 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
May 04, 2026We present Mamoda2.5, a unified AR-Diffusion framework that seamlessly integrates multimodal understanding and generation within a single architecture. To efficiently enhance the model's generation capability, we equip the Diffusion Transformer backbone with a fine-grained Mixture-of-Experts (MoE) design (128 experts, Top-8 routing), yielding a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up the model capacity. Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, surpassing evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench. Furthermore, we introduce a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model and greatly accelerates model inference. Compared to open-source baselines, Mamoda2.5 achieves up to $95.9\times$ faster video editing inference. In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in internal advertising video editing scenario.
Construction of Knowledge Graph based on Language Model
Apr 21, 2026Knowledge Graph (KG) can effectively integrate valuable information from massive data, and thus has been rapidly developed and widely used in many fields. Traditional KG construction methods rely on manual annotation, which often consumes a lot of time and manpower. And KG construction schemes based on deep learning tend to have weak generalization capabilities. With the rapid development of Pre-trained Language Models (PLM), PLM has shown great potential in the field of KG construction. This paper provides a comprehensive review of recent research advances in the field of construction of KGs using PLM. In this paper, we explain how PLM can utilize its language understanding and generation capabilities to automatically extract key information for KGs, such as entities and relations, from textual data. In addition, We also propose a new Hyper-Relarional Knowledge Graph construction framework based on lightweight Large Language Model (LLM) named LLHKG and compares it with previous methods. Under our framework, the KG construction capability of lightweight LLM is comparable to GPT3.5.
Seed2Scale: A Self-Evolving Data Engine for Embodied AI via Small to Large Model Synergy and Multimodal Evaluation
Mar 09, 2026Existing data generation methods suffer from exploration limits, embodiment gaps, and low signal-to-noise ratios, leading to performance degradation during self-iteration. To address these challenges, we propose Seed2Scale, a self-evolving data engine that overcomes the data bottleneck through a heterogeneous synergy of "small-model collection, large-model evaluation, and target-model learning". Starting with as few as four seed demonstrations, the engine employs the lightweight Vision-Language-Action model, SuperTiny, as a dedicated collector, leveraging its strong inductive bias for robust exploration in parallel environments. Concurrently, a pre-trained Vision-Language Model is integrated as a Verifer to autonomously perform success/failure judgment and quality scoring for the massive generated trajectories. Seed2Scale effectively mitigates model collapse, ensuring the stability of the self-evolution process. Experimental results demonstrate that Seed2Scale exhibits signifcant scaling potential: as iterations progress, the success rate of the target model shows a robust upward trend, achieving a performance improvement of 131.2%. Furthermore, Seed2Scale signifcantly outperforms existing data augmentation methods, providing a scalable and cost-effective pathway for the large-scale development of Generalist Embodied AI. Project page: https://terminators2025.github.io/Seed2Scale.github.io
Watch Wider and Think Deeper: Collaborative Cross-modal Chain-of-Thought for Complex Visual Reasoning
Jan 04, 2026Multi-modal reasoning requires the seamless integration of visual and linguistic cues, yet existing Chain-of-Thought methods suffer from two critical limitations in cross-modal scenarios: (1) over-reliance on single coarse-grained image regions, and (2) semantic fragmentation between successive reasoning steps. To address these issues, we propose the CoCoT (Collaborative Coross-modal Thought) framework, built upon two key innovations: a) Dynamic Multi-Region Grounding to adaptively detect the most relevant image regions based on the question, and b) Relation-Aware Reasoning to enable multi-region collaboration by iteratively aligning visual cues to form a coherent and logical chain of thought. Through this approach, we construct the CoCoT-70K dataset, comprising 74,691 high-quality samples with multi-region annotations and structured reasoning chains. Extensive experiments demonstrate that CoCoT significantly enhances complex visual reasoning, achieving an average accuracy improvement of 15.4% on LLaVA-1.5 and 4.0% on Qwen2-VL across six challenging benchmarks. The data and code are available at: https://github.com/deer-echo/CoCoT.
You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025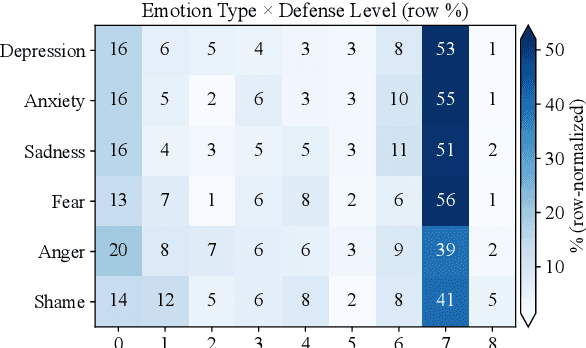
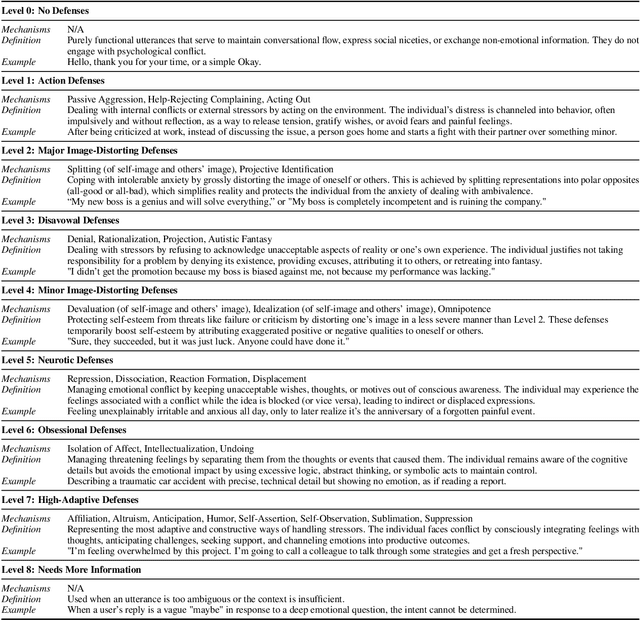
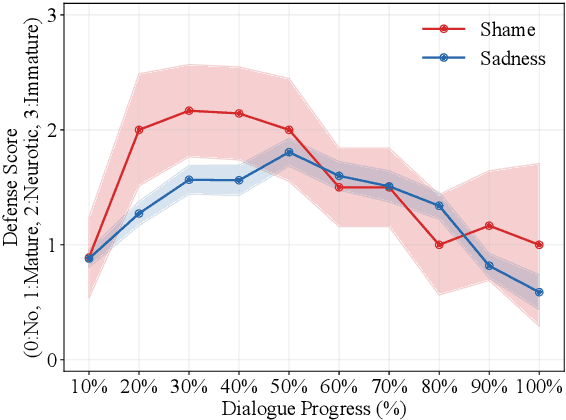
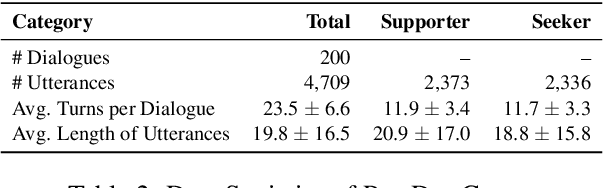
Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
MirrorLimb: Implementing hand pose acquisition and robot teleoperation based on RealMirror
Nov 12, 2025In this work, we present a PICO-based robot remote operating framework that enables low-cost, real-time acquisition of hand motion and pose data, outperforming mainstream visual tracking and motion capture solutions in terms of cost-effectiveness. The framework is natively compatible with the RealMirror ecosystem, offering ready-to-use functionality for stable and precise robotic trajectory recording within the Isaac simulation environment, thereby facilitating the construction of Vision-Language-Action (VLA) datasets. Additionally, the system supports real-time teleoperation of a variety of end-effector-equipped robots, including dexterous hands and robotic grippers. This work aims to lower the technical barriers in the study of upper-limb robotic manipulation, thereby accelerating advancements in VLA-related research.
RealMirror: A Comprehensive, Open-Source Vision-Language-Action Platform for Embodied AI
Sep 18, 2025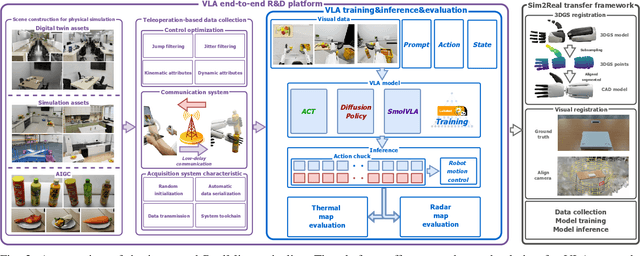
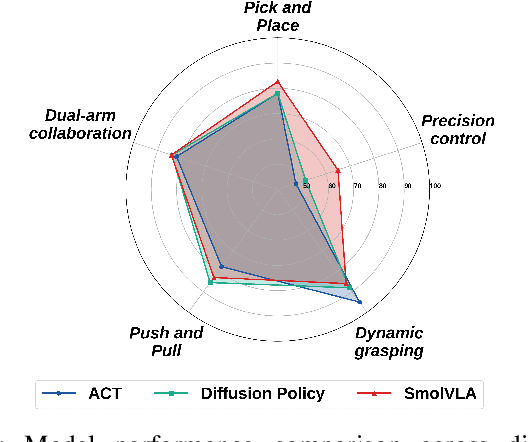
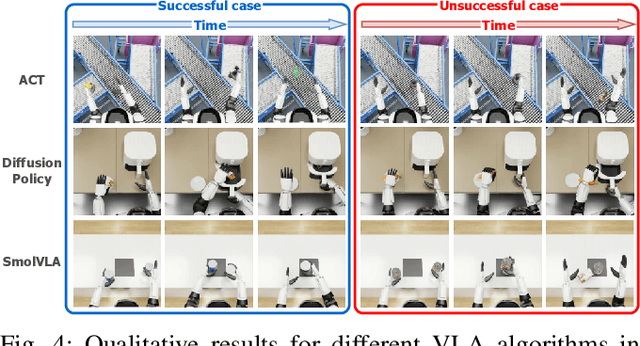

The emerging field of Vision-Language-Action (VLA) for humanoid robots faces several fundamental challenges, including the high cost of data acquisition, the lack of a standardized benchmark, and the significant gap between simulation and the real world. To overcome these obstacles, we propose RealMirror, a comprehensive, open-source embodied AI VLA platform. RealMirror builds an efficient, low-cost data collection, model training, and inference system that enables end-to-end VLA research without requiring a real robot. To facilitate model evolution and fair comparison, we also introduce a dedicated VLA benchmark for humanoid robots, featuring multiple scenarios, extensive trajectories, and various VLA models. Furthermore, by integrating generative models and 3D Gaussian Splatting to reconstruct realistic environments and robot models, we successfully demonstrate zero-shot Sim2Real transfer, where models trained exclusively on simulation data can perform tasks on a real robot seamlessly, without any fine-tuning. In conclusion, with the unification of these critical components, RealMirror provides a robust framework that significantly accelerates the development of VLA models for humanoid robots. Project page: https://terminators2025.github.io/RealMirror.github.io
FedEve: On Bridging the Client Drift and Period Drift for Cross-device Federated Learning
Aug 20, 2025Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model without exposing their private data. Data heterogeneity is a fundamental challenge in FL, which can result in poor convergence and performance degradation. Client drift has been recognized as one of the factors contributing to this issue resulting from the multiple local updates in FedAvg. However, in cross-device FL, a different form of drift arises due to the partial client participation, but it has not been studied well. This drift, we referred as period drift, occurs as participating clients at each communication round may exhibit distinct data distribution that deviates from that of all clients. It could be more harmful than client drift since the optimization objective shifts with every round. In this paper, we investigate the interaction between period drift and client drift, finding that period drift can have a particularly detrimental effect on cross-device FL as the degree of data heterogeneity increases. To tackle these issues, we propose a predict-observe framework and present an instantiated method, FedEve, where these two types of drift can compensate each other to mitigate their overall impact. We provide theoretical evidence that our approach can reduce the variance of model updates. Extensive experiments demonstrate that our method outperforms alternatives on non-iid data in cross-device settings.
Lost in Pronunciation: Detecting Chinese Offensive Language Disguised by Phonetic Cloaking Replacement
Jul 10, 2025Phonetic Cloaking Replacement (PCR), defined as the deliberate use of homophonic or near-homophonic variants to hide toxic intent, has become a major obstacle to Chinese content moderation. While this problem is well-recognized, existing evaluations predominantly rely on rule-based, synthetic perturbations that ignore the creativity of real users. We organize PCR into a four-way surface-form taxonomy and compile \ours, a dataset of 500 naturally occurring, phonetically cloaked offensive posts gathered from the RedNote platform. Benchmarking state-of-the-art LLMs on this dataset exposes a serious weakness: the best model reaches only an F1-score of 0.672, and zero-shot chain-of-thought prompting pushes performance even lower. Guided by error analysis, we revisit a Pinyin-based prompting strategy that earlier studies judged ineffective and show that it recovers much of the lost accuracy. This study offers the first comprehensive taxonomy of Chinese PCR, a realistic benchmark that reveals current detectors' limits, and a lightweight mitigation technique that advances research on robust toxicity detection.
ThinkQE: Query Expansion via an Evolving Thinking Process
Jun 10, 2025Effective query expansion for web search benefits from promoting both exploration and result diversity to capture multiple interpretations and facets of a query. While recent LLM-based methods have improved retrieval performance and demonstrate strong domain generalization without additional training, they often generate narrowly focused expansions that overlook these desiderata. We propose ThinkQE, a test-time query expansion framework addressing this limitation through two key components: a thinking-based expansion process that encourages deeper and comprehensive semantic exploration, and a corpus-interaction strategy that iteratively refines expansions using retrieval feedback from the corpus. Experiments on diverse web search benchmarks (DL19, DL20, and BRIGHT) show ThinkQE consistently outperforms prior approaches, including training-intensive dense retrievers and rerankers.