 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness of Exposure in Online Restless Multi-armed Bandits
Paper and Code
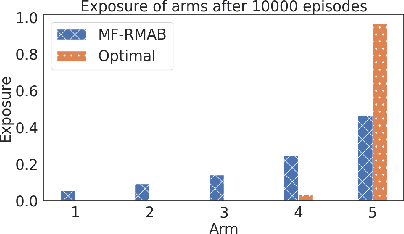


Restless multi-armed bandits (RMABs) generalize the multi-armed bandits where each arm exhibits Markovian behavior and transitions according to their transition dynamics. Solutions to RMAB exist for both offline and online cases. However, they do not consider the distribution of pulls among the arms. Studies have shown that optimal policies lead to unfairness, where some arms are not exposed enough. Existing works in fairness in RMABs focus heavily on the offline case, which diminishes their application in real-world scenarios where the environment is largely unknown. In the online scenario, we propose the first fair RMAB framework, where each arm receives pulls in proportion to its merit. We define the merit of an arm as a function of its stationary reward distribution. We prove that our algorithm achieves sublinear fairness regret in the single pull case $O(\sqrt{T\ln T})$, with $T$ being the total number of episodes. Empirically, we show that our algorithm performs well in the multi-pull scenario as well.