 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Federated Data Clustering through Personalization: Bridging the Gap between Diverse Data Distributions
Paper and Code
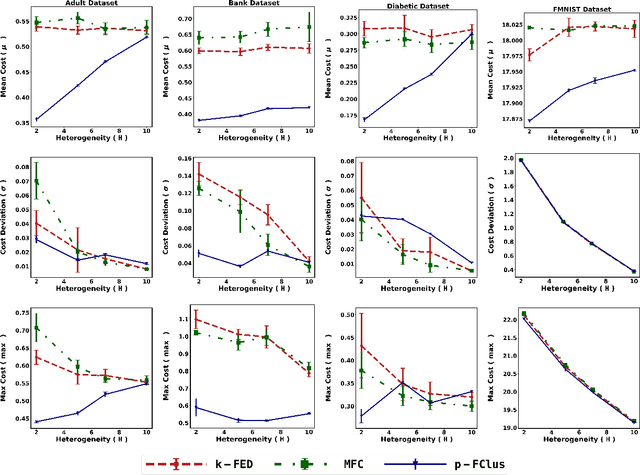
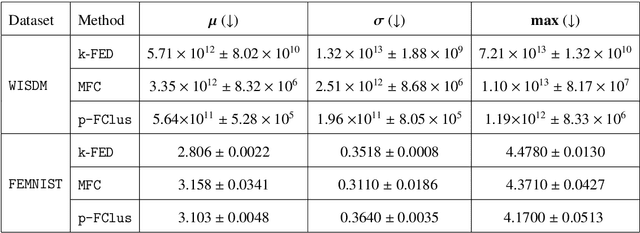
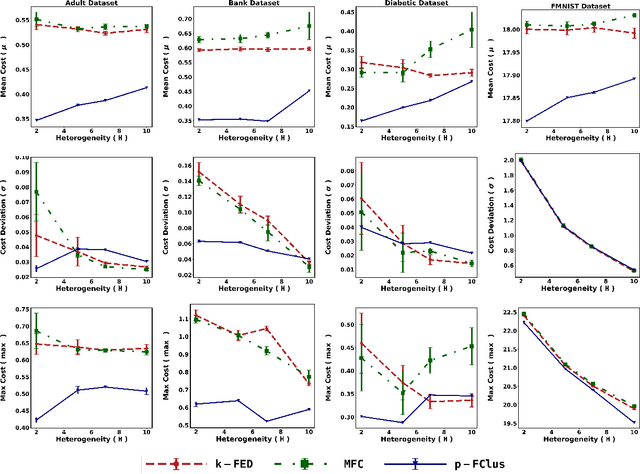
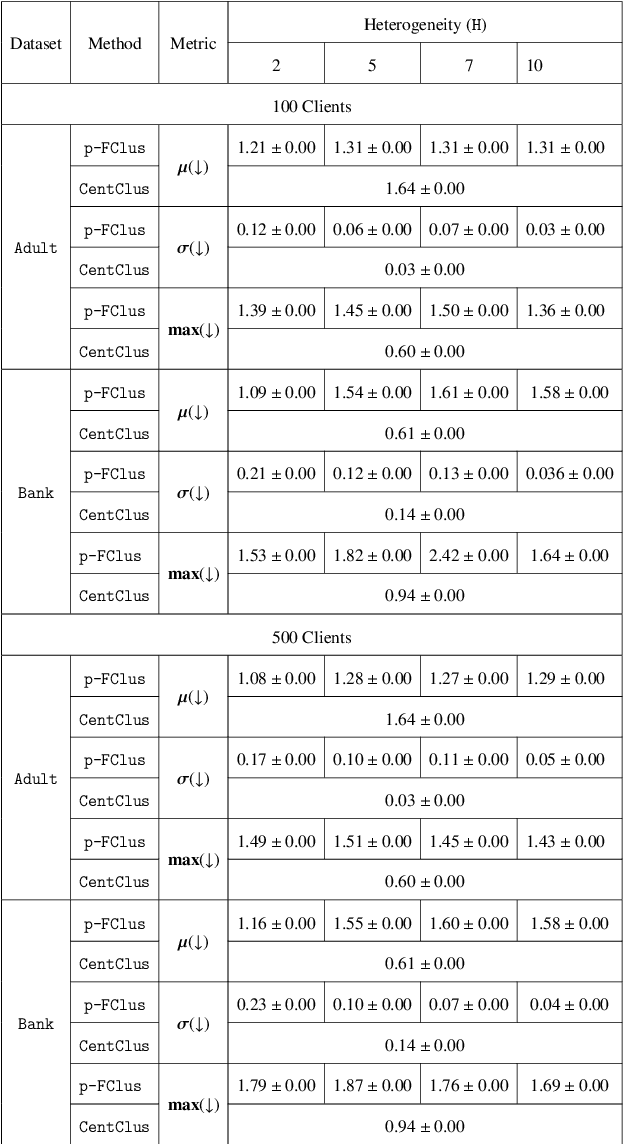
The rapid growth of data from edge devices has catalyzed the performance of machine learning algorithms. However, the data generated resides at client devices thus there are majorly two challenge faced by traditional machine learning paradigms - centralization of data for training and secondly for most the generated data the class labels are missing and there is very poor incentives to clients to manually label their data owing to high cost and lack of expertise. To overcome these issues, there have been initial attempts to handle unlabelled data in a privacy preserving distributed manner using unsupervised federated data clustering. The goal is partition the data available on clients into $k$ partitions (called clusters) without actual exchange of data. Most of the existing algorithms are highly dependent on data distribution patterns across clients or are computationally expensive. Furthermore, due to presence of skewed nature of data across clients in most of practical scenarios existing models might result in clients suffering high clustering cost making them reluctant to participate in federated process. To this, we are first to introduce the idea of personalization in federated clustering. The goal is achieve balance between achieving lower clustering cost and at same time achieving uniform cost across clients. We propose p-FClus that addresses these goal in a single round of communication between server and clients. We validate the efficacy of p-FClus against variety of federated datasets showcasing it's data independence nature, applicability to any finite $\ell$-norm, while simultaneously achieving lower cost and variance.