 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Criteria Optimization for Combinatorial Bandits: Sublinear Regret and Constraint Violation under Bandit Feedback
Mar 15, 2025In this paper, we study bi-criteria optimization for combinatorial multi-armed bandits (CMAB) with bandit feedback. We propose a general framework that transforms discrete bi-criteria offline approximation algorithms into online algorithms with sublinear regret and cumulative constraint violation (CCV) guarantees. Our framework requires the offline algorithm to provide an $(\alpha, \beta)$-bi-criteria approximation ratio with $\delta$-resilience and utilize $\texttt{N}$ oracle calls to evaluate the objective and constraint functions. We prove that the proposed framework achieves sub-linear regret and CCV, with both bounds scaling as ${O}\left(\delta^{2/3} \texttt{N}^{1/3}T^{2/3}\log^{1/3}(T)\right)$. Crucially, the framework treats the offline algorithm with $\delta$-resilience as a black box, enabling flexible integration of existing approximation algorithms into the CMAB setting. To demonstrate its versatility, we apply our framework to several combinatorial problems, including submodular cover, submodular cost covering, and fair submodular maximization. These applications highlight the framework's broad utility in adapting offline guarantees to online bi-criteria optimization under bandit feedback.
Simultaneously Achieving Group Exposure Fairness and Within-Group Meritocracy in Stochastic Bandits
Feb 08, 2024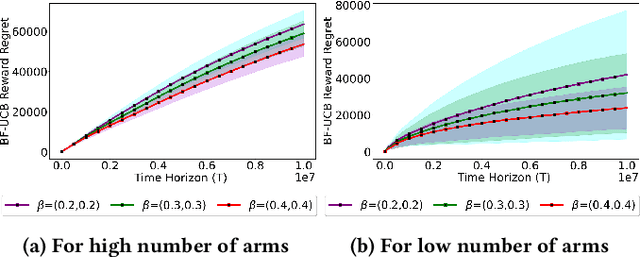
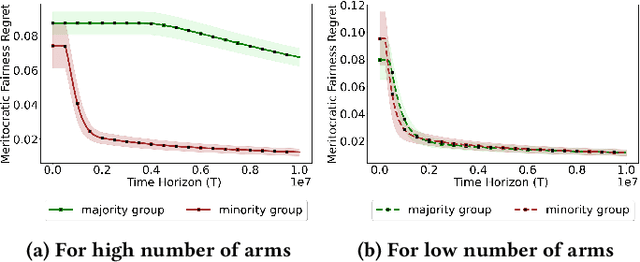
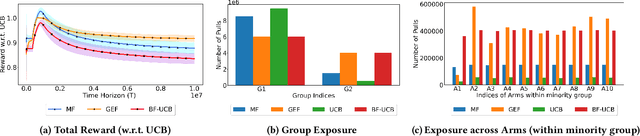
Existing approaches to fairness in stochastic multi-armed bandits (MAB) primarily focus on exposure guarantee to individual arms. When arms are naturally grouped by certain attribute(s), we propose Bi-Level Fairness, which considers two levels of fairness. At the first level, Bi-Level Fairness guarantees a certain minimum exposure to each group. To address the unbalanced allocation of pulls to individual arms within a group, we consider meritocratic fairness at the second level, which ensures that each arm is pulled according to its merit within the group. Our work shows that we can adapt a UCB-based algorithm to achieve a Bi-Level Fairness by providing (i) anytime Group Exposure Fairness guarantees and (ii) ensuring individual-level Meritocratic Fairness within each group. We first show that one can decompose regret bounds into two components: (a) regret due to anytime group exposure fairness and (b) regret due to meritocratic fairness within each group. Our proposed algorithm BF-UCB balances these two regrets optimally to achieve the upper bound of $O(\sqrt{T})$ on regret; $T$ being the stopping time. With the help of simulated experiments, we further show that BF-UCB achieves sub-linear regret; provides better group and individual exposure guarantees compared to existing algorithms; and does not result in a significant drop in reward with respect to UCB algorithm, which does not impose any fairness constraint.