 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Highly Configurable Hardware/Software Stack for DNN Inference Acceleration
Nov 29, 2021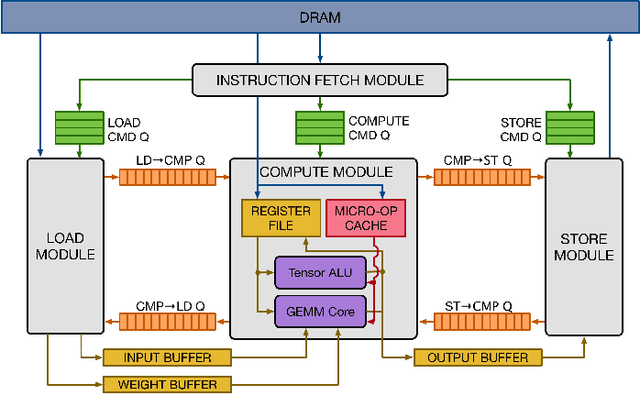
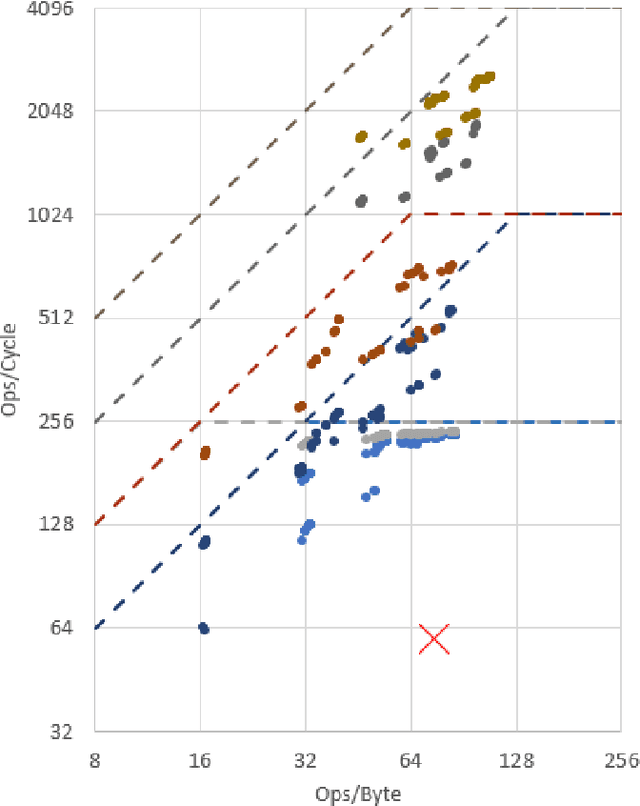
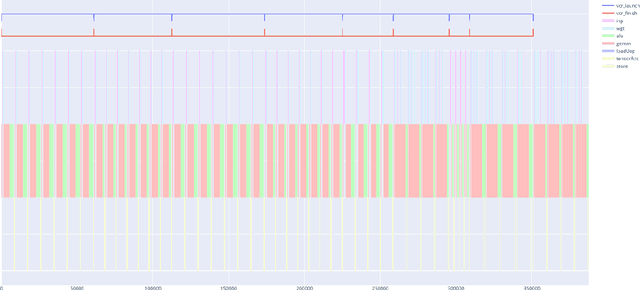
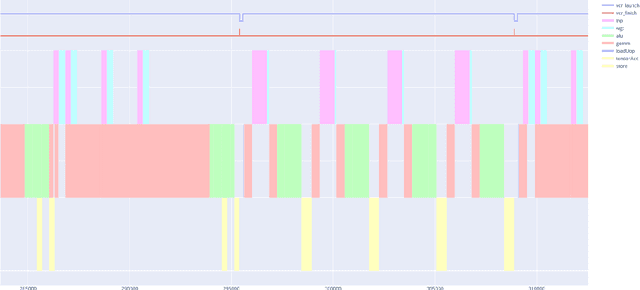
This work focuses on an efficient Agile design methodology for domain-specific accelerators. We employ feature-by-feature enhancement of a vertical development stack and apply it to the TVM/VTA inference accelerator. We have enhanced the VTA design space and enabled end-to-end support for additional workloads. This has been accomplished by augmenting the VTA micro-architecture and instruction set architecture (ISA), as well as by enhancing the TVM compilation stack to support a wide range of VTA configs. The VTA tsim implementation (CHISEL-based) has been enhanced with fully pipelined versions of the ALU/GEMM execution units. In tsim, memory width can now range between 8-64 bytes. Field widths have been made more flexible to support larger scratchpads. New instructions have been added: element-wise 8-bit multiplication to support depthwise convolution, and load with a choice of pad values to support max pooling. Support for more layers and better double buffering has also been added. Fully pipelining ALU/GEMM helps significantly: 4.9x fewer cycles with minimal area change to run ResNet-18 under the default config. Configs featuring a further 11.5x decrease in cycle count at a cost of 12x greater area can be instantiated. Many points on the area-performance pareto curve are shown, showcasing the balance of execution unit sizing, memory interface width, and scratchpad sizing. Finally, VTA is now able to run Mobilenet 1.0 and all layers for ResNets, including the previously disabled pooling and fully connected layers. The TVM/VTA architecture has always featured end-to-end workload evaluation on RTL in minutes. With our modifications, it now offers a much greater number of feasible configurations with a wide range of cost vs. performance. All capabilities mentioned are available in opensource forks while a subset of these capabilities have already been upstreamed.
RHNAS: Realizable Hardware and Neural Architecture Search
Jun 17, 2021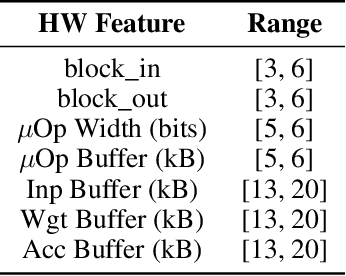
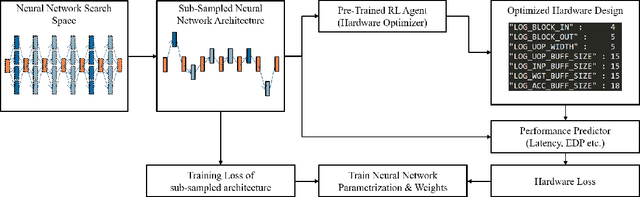
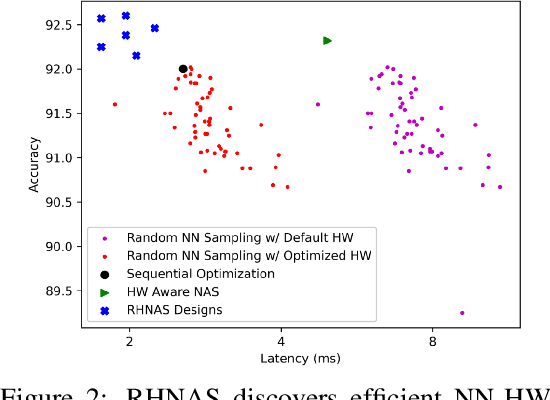

The rapidly evolving field of Artificial Intelligence necessitates automated approaches to co-design neural network architecture and neural accelerators to maximize system efficiency and address productivity challenges. To enable joint optimization of this vast space, there has been growing interest in differentiable NN-HW co-design. Fully differentiable co-design has reduced the resource requirements for discovering optimized NN-HW configurations, but fail to adapt to general hardware accelerator search spaces. This is due to the existence of non-synthesizable (invalid) designs in the search space of many hardware accelerators. To enable efficient and realizable co-design of configurable hardware accelerators with arbitrary neural network search spaces, we introduce RHNAS. RHNAS is a method that combines reinforcement learning for hardware optimization with differentiable neural architecture search. RHNAS discovers realizable NN-HW designs with 1.84x lower latency and 1.86x lower energy-delay product (EDP) on ImageNet and 2.81x lower latency and 3.30x lower EDP on CIFAR-10 over the default hardware accelerator design.