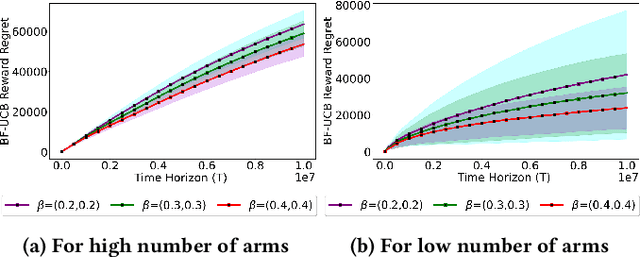
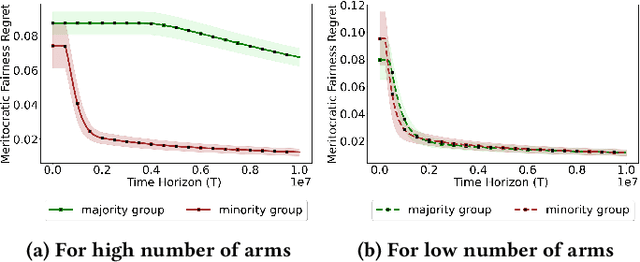
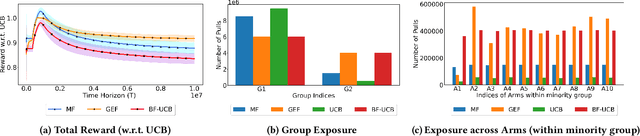
Existing approaches to fairness in stochastic multi-armed bandits (MAB) primarily focus on exposure guarantee to individual arms. When arms are naturally grouped by certain attribute(s), we propose Bi-Level Fairness, which considers two levels of fairness. At the first level, Bi-Level Fairness guarantees a certain minimum exposure to each group. To address the unbalanced allocation of pulls to individual arms within a group, we consider meritocratic fairness at the second level, which ensures that each arm is pulled according to its merit within the group. Our work shows that we can adapt a UCB-based algorithm to achieve a Bi-Level Fairness by providing (i) anytime Group Exposure Fairness guarantees and (ii) ensuring individual-level Meritocratic Fairness within each group. We first show that one can decompose regret bounds into two components: (a) regret due to anytime group exposure fairness and (b) regret due to meritocratic fairness within each group. Our proposed algorithm BF-UCB balances these two regrets optimally to achieve the upper bound of $O(\sqrt{T})$ on regret; $T$ being the stopping time. With the help of simulated experiments, we further show that BF-UCB achieves sub-linear regret; provides better group and individual exposure guarantees compared to existing algorithms; and does not result in a significant drop in reward with respect to UCB algorithm, which does not impose any fairness constraint.
Fairness and Privacy Guarantees in Federated Contextual Bandits
Feb 05, 2024This paper considers the contextual multi-armed bandit (CMAB) problem with fairness and privacy guarantees in a federated environment. We consider merit-based exposure as the desired fair outcome, which provides exposure to each action in proportion to the reward associated. We model the algorithm's effectiveness using fairness regret, which captures the difference between fair optimal policy and the policy output by the algorithm. Applying fair CMAB algorithm to each agent individually leads to fairness regret linear in the number of agents. We propose that collaborative -- federated learning can be more effective and provide the algorithm Fed-FairX-LinUCB that also ensures differential privacy. The primary challenge in extending the existing privacy framework is designing the communication protocol for communicating required information across agents. A naive protocol can either lead to weaker privacy guarantees or higher regret. We design a novel communication protocol that allows for (i) Sub-linear theoretical bounds on fairness regret for Fed-FairX-LinUCB and comparable bounds for the private counterpart, Priv-FairX-LinUCB (relative to single-agent learning), (ii) Effective use of privacy budget in Priv-FairX-LinUCB. We demonstrate the efficacy of our proposed algorithm with extensive simulations-based experiments. We show that both Fed-FairX-LinUCB and Priv-FairX-LinUCB achieve near-optimal fairness regret.
A Novel Demand Response Model and Method for Peak Reduction in Smart Grids -- PowerTAC
Feb 24, 2023One of the widely used peak reduction methods in smart grids is demand response, where one analyzes the shift in customers' (agents') usage patterns in response to the signal from the distribution company. Often, these signals are in the form of incentives offered to agents. This work studies the effect of incentives on the probabilities of accepting such offers in a real-world smart grid simulator, PowerTAC. We first show that there exists a function that depicts the probability of an agent reducing its load as a function of the discounts offered to them. We call it reduction probability (RP). RP function is further parametrized by the rate of reduction (RR), which can differ for each agent. We provide an optimal algorithm, MJS--ExpResponse, that outputs the discounts to each agent by maximizing the expected reduction under a budget constraint. When RRs are unknown, we propose a Multi-Armed Bandit (MAB) based online algorithm, namely MJSUCB--ExpResponse, to learn RRs. Experimentally we show that it exhibits sublinear regret. Finally, we showcase the efficacy of the proposed algorithm in mitigating demand peaks in a real-world smart grid system using the PowerTAC simulator as a test bed.
Budgeted Combinatorial Multi-Armed Bandits
Feb 13, 2022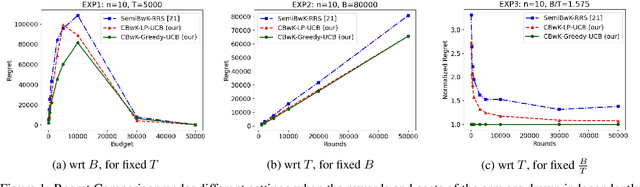
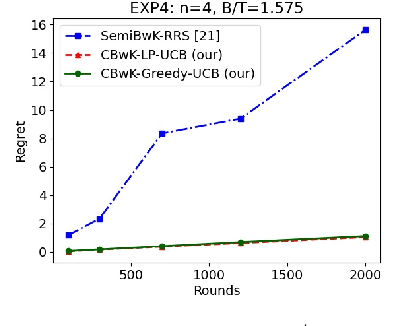
We consider a budgeted combinatorial multi-armed bandit setting where, in every round, the algorithm selects a super-arm consisting of one or more arms. The goal is to minimize the total expected regret after all rounds within a limited budget. Existing techniques in this literature either fix the budget per round or fix the number of arms pulled in each round. Our setting is more general where based on the remaining budget and remaining number of rounds, the algorithm can decide how many arms to be pulled in each round. First, we propose CBwK-Greedy-UCB algorithm, which uses a greedy technique, CBwK-Greedy, to allocate the arms to the rounds. Next, we propose a reduction of this problem to Bandits with Knapsacks (BwK) with a single pull. With this reduction, we propose CBwK-LPUCB that uses PrimalDualBwK ingeniously. We rigorously prove regret bounds for CBwK-LP-UCB. We experimentally compare the two algorithms and observe that CBwK-Greedy-UCB performs incrementally better than CBwK-LP-UCB. We also show that for very high budgets, the regret goes to zero.