 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-LLM Thematic Analysis with Dual Reliability Metrics: Combining Cohen's Kappa and Semantic Similarity for Qualitative Research Validation
Dec 23, 2025Qualitative research faces a critical reliability challenge: traditional inter-rater agreement methods require multiple human coders, are time-intensive, and often yield moderate consistency. We present a multi-perspective validation framework for LLM-based thematic analysis that combines ensemble validation with dual reliability metrics: Cohen's Kappa ($κ$) for inter-rater agreement and cosine similarity for semantic consistency. Our framework enables configurable analysis parameters (1-6 seeds, temperature 0.0-2.0), supports custom prompt structures with variable substitution, and provides consensus theme extraction across any JSON format. As proof-of-concept, we evaluate three leading LLMs (Gemini 2.5 Pro, GPT-4o, Claude 3.5 Sonnet) on a psychedelic art therapy interview transcript, conducting six independent runs per model. Results demonstrate Gemini achieves highest reliability ($κ= 0.907$, cosine=95.3%), followed by GPT-4o ($κ= 0.853$, cosine=92.6%) and Claude ($κ= 0.842$, cosine=92.1%). All three models achieve a high agreement ($κ> 0.80$), validating the multi-run ensemble approach. The framework successfully extracts consensus themes across runs, with Gemini identifying 6 consensus themes (50-83% consistency), GPT-4o identifying 5 themes, and Claude 4 themes. Our open-source implementation provides researchers with transparent reliability metrics, flexible configuration, and structure-agnostic consensus extraction, establishing methodological foundations for reliable AI-assisted qualitative research.
ContraGS: Codebook-Condensed and Trainable Gaussian Splatting for Fast, Memory-Efficient Reconstruction
Sep 03, 20253D Gaussian Splatting (3DGS) is a state-of-art technique to model real-world scenes with high quality and real-time rendering. Typically, a higher quality representation can be achieved by using a large number of 3D Gaussians. However, using large 3D Gaussian counts significantly increases the GPU device memory for storing model parameters. A large model thus requires powerful GPUs with high memory capacities for training and has slower training/rendering latencies due to the inefficiencies of memory access and data movement. In this work, we introduce ContraGS, a method to enable training directly on compressed 3DGS representations without reducing the Gaussian Counts, and thus with a little loss in model quality. ContraGS leverages codebooks to compactly store a set of Gaussian parameter vectors throughout the training process, thereby significantly reducing memory consumption. While codebooks have been demonstrated to be highly effective at compressing fully trained 3DGS models, directly training using codebook representations is an unsolved challenge. ContraGS solves the problem of learning non-differentiable parameters in codebook-compressed representations by posing parameter estimation as a Bayesian inference problem. To this end, ContraGS provides a framework that effectively uses MCMC sampling to sample over a posterior distribution of these compressed representations. With ContraGS, we demonstrate that ContraGS significantly reduces the peak memory during training (on average 3.49X) and accelerated training and rendering (1.36X and 1.88X on average, respectively), while retraining close to state-of-art quality.
TokenButler: Token Importance is Predictable
Mar 10, 2025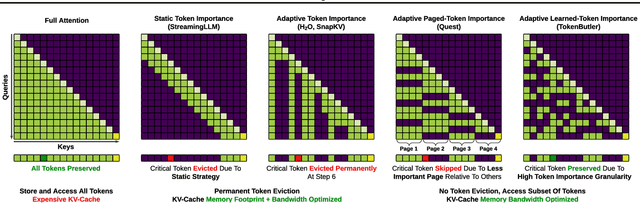
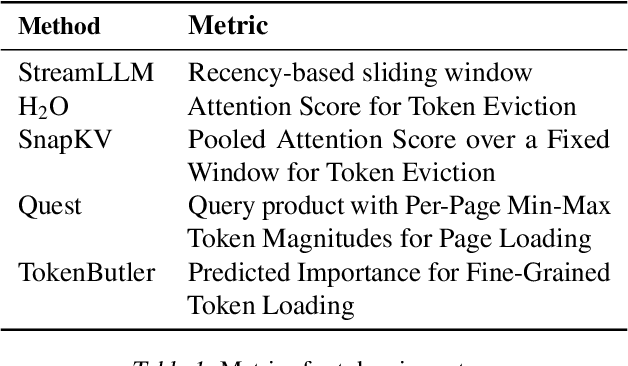
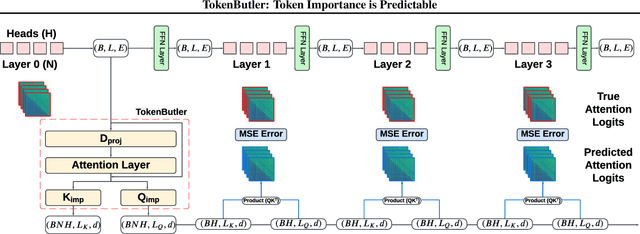
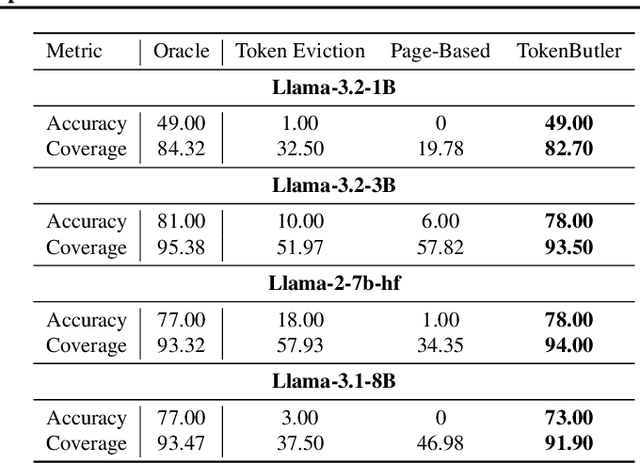
Large Language Models (LLMs) rely on the Key-Value (KV) Cache to store token history, enabling efficient decoding of tokens. As the KV-Cache grows, it becomes a major memory and computation bottleneck, however, there is an opportunity to alleviate this bottleneck, especially because prior research has shown that only a small subset of tokens contribute meaningfully to each decoding step. A key challenge in finding these critical tokens is that they are dynamic, and heavily input query-dependent. Existing methods either risk quality by evicting tokens permanently, or retain the full KV-Cache but rely on retrieving chunks (pages) of tokens at generation, failing at dense, context-rich tasks. Additionally, many existing KV-Cache sparsity methods rely on inaccurate proxies for token importance. To address these limitations, we introduce TokenButler, a high-granularity, query-aware predictor that learns to identify these critical tokens. By training a light-weight predictor with less than 1.2% parameter overhead, TokenButler prioritizes tokens based on their contextual, predicted importance. This improves perplexity & downstream accuracy by over 8% relative to SoTA methods for estimating token importance. We evaluate TokenButler on a novel synthetic small-context co-referential retrieval task, demonstrating near-oracle accuracy. Code, models and benchmarks: https://github.com/abdelfattah-lab/TokenButler
SparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025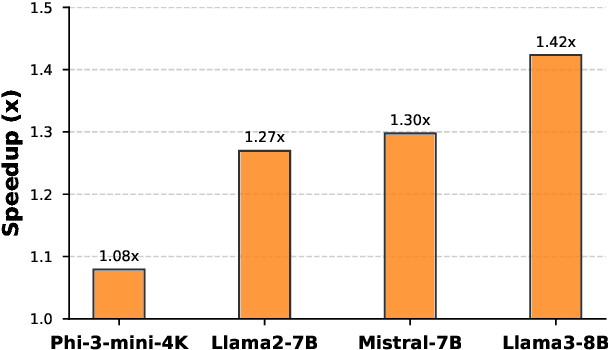

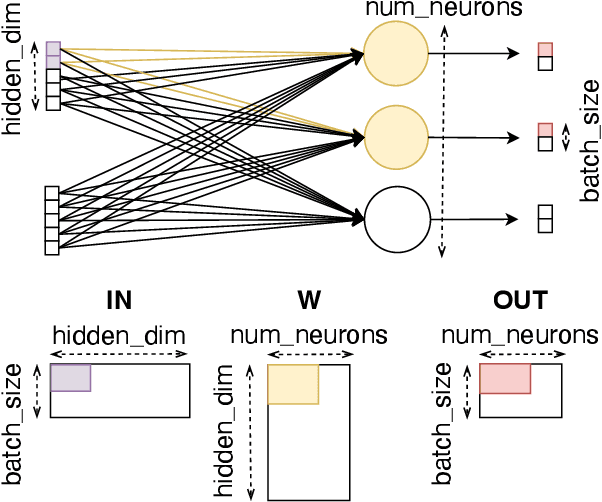
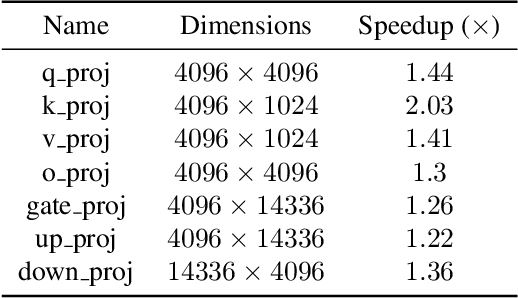
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
Mamba-Shedder: Post-Transformer Compression for Efficient Selective Structured State Space Models
Jan 28, 2025



Large pre-trained models have achieved outstanding results in sequence modeling. The Transformer block and its attention mechanism have been the main drivers of the success of these models. Recently, alternative architectures, such as Selective Structured State Space Models (SSMs), have been proposed to address the inefficiencies of Transformers. This paper explores the compression of SSM-based models, particularly Mamba and its hybrids. We study the sensitivity of these models to the removal of selected components at different granularities to reduce the model size and computational overhead, thus improving their efficiency while maintaining accuracy. The proposed solutions, collectively referred to as Mamba-Shedder, achieve a speedup of up to 1.4x during inference, demonstrating that model efficiency can be improved by eliminating several redundancies with minimal impact on the overall model performance. The code is available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
INRet: A General Framework for Accurate Retrieval of INRs for Shapes
Jan 27, 2025



Implicit neural representations (INRs) have become an important method for encoding various data types, such as 3D objects or scenes, images, and videos. They have proven to be particularly effective at representing 3D content, e.g., 3D scene reconstruction from 2D images, novel 3D content creation, as well as the representation, interpolation, and completion of 3D shapes. With the widespread generation of 3D data in an INR format, there is a need to support effective organization and retrieval of INRs saved in a data store. A key aspect of retrieval and clustering of INRs in a data store is the formulation of similarity between INRs that would, for example, enable retrieval of similar INRs using a query INR. In this work, we propose INRet, a method for determining similarity between INRs that represent shapes, thus enabling accurate retrieval of similar shape INRs from an INR data store. INRet flexibly supports different INR architectures such as INRs with octree grids, triplanes, and hash grids, as well as different implicit functions including signed/unsigned distance function and occupancy field. We demonstrate that our method is more general and accurate than the existing INR retrieval method, which only supports simple MLP INRs and requires the same architecture between the query and stored INRs. Furthermore, compared to converting INRs to other representations (e.g., point clouds or multi-view images) for 3D shape retrieval, INRet achieves higher accuracy while avoiding the conversion overhead.
MultiPruner: Balanced Structure Removal in Foundation Models
Jan 17, 2025



Recently, state-of-the-art approaches for pruning large pre-trained models (LPMs) have demonstrated that the training-free removal of non-critical residual blocks in Transformers is viable for reducing model size, achieving results that outperform previous training-free pruning approaches. Motivated by these findings, we extend BlockPruner (Zhong et al., 2024) and propose MultiPruner, a pruning approach that surpasses recent training-free pruning methods by adopting a multidimensional, iterative, fine-grained pruning strategy. In MultiPruner, multidimensional pruning reinstates the structural balance in block-pruned models by sequentially compressing along three dimensions: i) residual blocks, ii) channels of multilayer perceptrons (MLP), and iii) attention heads. This solution enhances zero-shot accuracy on downstream tasks compared to other techniques while improving model compression ratios, producing compressed models with fewer computing and memory requirements. Extensive experiments demonstrate the advantages of the proposed method across various large pre-trained models. The code and pruning configurations are available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
Enhancing Data Integrity through Provenance Tracking in Semantic Web Frameworks
Jan 12, 2025



This paper explores the integration of provenance tracking systems within the context of Semantic Web technologies to enhance data integrity in diverse operational environments. SURROUND Australia Pty Ltd demonstrates innovative applica-tions of the PROV Data Model (PROV-DM) and its Semantic Web variant, PROV-O, to systematically record and manage provenance information across multiple data processing domains. By employing RDF and Knowledge Graphs, SURROUND ad-dresses the critical challenges of shared entity identification and provenance granularity. The paper highlights the company's architecture for capturing comprehensive provenance data, en-abling robust validation, traceability, and knowledge inference. Through the examination of two projects, we illustrate how provenance mechanisms not only improve data reliability but also facilitate seamless integration across heterogeneous systems. Our findings underscore the importance of sophisticated provenance solutions in maintaining data integrity, serving as a reference for industry peers and academics engaged in provenance research and implementation.
Post-Training Statistical Calibration for Higher Activation Sparsity
Dec 10, 2024



We present Statistical Calibrated Activation Pruning (SCAP), a post-training activation pruning framework that (1) generalizes sparsification by input activations of Fully-Connected layers for generic and flexible application across Transformers, and (2) features a simple Mode-Centering technique to pre-calibrate activation distributions for maximizing post-training sparsity. Our results demonstrate robust Pareto efficiency compared to prior methods, translating to a 1.5x additional LLM decoding speedup against CATS at iso model quality. SCAP effectiveness is empirically verified across a wide range of models, including recent Transformer Decoders, MoE, Mamba2, Encoding Transformer, and pre-quantized models, highlighting its practicality and scalability. The code is available at: https://github.com/IntelLabs/SCAP.
SQFT: Low-cost Model Adaptation in Low-precision Sparse Foundation Models
Oct 01, 2024Large pre-trained models (LPMs), such as large language models, have become ubiquitous and are employed in many applications. These models are often adapted to a desired domain or downstream task through a fine-tuning stage. This paper proposes SQFT, an end-to-end solution for low-precision sparse parameter-efficient fine-tuning of LPMs, allowing for effective model manipulation in resource-constrained environments. Additionally, an innovative strategy enables the merging of sparse weights with low-rank adapters without losing sparsity and accuracy, overcoming the limitations of previous approaches. SQFT also addresses the challenge of having quantized weights and adapters with different numerical precisions, enabling merging in the desired numerical format without sacrificing accuracy. Multiple adaptation scenarios, models, and comprehensive sparsity levels demonstrate the effectiveness of SQFT. Models and code are available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.