 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025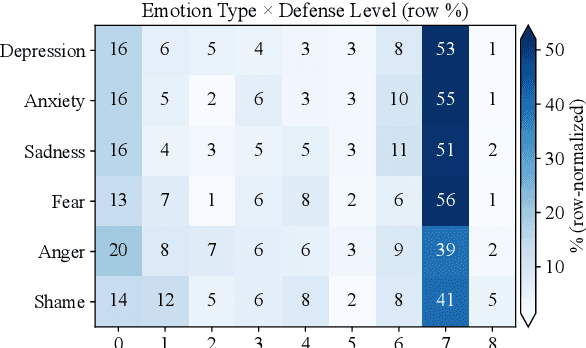
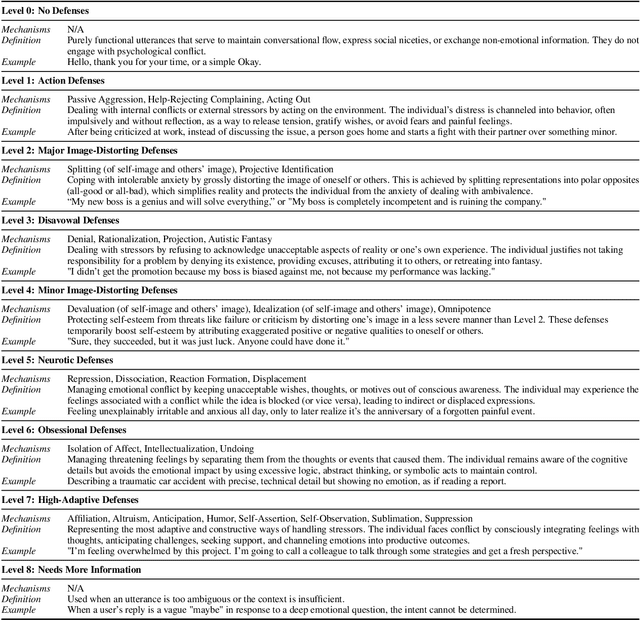
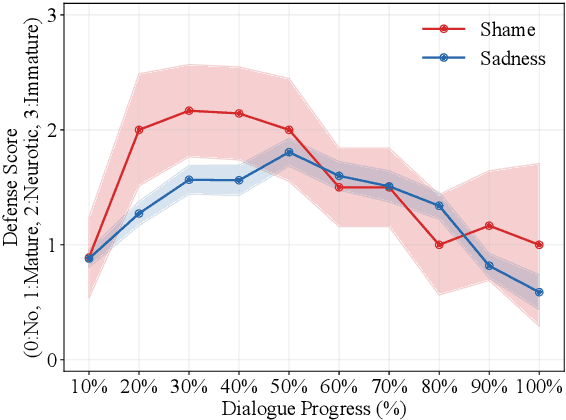
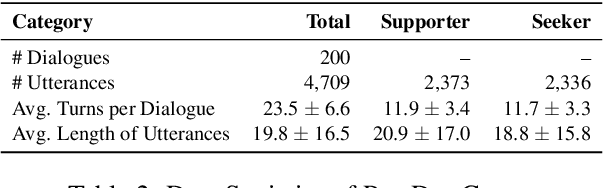
Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
Lost in Pronunciation: Detecting Chinese Offensive Language Disguised by Phonetic Cloaking Replacement
Jul 10, 2025Phonetic Cloaking Replacement (PCR), defined as the deliberate use of homophonic or near-homophonic variants to hide toxic intent, has become a major obstacle to Chinese content moderation. While this problem is well-recognized, existing evaluations predominantly rely on rule-based, synthetic perturbations that ignore the creativity of real users. We organize PCR into a four-way surface-form taxonomy and compile \ours, a dataset of 500 naturally occurring, phonetically cloaked offensive posts gathered from the RedNote platform. Benchmarking state-of-the-art LLMs on this dataset exposes a serious weakness: the best model reaches only an F1-score of 0.672, and zero-shot chain-of-thought prompting pushes performance even lower. Guided by error analysis, we revisit a Pinyin-based prompting strategy that earlier studies judged ineffective and show that it recovers much of the lost accuracy. This study offers the first comprehensive taxonomy of Chinese PCR, a realistic benchmark that reveals current detectors' limits, and a lightweight mitigation technique that advances research on robust toxicity detection.
MineAgent: Towards Remote-Sensing Mineral Exploration with Multimodal Large Language Models
Dec 23, 2024



Remote-sensing mineral exploration is critical for identifying economically viable mineral deposits, yet it poses significant challenges for multimodal large language models (MLLMs). These include limitations in domain-specific geological knowledge and difficulties in reasoning across multiple remote-sensing images, further exacerbating long-context issues. To address these, we present MineAgent, a modular framework leveraging hierarchical judging and decision-making modules to improve multi-image reasoning and spatial-spectral integration. Complementing this, we propose MineBench, a benchmark specific for evaluating MLLMs in domain-specific mineral exploration tasks using geological and hyperspectral data. Extensive experiments demonstrate the effectiveness of MineAgent, highlighting its potential to advance MLLMs in remote-sensing mineral exploration.
Detecting Conversational Mental Manipulation with Intent-Aware Prompting
Dec 11, 2024



Mental manipulation severely undermines mental wellness by covertly and negatively distorting decision-making. While there is an increasing interest in mental health care within the natural language processing community, progress in tackling manipulation remains limited due to the complexity of detecting subtle, covert tactics in conversations. In this paper, we propose Intent-Aware Prompting (IAP), a novel approach for detecting mental manipulations using large language models (LLMs), providing a deeper understanding of manipulative tactics by capturing the underlying intents of participants. Experimental results on the MentalManip dataset demonstrate superior effectiveness of IAP against other advanced prompting strategies. Notably, our approach substantially reduces false negatives, helping detect more instances of mental manipulation with minimal misjudgment of positive cases. The code of this paper is available at https://github.com/Anton-Jiayuan-MA/Manip-IAP.
Guardians of Discourse: Evaluating LLMs on Multilingual Offensive Language Detection
Oct 21, 2024



Identifying offensive language is essential for maintaining safety and sustainability in the social media era. Though large language models (LLMs) have demonstrated encouraging potential in social media analytics, they lack thorough evaluation when in offensive language detection, particularly in multilingual environments. We for the first time evaluate multilingual offensive language detection of LLMs in three languages: English, Spanish, and German with three LLMs, GPT-3.5, Flan-T5, and Mistral, in both monolingual and multilingual settings. We further examine the impact of different prompt languages and augmented translation data for the task in non-English contexts. Furthermore, we discuss the impact of the inherent bias in LLMs and the datasets in the mispredictions related to sensitive topics.
Multi-Session Client-Centered Treatment Outcome Evaluation in Psychotherapy
Oct 08, 2024In psychotherapy, therapeutic outcome assessment, or treatment outcome evaluation, is essential for enhancing mental health care by systematically evaluating therapeutic processes and outcomes. Existing large language model approaches often focus on therapist-centered, single-session evaluations, neglecting the client's subjective experience and longitudinal progress across multiple sessions. To address these limitations, we propose IPAEval, a client-Informed Psychological Assessment-based Evaluation framework that automates treatment outcome evaluations from the client's perspective using clinical interviews. IPAEval integrates cross-session client-contextual assessment and session-focused client-dynamics assessment to provide a comprehensive understanding of therapeutic progress. Experiments on our newly developed TheraPhase dataset demonstrate that IPAEval effectively tracks symptom severity and treatment outcomes over multiple sessions, outperforming previous single-session models and validating the benefits of items-aware reasoning mechanisms.
Applying and Evaluating Large Language Models in Mental Health Care: A Scoping Review of Human-Assessed Generative Tasks
Aug 21, 2024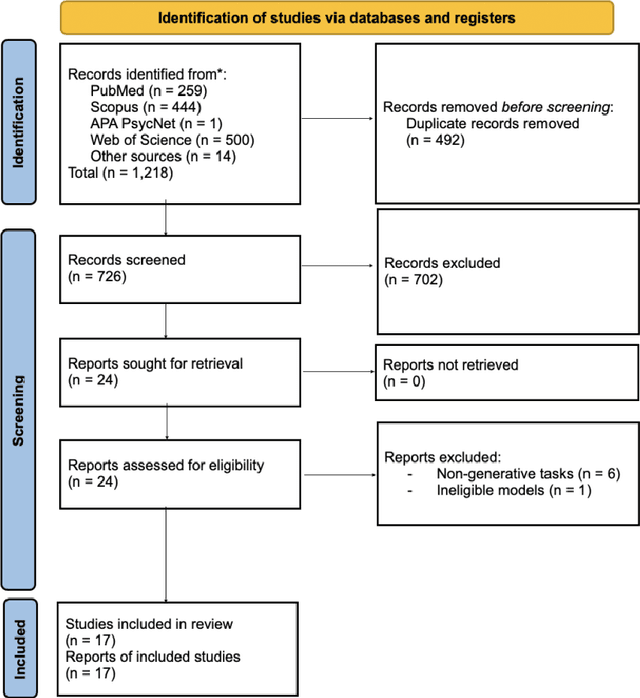


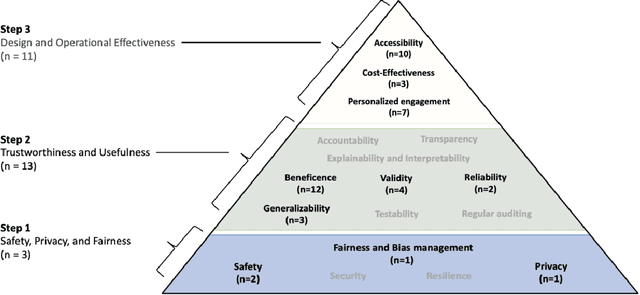
Large language models (LLMs) are emerging as promising tools for mental health care, offering scalable support through their ability to generate human-like responses. However, the effectiveness of these models in clinical settings remains unclear. This scoping review aimed to assess the current generative applications of LLMs in mental health care, focusing on studies where these models were tested with human participants in real-world scenarios. A systematic search across APA PsycNet, Scopus, PubMed, and Web of Science identified 726 unique articles, of which 17 met the inclusion criteria. These studies encompassed applications such as clinical assistance, counseling, therapy, and emotional support. However, the evaluation methods were often non-standardized, with most studies relying on ad hoc scales that limit comparability and robustness. Privacy, safety, and fairness were also frequently underexplored. Moreover, reliance on proprietary models, such as OpenAI's GPT series, raises concerns about transparency and reproducibility. While LLMs show potential in expanding mental health care access, especially in underserved areas, the current evidence does not fully support their use as standalone interventions. More rigorous, standardized evaluations and ethical oversight are needed to ensure these tools can be safely and effectively integrated into clinical practice.
CBT-LLM: A Chinese Large Language Model for Cognitive Behavioral Therapy-based Mental Health Question Answering
Mar 24, 2024



The recent advancements in artificial intelligence highlight the potential of language models in psychological health support. While models trained on data from mental health service platform have achieved preliminary success, challenges persist in areas such as data scarcity, quality, and ensuring a solid foundation in psychological techniques. To address these challenges, this study introduces a novel approach to enhance the precision and efficacy of psychological support through large language models. Specifically, we design a specific prompt derived from principles of Cognitive Behavioral Therapy (CBT) and have generated the CBT QA dataset, specifically for Chinese psychological health Q&A based on CBT structured intervention strategies. Unlike previous methods, our dataset emphasizes professional and structured response. Utilizing this dataset, we fine-tuned the large language model, giving birth to CBT-LLM, the large-scale language model specifically designed for Cognitive Behavioral Therapy techniques. Empirical evaluations demonstrate that CBT-LLM excels in generating structured, professional, and highly relevant responses in psychological health support tasks, showcasing its practicality and quality. The model is available on Hugging Face: https://huggingface.co/Hongbin37/CBT-LLM.
Rethinking Human-like Translation Strategy: Integrating Drift-Diffusion Model with Large Language Models for Machine Translation
Feb 16, 2024
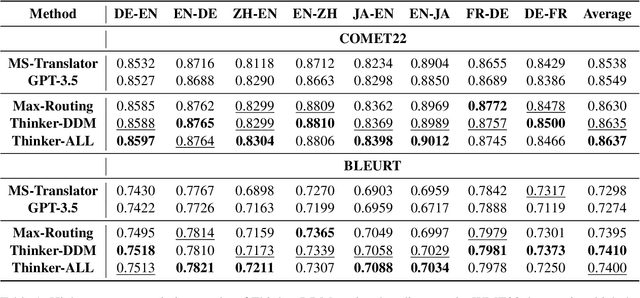
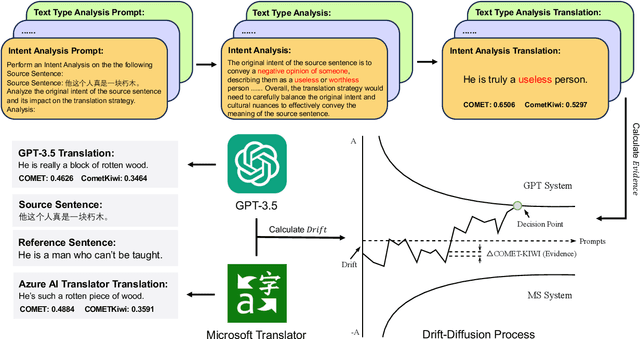
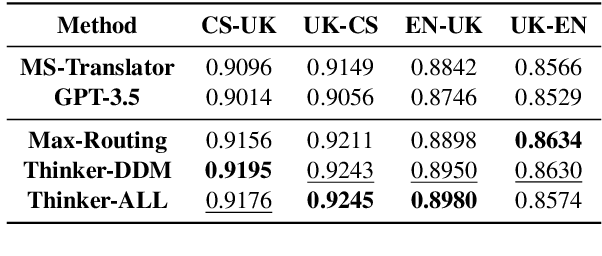
Large language models (LLMs) have demonstrated promising potential in various downstream tasks, including machine translation. However, prior work on LLM-based machine translation has mainly focused on better utilizing training data, demonstrations, or pre-defined and universal knowledge to improve performance, with a lack of consideration of decision-making like human translators. In this paper, we incorporate Thinker with the Drift-Diffusion Model (Thinker-DDM) to address this issue. We then redefine the Drift-Diffusion process to emulate human translators' dynamic decision-making under constrained resources. We conduct extensive experiments under the high-resource, low-resource, and commonsense translation settings using the WMT22 and CommonMT datasets, in which Thinker-DDM outperforms baselines in the first two scenarios. We also perform additional analysis and evaluation on commonsense translation to illustrate the high effectiveness and efficacy of the proposed method.