 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
Smartphone monitoring of smiling as a behavioral proxy of well-being in everyday life
Dec 10, 2025Subjective well-being is a cornerstone of individual and societal health, yet its scientific measurement has traditionally relied on self-report methods prone to recall bias and high participant burden. This has left a gap in our understanding of well-being as it is expressed in everyday life. We hypothesized that candid smiles captured during natural smartphone interactions could serve as a scalable, objective behavioral correlate of positive affect. To test this, we analyzed 405,448 video clips passively recorded from 233 consented participants over one week. Using a deep learning model to quantify smile intensity, we identified distinct diurnal and daily patterns. Daily patterns of smile intensity across the week showed strong correlation with national survey data on happiness (r=0.92), and diurnal rhythms documented close correspondence with established results from the day reconstruction method (r=0.80). Higher daily mean smile intensity was significantly associated with more physical activity (Beta coefficient = 0.043, 95% CI [0.001, 0.085]) and greater light exposure (Beta coefficient = 0.038, [0.013, 0.063]), whereas no significant effects were found for smartphone use. These findings suggest that passive smartphone sensing could serve as a powerful, ecologically valid methodology for studying the dynamics of affective behavior and open the door to understanding this behavior at a population scale.
InvThink: Towards AI Safety via Inverse Reasoning
Oct 02, 2025



We present InvThink, a simple yet powerful approach that gives large language models (LLMs) the capability of inverse thinking: reasoning through failure modes before generating responses. Unlike existing safety alignment methods that optimize directly for safe response, InvThink instructs models to 1) enumerate potential harms, 2) analyze their consequences, and 3) generate safe outputs that proactively avoid these risks. Our method reveals three key findings: (i) safety improvements show stronger scaling with model size compared to existing safety methods. (ii) InvThink mitigates safety tax; by training models to systematically consider failure modes, it preserves general reasoning capabilities on standard benchmarks. (iii) beyond general safety tasks, InvThink excels in high-stakes domains including external-facing (medicine, finance, law) and agentic (blackmail, murder) risk scenarios, achieving up to 15.7% reduction in harmful responses compared to baseline methods like SafetyPrompt. We further implement InvThink via supervised fine-tuning, and reinforcement learning across three LLM families. These results suggest that inverse reasoning provides a scalable and generalizable path toward safer, more capable language models.
Tiered Agentic Oversight: A Hierarchical Multi-Agent System for AI Safety in Healthcare
Jun 14, 2025Current large language models (LLMs), despite their power, can introduce safety risks in clinical settings due to limitations such as poor error detection and single point of failure. To address this, we propose Tiered Agentic Oversight (TAO), a hierarchical multi-agent framework that enhances AI safety through layered, automated supervision. Inspired by clinical hierarchies (e.g., nurse, physician, specialist), TAO conducts agent routing based on task complexity and agent roles. Leveraging automated inter- and intra-tier collaboration and role-playing, TAO creates a robust safety framework. Ablation studies reveal that TAO's superior performance is driven by its adaptive tiered architecture, which improves safety by over 3.2% compared to static single-tier configurations; the critical role of its lower tiers, particularly tier 1, whose removal most significantly impacts safety; and the strategic assignment of more advanced LLM to these initial tiers, which boosts performance by over 2% compared to less optimal allocations while achieving near-peak safety efficiently. These mechanisms enable TAO to outperform single-agent and multi-agent frameworks in 4 out of 5 healthcare safety benchmarks, showing up to an 8.2% improvement over the next-best methods in these evaluations. Finally, we validate TAO via an auxiliary clinician-in-the-loop study where integrating expert feedback improved TAO's accuracy in medical triage from 40% to 60%.
Non-Contact Health Monitoring During Daily Personal Care Routines
Jun 11, 2025Remote photoplethysmography (rPPG) enables non-contact, continuous monitoring of physiological signals and offers a practical alternative to traditional health sensing methods. Although rPPG is promising for daily health monitoring, its application in long-term personal care scenarios, such as mirror-facing routines in high-altitude environments, remains challenging due to ambient lighting variations, frequent occlusions from hand movements, and dynamic facial postures. To address these challenges, we present LADH (Long-term Altitude Daily Health), the first long-term rPPG dataset containing 240 synchronized RGB and infrared (IR) facial videos from 21 participants across five common personal care scenarios, along with ground-truth PPG, respiration, and blood oxygen signals. Our experiments demonstrate that combining RGB and IR video inputs improves the accuracy and robustness of non-contact physiological monitoring, achieving a mean absolute error (MAE) of 4.99 BPM in heart rate estimation. Furthermore, we find that multi-task learning enhances performance across multiple physiological indicators simultaneously. Dataset and code are open at https://github.com/McJackTang/FusionVitals.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025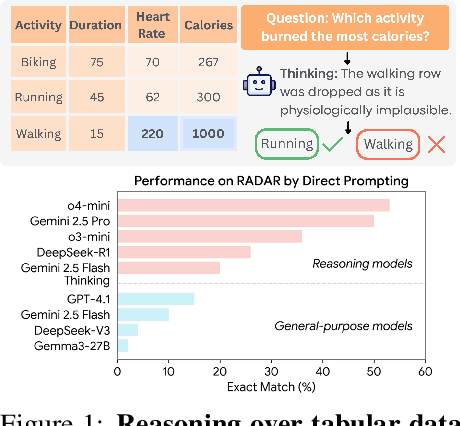
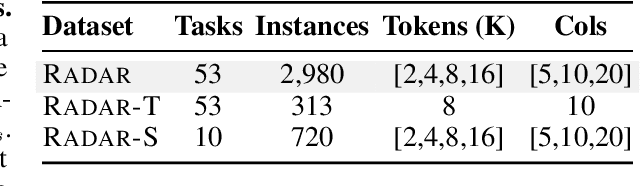
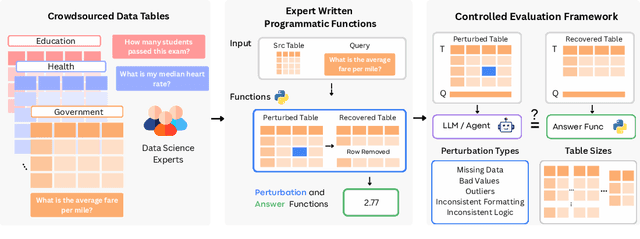
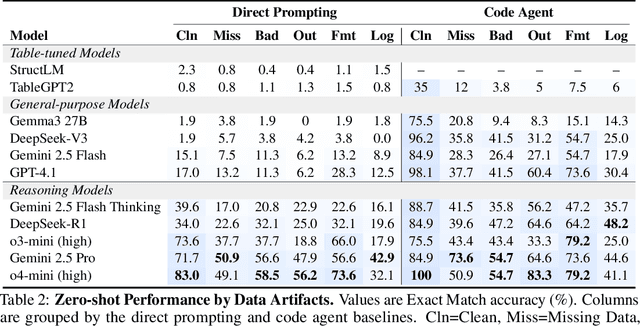
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
New Tools are Needed for Tracking Adherence to AI Model Behavioral Use Clauses
May 28, 2025



Foundation models have had a transformative impact on AI. A combination of large investments in research and development, growing sources of digital data for training, and architectures that scale with data and compute has led to models with powerful capabilities. Releasing assets is fundamental to scientific advancement and commercial enterprise. However, concerns over negligent or malicious uses of AI have led to the design of mechanisms to limit the risks of the technology. The result has been a proliferation of licenses with behavioral-use clauses and acceptable-use-policies that are increasingly being adopted by commonly used families of models (Llama, Gemma, Deepseek) and a myriad of smaller projects. We created and deployed a custom AI licenses generator to facilitate license creation and have quantitatively and qualitatively analyzed over 300 customized licenses created with this tool. Alongside this we analyzed 1.7 million models licenses on the HuggingFace model hub. Our results show increasing adoption of these licenses, interest in tools that support their creation and a convergence on common clause configurations. In this paper we take the position that tools for tracking adoption of, and adherence to, these licenses is the natural next step and urgently needed in order to ensure they have the desired impact of ensuring responsible use.
BehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025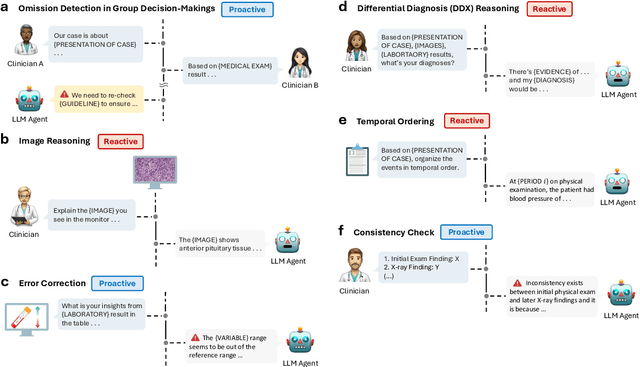
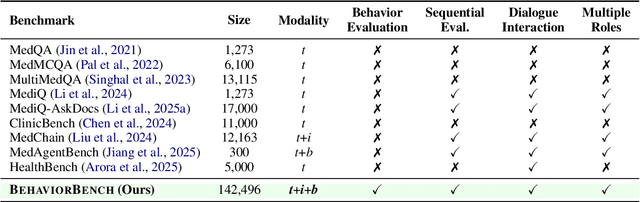
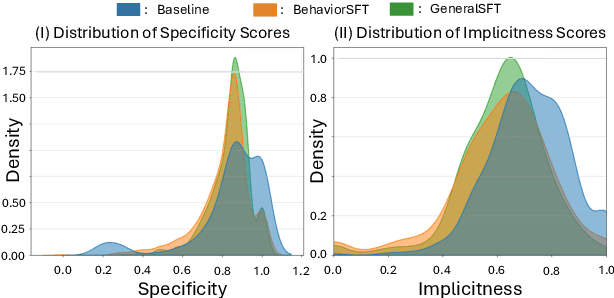
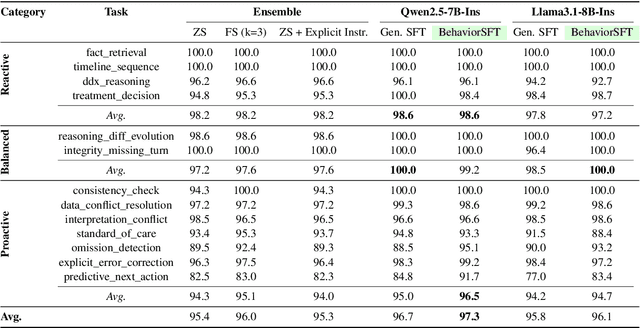
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.