 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 12, 2021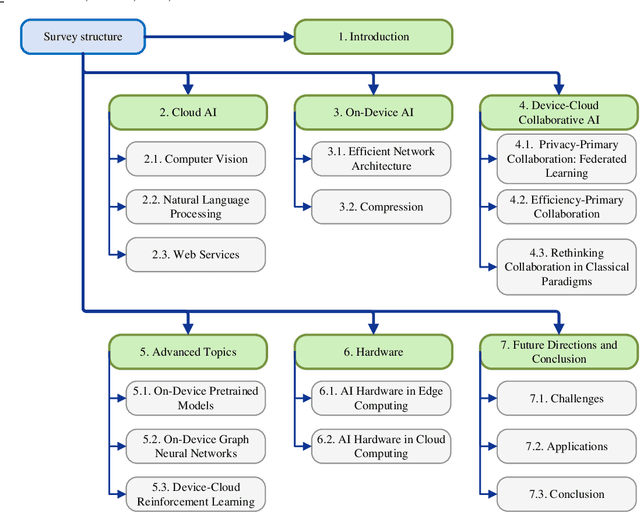
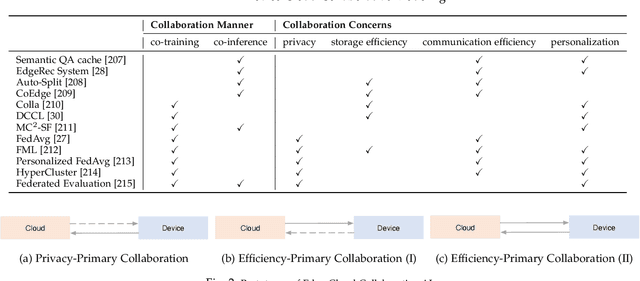
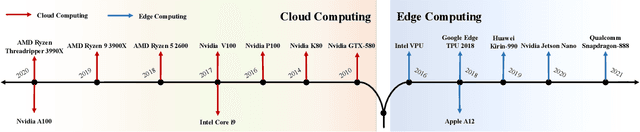
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.
Click-through Rate Prediction with Auto-Quantized Contrastive Learning
Sep 27, 2021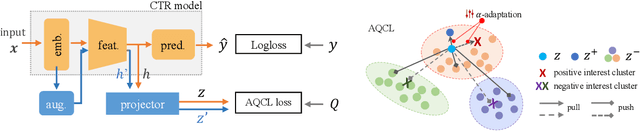
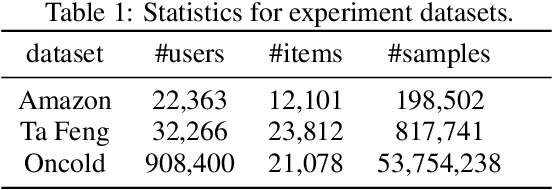
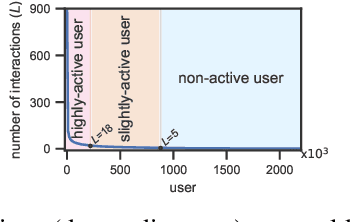
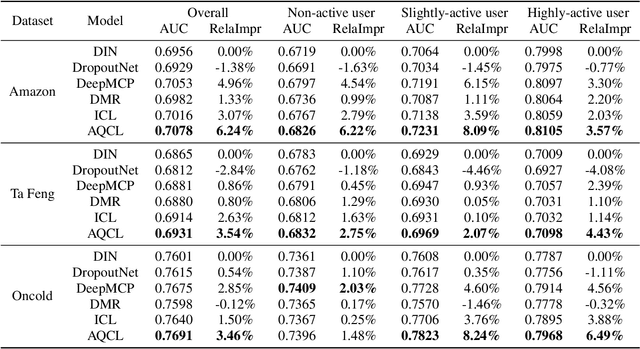
Click-through rate (CTR) prediction becomes indispensable in ubiquitous web recommendation applications. Nevertheless, the current methods are struggling under the cold-start scenarios where the user interactions are extremely sparse. We consider this problem as an automatic identification about whether the user behaviors are rich enough to capture the interests for prediction, and propose an Auto-Quantized Contrastive Learning (AQCL) loss to regularize the model. Different from previous methods, AQCL explores both the instance-instance and the instance-cluster similarity to robustify the latent representation, and automatically reduces the information loss to the active users due to the quantization. The proposed framework is agnostic to different model architectures and can be trained in an end-to-end fashion. Extensive results show that it consistently improves the current state-of-the-art CTR models.
Dynamic Sequential Graph Learning for Click-Through Rate Prediction
Sep 26, 2021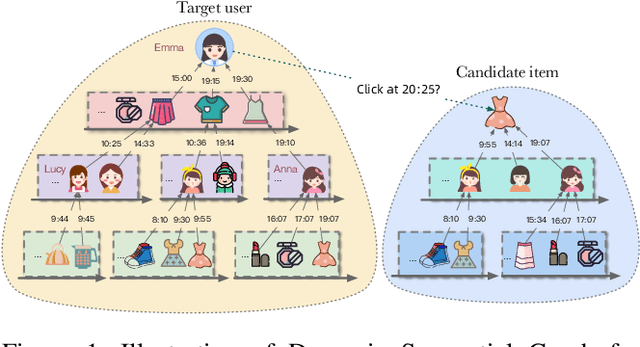
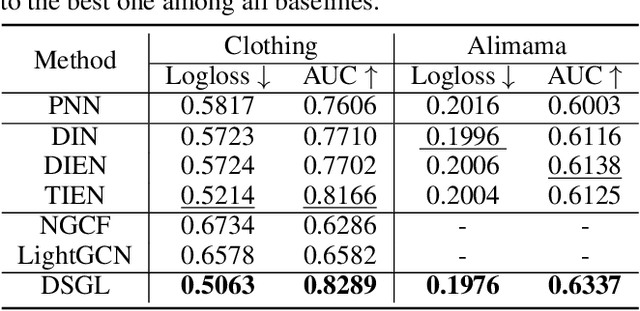
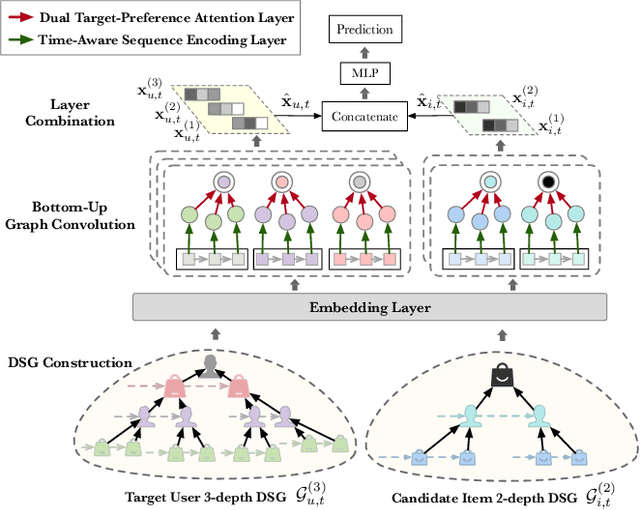
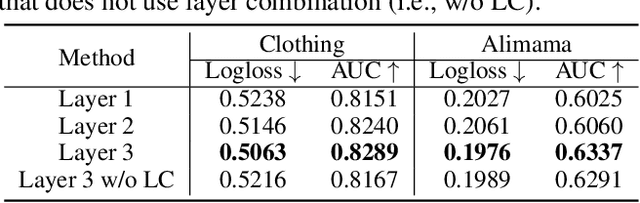
Click-through rate prediction plays an important role in the field of recommender system and many other applications. Existing methods mainly extract user interests from user historical behaviors. However, behavioral sequences only contain users' directly interacted items, which are limited by the system's exposure, thus they are often not rich enough to reflect all the potential interests. In this paper, we propose a novel method, named Dynamic Sequential Graph Learning (DSGL), to enhance users or items' representations by utilizing collaborative information from the local sub-graphs associated with users or items. Specifically, we design the Dynamic Sequential Graph (DSG), i.e., a lightweight ego subgraph with timestamps induced from historical interactions. At every scoring moment, we construct DSGs for the target user and the candidate item respectively. Based on the DSGs, we perform graph convolutional operations iteratively in a bottom-up manner to obtain the final representations of the target user and the candidate item. As for the graph convolution, we design a Time-aware Sequential Encoding Layer that leverages the interaction time information as well as temporal dependencies to learn evolutionary user and item dynamics. Besides, we propose a Target-Preference Dual Attention Layer, composed of a preference-aware attention module and a target-aware attention module, to automatically search for parts of behaviors that are relevant to the target and alleviate the noise from unreliable neighbors. Results on real-world CTR prediction benchmarks demonstrate the improvements brought by DSGL.
MC$^2$-SF: Slow-Fast Learning for Mobile-Cloud Collaborative Recommendation
Sep 25, 2021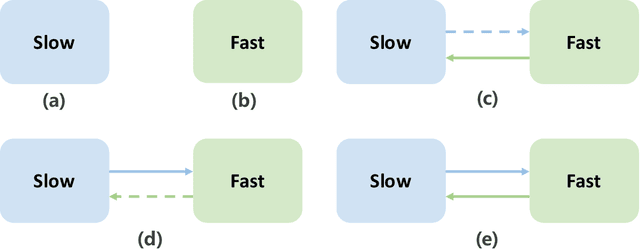
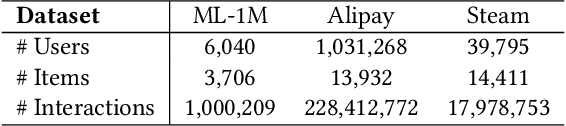
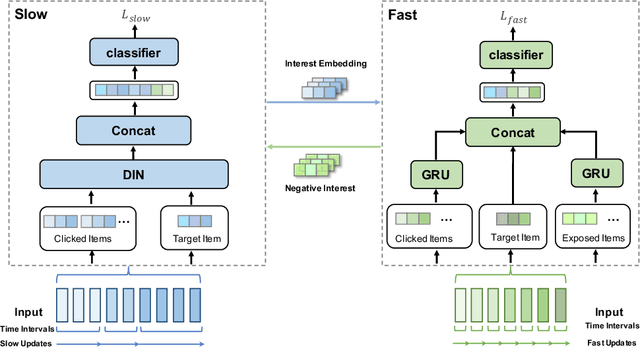
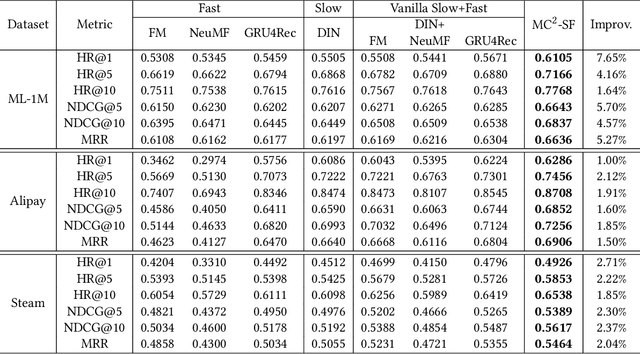
With the hardware development of mobile devices, it is possible to build the recommendation models on the mobile side to utilize the fine-grained features and the real-time feedbacks. Compared to the straightforward mobile-based modeling appended to the cloud-based modeling, we propose a Slow-Fast learning mechanism to make the Mobile-Cloud Collaborative recommendation (MC$^2$-SF) mutual benefit. Specially, in our MC$^2$-SF, the cloud-based model and the mobile-based model are respectively treated as the slow component and the fast component, according to their interaction frequency in real-world scenarios. During training and serving, they will communicate the prior/privileged knowledge to each other to help better capture the user interests about the candidates, resembling the role of System I and System II in the human cognition. We conduct the extensive experiments on three benchmark datasets and demonstrate the proposed MC$^2$-SF outperforms several state-of-the-art methods.
Inductive Granger Causal Modeling for Multivariate Time Series
Feb 10, 2021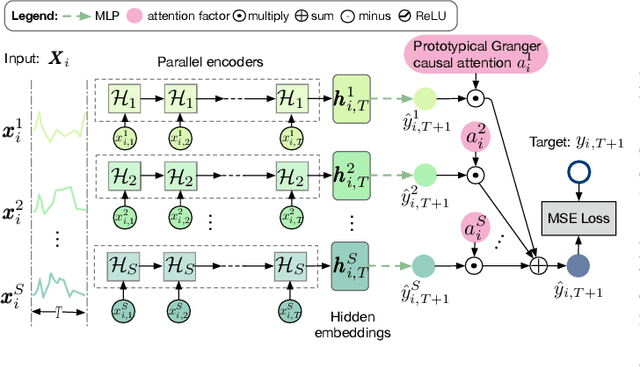
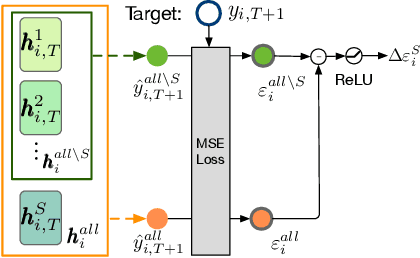

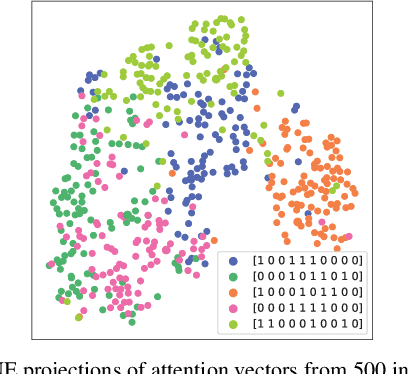
Granger causal modeling is an emerging topic that can uncover Granger causal relationship behind multivariate time series data. In many real-world systems, it is common to encounter a large amount of multivariate time series data collected from different individuals with sharing commonalities. However, there are ongoing concerns regarding Granger causality's applicability in such large scale complex scenarios, presenting both challenges and opportunities for Granger causal structure reconstruction. Existing methods usually train a distinct model for each individual, suffering from inefficiency and over-fitting issues. To bridge this gap, we propose an Inductive GRanger cAusal modeling (InGRA) framework for inductive Granger causality learning and common causal structure detection on multivariate time series, which exploits the shared commonalities underlying the different individuals. In particular, we train one global model for individuals with different Granger causal structures through a novel attention mechanism, called prototypical Granger causal attention. The model can detect common causal structures for different individuals and infer Granger causal structures for newly arrived individuals. Extensive experiments, as well as an online A/B test on an E-commercial advertising platform, demonstrate the superior performances of InGRA.
Bayes EMbedding (BEM): Refining Representation by Integrating Knowledge Graphs and Behavior-specific Networks
Aug 28, 2019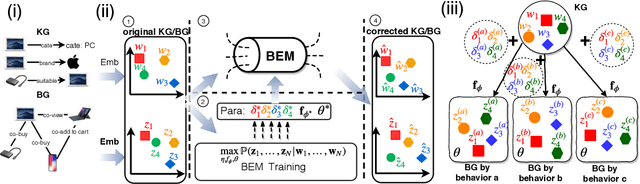

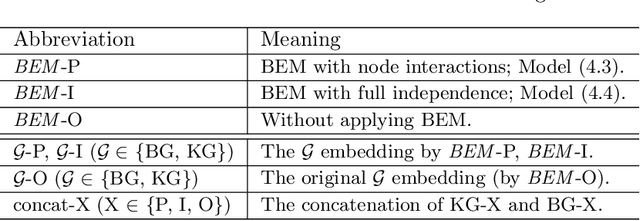
Low-dimensional embeddings of knowledge graphs and behavior graphs have proved remarkably powerful in varieties of tasks, from predicting unobserved edges between entities to content recommendation. The two types of graphs can contain distinct and complementary information for the same entities/nodes. However, previous works focus either on knowledge graph embedding or behavior graph embedding while few works consider both in a unified way. Here we present BEM , a Bayesian framework that incorporates the information from knowledge graphs and behavior graphs. To be more specific, BEM takes as prior the pre-trained embeddings from the knowledge graph, and integrates them with the pre-trained embeddings from the behavior graphs via a Bayesian generative model. BEM is able to mutually refine the embeddings from both sides while preserving their own topological structures. To show the superiority of our method, we conduct a range of experiments on three benchmark datasets: node classification, link prediction, triplet classification on two small datasets related to Freebase, and item recommendation on a large-scale e-commerce dataset.