 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Progress Toward AGI: A Cognitive Framework
May 27, 2026Despite widespread discussion of AGI, there is no clear framework for measuring progress toward it. This ambiguity fuels subjective claims, makes it difficult to track progress, and risks hindering responsible governance. As a starting point to address this gap, we present a framework for understanding system capabilities in relation to human cognitive abilities. Drawing from decades of research in psychology, neuroscience, and cognitive science, we introduce a Cognitive Taxonomy that deconstructs general intelligence into 10 key cognitive faculties. We then propose a rigorous evaluation protocol in which a system's performance is measured across a suite of targeted, held-out cognitive tasks, generating a 'cognitive profile' that can be used to understand a system's strengths and weaknesses. We hope this framework will provide a practical roadmap and an initial step toward more rigorous, empirical evaluation of AGI.
Optimizing Large Language Models for Detecting Symptoms of Comorbid Depression or Anxiety in Chronic Diseases: Insights from Patient Messages
Mar 14, 2025



Patients with diabetes are at increased risk of comorbid depression or anxiety, complicating their management. This study evaluated the performance of large language models (LLMs) in detecting these symptoms from secure patient messages. We applied multiple approaches, including engineered prompts, systemic persona, temperature adjustments, and zero-shot and few-shot learning, to identify the best-performing model and enhance performance. Three out of five LLMs demonstrated excellent performance (over 90% of F-1 and accuracy), with Llama 3.1 405B achieving 93% in both F-1 and accuracy using a zero-shot approach. While LLMs showed promise in binary classification and handling complex metrics like Patient Health Questionnaire-4, inconsistencies in challenging cases warrant further real-life assessment. The findings highlight the potential of LLMs to assist in timely screening and referrals, providing valuable empirical knowledge for real-world triage systems that could improve mental health care for patients with chronic diseases.
Evidence of Cognitive Deficits andDevelopmental Advances in Generative AI: A Clock Drawing Test Analysis
Oct 15, 2024

Generative AI's rapid advancement sparks interest in its cognitive abilities, especially given its capacity for tasks like language understanding and code generation. This study explores how several recent GenAI models perform on the Clock Drawing Test (CDT), a neuropsychological assessment of visuospatial planning and organization. While models create clock-like drawings, they struggle with accurate time representation, showing deficits similar to mild-severe cognitive impairment (Wechsler, 2009). Errors include numerical sequencing issues, incorrect clock times, and irrelevant additions, despite accurate rendering of clock features. Only GPT 4 Turbo and Gemini Pro 1.5 produced the correct time, scoring like healthy individuals (4/4). A follow-up clock-reading test revealed only Sonnet 3.5 succeeded, suggesting drawing deficits stem from difficulty with numerical concepts. These findings may reflect weaknesses in visual-spatial understanding, working memory, or calculation, highlighting strengths in learned knowledge but weaknesses in reasoning. Comparing human and machine performance is crucial for understanding AI's cognitive capabilities and guiding development toward human-like cognitive functions.
The Cognitive Capabilities of Generative AI: A Comparative Analysis with Human Benchmarks
Oct 09, 2024



There is increasing interest in tracking the capabilities of general intelligence foundation models. This study benchmarks leading large language models and vision language models against human performance on the Wechsler Adult Intelligence Scale (WAIS-IV), a comprehensive, population-normed assessment of underlying human cognition and intellectual abilities, with a focus on the domains of VerbalComprehension (VCI), Working Memory (WMI), and Perceptual Reasoning (PRI). Most models demonstrated exceptional capabilities in the storage, retrieval, and manipulation of tokens such as arbitrary sequences of letters and numbers, with performance on the Working Memory Index (WMI) greater or equal to the 99.5th percentile when compared to human population normative ability. Performance on the Verbal Comprehension Index (VCI) which measures retrieval of acquired information, and linguistic understanding about the meaning of words and their relationships to each other, also demonstrated consistent performance at or above the 98th percentile. Despite these broad strengths, we observed consistently poor performance on the Perceptual Reasoning Index (PRI; range 0.1-10th percentile) from multimodal models indicating profound inability to interpret and reason on visual information. Smaller and older model versions consistently performed worse, indicating that training data, parameter count and advances in tuning are resulting in significant advances in cognitive ability.
The Capability of Large Language Models to Measure Psychiatric Functioning
Aug 03, 2023
The current work investigates the capability of Large language models (LLMs) that are explicitly trained on large corpuses of medical knowledge (Med-PaLM 2) to predict psychiatric functioning from patient interviews and clinical descriptions without being trained to do so. To assess this, n = 145 depression and n =115 PTSD assessments and n = 46 clinical case studies across high prevalence/high comorbidity disorders (Depressive, Anxiety, Psychotic, trauma and stress, Addictive disorders) were analyzed using prompts to extract estimated clinical scores and diagnoses. Results demonstrate that Med-PaLM 2 is capable of assessing psychiatric functioning across a range of psychiatric conditions with the strongest performance being the prediction of depression scores based on standardized assessments (Accuracy range= 0.80 - 0.84) which were statistically indistinguishable from human clinical raters t(1,144) = 1.20; p = 0.23. Results show the potential for general clinical language models to flexibly predict psychiatric risk based on free descriptions of functioning from both patients and clinicians.
Modern Views of Machine Learning for Precision Psychiatry
Apr 04, 2022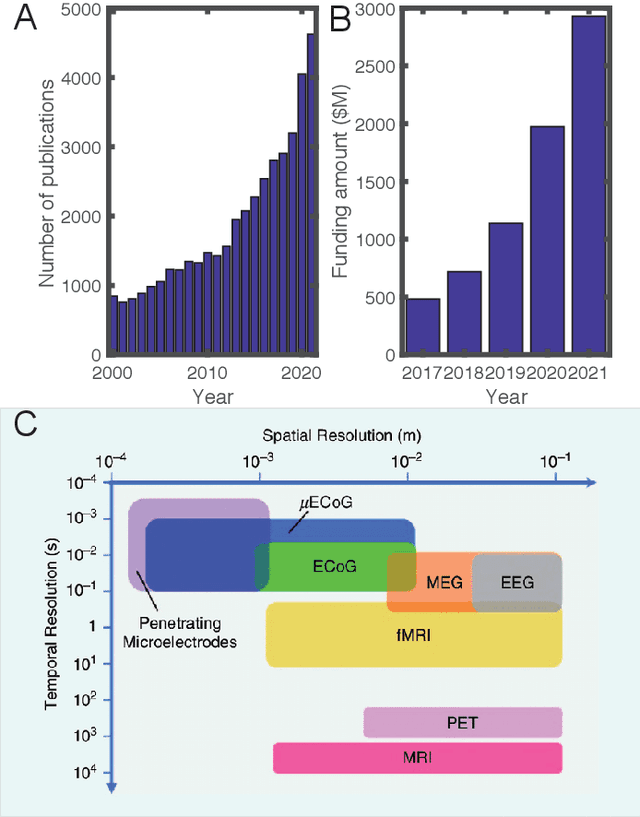

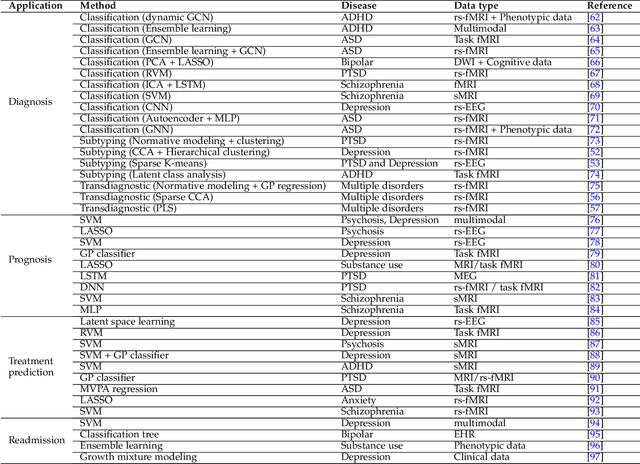
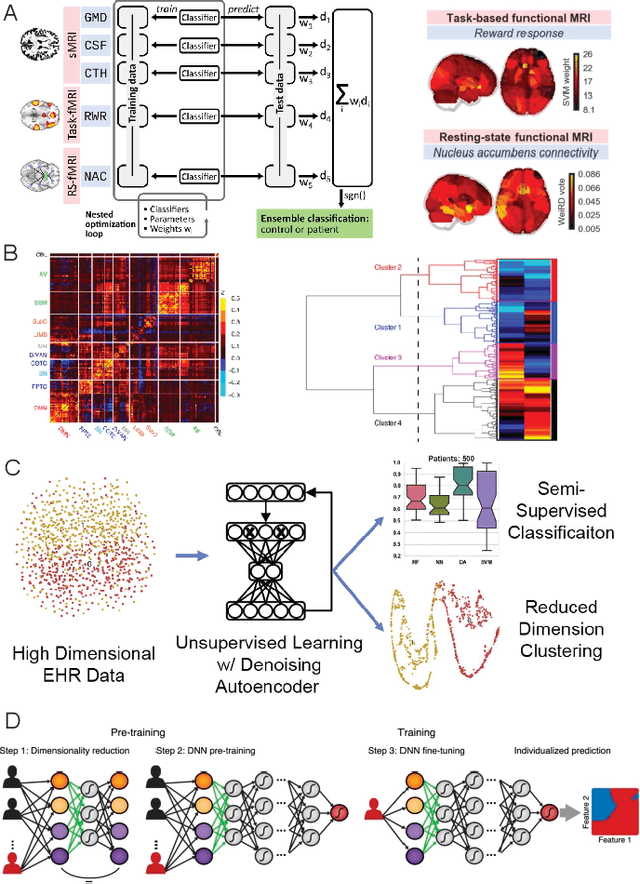
In light of the NIMH's Research Domain Criteria (RDoC), the advent of functional neuroimaging, novel technologies and methods provide new opportunities to develop precise and personalized prognosis and diagnosis of mental disorders. Machine learning (ML) and artificial intelligence (AI) technologies are playing an increasingly critical role in the new era of precision psychiatry. Combining ML/AI with neuromodulation technologies can potentially provide explainable solutions in clinical practice and effective therapeutic treatment. Advanced wearable and mobile technologies also call for the new role of ML/AI for digital phenotyping in mobile mental health. In this review, we provide a comprehensive review of the ML methodologies and applications by combining neuroimaging, neuromodulation, and advanced mobile technologies in psychiatry practice. Additionally, we review the role of ML in molecular phenotyping and cross-species biomarker identification in precision psychiatry. We further discuss explainable AI (XAI) and causality testing in a closed-human-in-the-loop manner, and highlight the ML potential in multimedia information extraction and multimodal data fusion. Finally, we discuss conceptual and practical challenges in precision psychiatry and highlight ML opportunities in future research.