 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025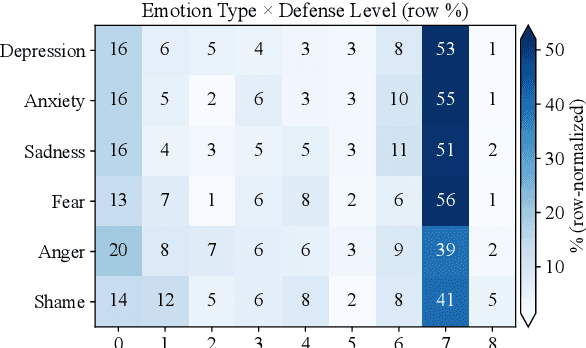
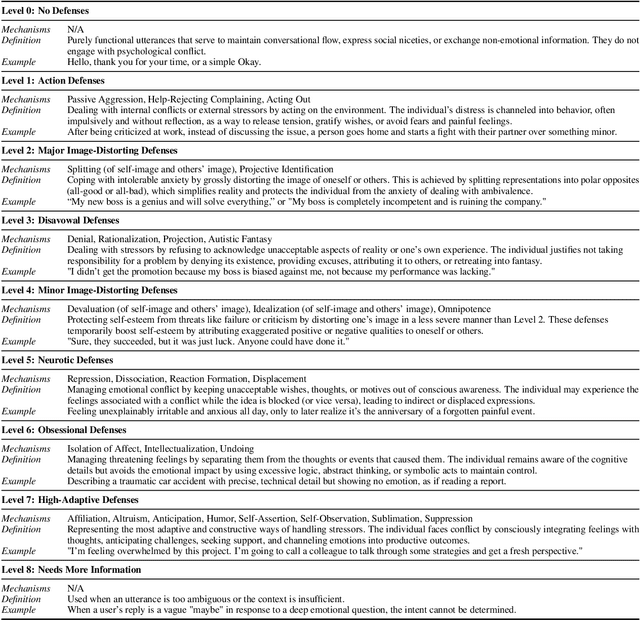
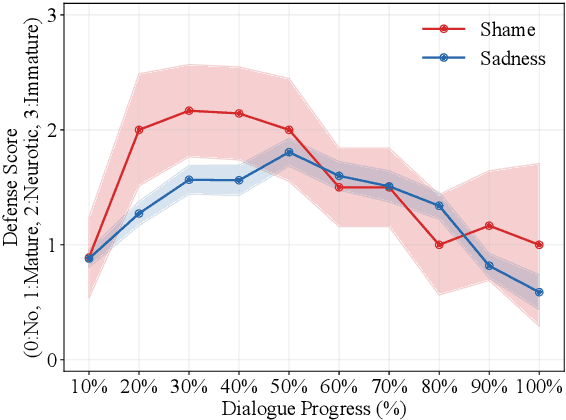
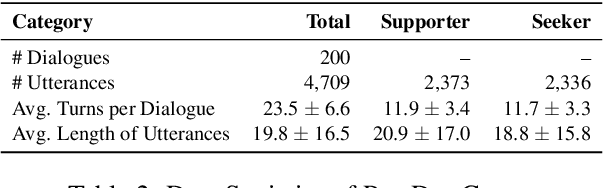
Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
Optimizing Large Language Models for Detecting Symptoms of Comorbid Depression or Anxiety in Chronic Diseases: Insights from Patient Messages
Mar 14, 2025



Patients with diabetes are at increased risk of comorbid depression or anxiety, complicating their management. This study evaluated the performance of large language models (LLMs) in detecting these symptoms from secure patient messages. We applied multiple approaches, including engineered prompts, systemic persona, temperature adjustments, and zero-shot and few-shot learning, to identify the best-performing model and enhance performance. Three out of five LLMs demonstrated excellent performance (over 90% of F-1 and accuracy), with Llama 3.1 405B achieving 93% in both F-1 and accuracy using a zero-shot approach. While LLMs showed promise in binary classification and handling complex metrics like Patient Health Questionnaire-4, inconsistencies in challenging cases warrant further real-life assessment. The findings highlight the potential of LLMs to assist in timely screening and referrals, providing valuable empirical knowledge for real-world triage systems that could improve mental health care for patients with chronic diseases.
Applying and Evaluating Large Language Models in Mental Health Care: A Scoping Review of Human-Assessed Generative Tasks
Aug 21, 2024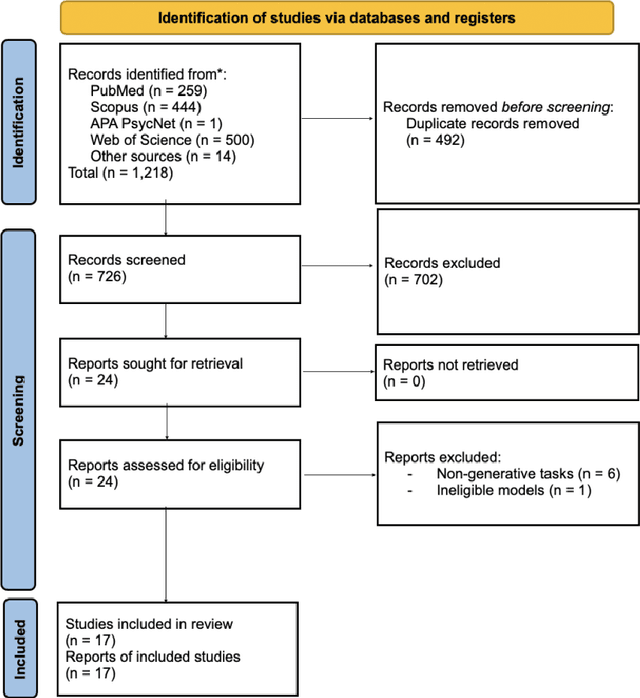


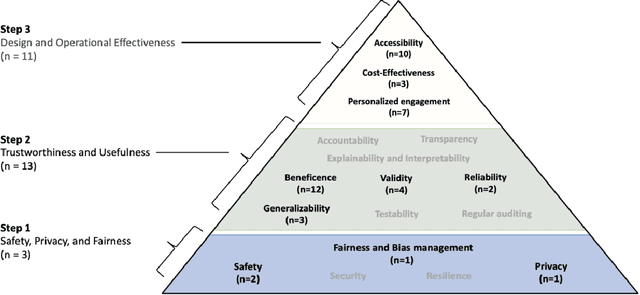
Large language models (LLMs) are emerging as promising tools for mental health care, offering scalable support through their ability to generate human-like responses. However, the effectiveness of these models in clinical settings remains unclear. This scoping review aimed to assess the current generative applications of LLMs in mental health care, focusing on studies where these models were tested with human participants in real-world scenarios. A systematic search across APA PsycNet, Scopus, PubMed, and Web of Science identified 726 unique articles, of which 17 met the inclusion criteria. These studies encompassed applications such as clinical assistance, counseling, therapy, and emotional support. However, the evaluation methods were often non-standardized, with most studies relying on ad hoc scales that limit comparability and robustness. Privacy, safety, and fairness were also frequently underexplored. Moreover, reliance on proprietary models, such as OpenAI's GPT series, raises concerns about transparency and reproducibility. While LLMs show potential in expanding mental health care access, especially in underserved areas, the current evidence does not fully support their use as standalone interventions. More rigorous, standardized evaluations and ethical oversight are needed to ensure these tools can be safely and effectively integrated into clinical practice.