 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Statistical Calibration for Higher Activation Sparsity
Dec 10, 2024



We present Statistical Calibrated Activation Pruning (SCAP), a post-training activation pruning framework that (1) generalizes sparsification by input activations of Fully-Connected layers for generic and flexible application across Transformers, and (2) features a simple Mode-Centering technique to pre-calibrate activation distributions for maximizing post-training sparsity. Our results demonstrate robust Pareto efficiency compared to prior methods, translating to a 1.5x additional LLM decoding speedup against CATS at iso model quality. SCAP effectiveness is empirically verified across a wide range of models, including recent Transformer Decoders, MoE, Mamba2, Encoding Transformer, and pre-quantized models, highlighting its practicality and scalability. The code is available at: https://github.com/IntelLabs/SCAP.
Click-through Rate Prediction with Auto-Quantized Contrastive Learning
Sep 27, 2021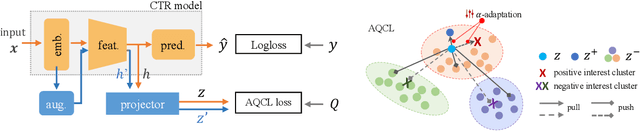
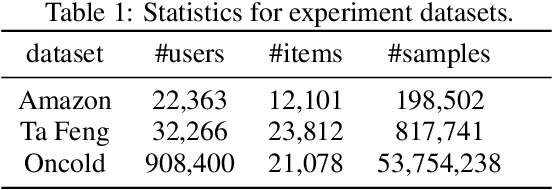
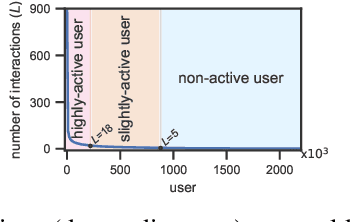
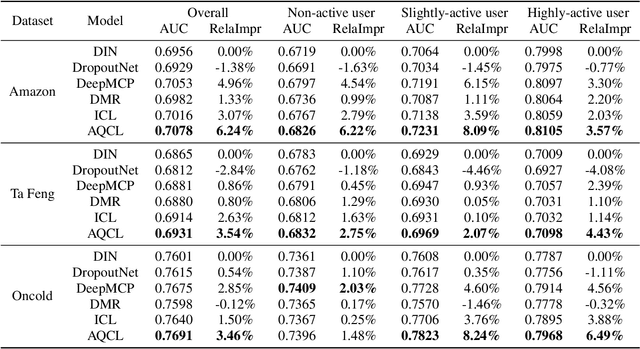
Click-through rate (CTR) prediction becomes indispensable in ubiquitous web recommendation applications. Nevertheless, the current methods are struggling under the cold-start scenarios where the user interactions are extremely sparse. We consider this problem as an automatic identification about whether the user behaviors are rich enough to capture the interests for prediction, and propose an Auto-Quantized Contrastive Learning (AQCL) loss to regularize the model. Different from previous methods, AQCL explores both the instance-instance and the instance-cluster similarity to robustify the latent representation, and automatically reduces the information loss to the active users due to the quantization. The proposed framework is agnostic to different model architectures and can be trained in an end-to-end fashion. Extensive results show that it consistently improves the current state-of-the-art CTR models.