 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroS: Zero-Sum Linear Attention for Efficient Transformers
Feb 05, 2026Linear attention methods offer Transformers $O(N)$ complexity but typically underperform standard softmax attention. We identify two fundamental limitations affecting these approaches: the restriction to convex combinations that only permits additive information blending, and uniform accumulated weight bias that dilutes attention in long contexts. We propose Zero-Sum Linear Attention (ZeroS), which addresses these limitations by removing the constant zero-order term $1/t$ and reweighting the remaining zero-sum softmax residuals. This modification creates mathematically stable weights, enabling both positive and negative values and allowing a single attention layer to perform contrastive operations. While maintaining $O(N)$ complexity, ZeroS theoretically expands the set of representable functions compared to convex combinations. Empirically, it matches or exceeds standard softmax attention across various sequence modeling benchmarks.
* Camera-ready version. Accepted at NeurIPS 2025
CAPS: Unifying Attention, Recurrence, and Alignment in Transformer-based Time Series Forecasting
Feb 02, 2026This paper presents $\textbf{CAPS}$ (Clock-weighted Aggregation with Prefix-products and Softmax), a structured attention mechanism for time series forecasting that decouples three distinct temporal structures: global trends, local shocks, and seasonal patterns. Standard softmax attention entangles these through global normalization, while recent recurrent models sacrifice long-term, order-independent selection for order-dependent causal structure. CAPS combines SO(2) rotations for phase alignment with three additive gating paths -- Riemann softmax, prefix-product gates, and a Clock baseline -- within a single attention layer. We introduce the Clock mechanism, a learned temporal weighting that modulates these paths through a shared notion of temporal importance. Experiments on long- and short-term forecasting benchmarks surpass vanilla softmax and linear attention mechanisms and demonstrate competitive performance against seven strong baselines with linear complexity. Our code implementation is available at https://github.com/vireshpati/CAPS-Attention.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
InvThink: Towards AI Safety via Inverse Reasoning
Oct 02, 2025



We present InvThink, a simple yet powerful approach that gives large language models (LLMs) the capability of inverse thinking: reasoning through failure modes before generating responses. Unlike existing safety alignment methods that optimize directly for safe response, InvThink instructs models to 1) enumerate potential harms, 2) analyze their consequences, and 3) generate safe outputs that proactively avoid these risks. Our method reveals three key findings: (i) safety improvements show stronger scaling with model size compared to existing safety methods. (ii) InvThink mitigates safety tax; by training models to systematically consider failure modes, it preserves general reasoning capabilities on standard benchmarks. (iii) beyond general safety tasks, InvThink excels in high-stakes domains including external-facing (medicine, finance, law) and agentic (blackmail, murder) risk scenarios, achieving up to 15.7% reduction in harmful responses compared to baseline methods like SafetyPrompt. We further implement InvThink via supervised fine-tuning, and reinforcement learning across three LLM families. These results suggest that inverse reasoning provides a scalable and generalizable path toward safer, more capable language models.
Tiered Agentic Oversight: A Hierarchical Multi-Agent System for AI Safety in Healthcare
Jun 14, 2025Current large language models (LLMs), despite their power, can introduce safety risks in clinical settings due to limitations such as poor error detection and single point of failure. To address this, we propose Tiered Agentic Oversight (TAO), a hierarchical multi-agent framework that enhances AI safety through layered, automated supervision. Inspired by clinical hierarchies (e.g., nurse, physician, specialist), TAO conducts agent routing based on task complexity and agent roles. Leveraging automated inter- and intra-tier collaboration and role-playing, TAO creates a robust safety framework. Ablation studies reveal that TAO's superior performance is driven by its adaptive tiered architecture, which improves safety by over 3.2% compared to static single-tier configurations; the critical role of its lower tiers, particularly tier 1, whose removal most significantly impacts safety; and the strategic assignment of more advanced LLM to these initial tiers, which boosts performance by over 2% compared to less optimal allocations while achieving near-peak safety efficiently. These mechanisms enable TAO to outperform single-agent and multi-agent frameworks in 4 out of 5 healthcare safety benchmarks, showing up to an 8.2% improvement over the next-best methods in these evaluations. Finally, we validate TAO via an auxiliary clinician-in-the-loop study where integrating expert feedback improved TAO's accuracy in medical triage from 40% to 60%.
BehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025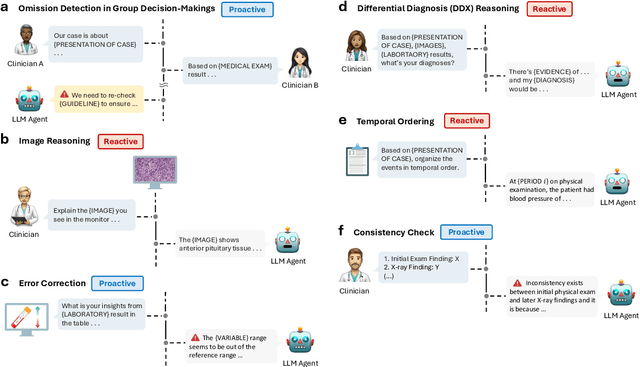
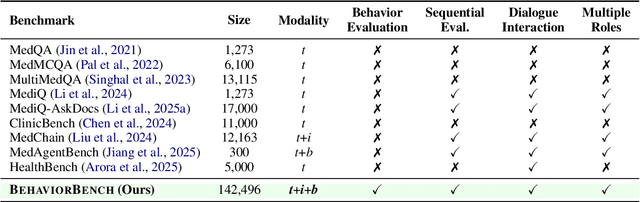
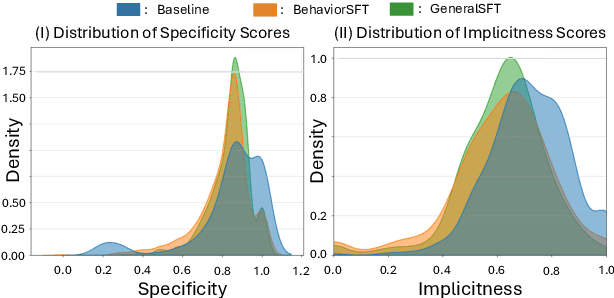
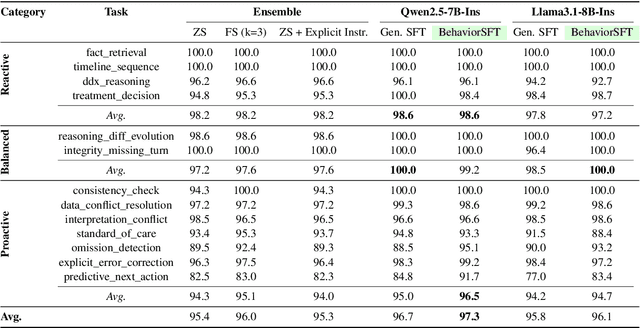
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.
VocalAgent: Large Language Models for Vocal Health Diagnostics with Safety-Aware Evaluation
May 19, 2025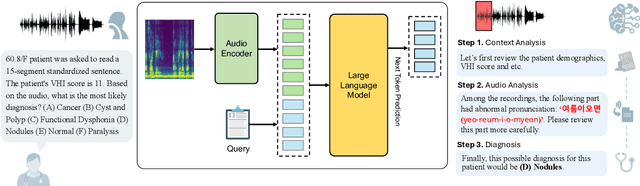
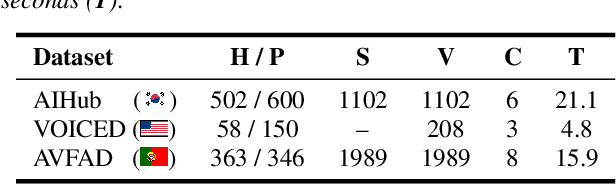
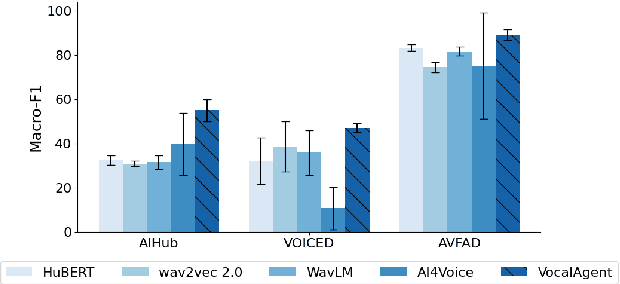
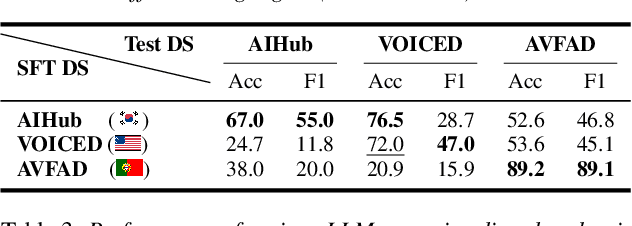
Vocal health plays a crucial role in peoples' lives, significantly impacting their communicative abilities and interactions. However, despite the global prevalence of voice disorders, many lack access to convenient diagnosis and treatment. This paper introduces VocalAgent, an audio large language model (LLM) to address these challenges through vocal health diagnosis. We leverage Qwen-Audio-Chat fine-tuned on three datasets collected in-situ from hospital patients, and present a multifaceted evaluation framework encompassing a safety assessment to mitigate diagnostic biases, cross-lingual performance analysis, and modality ablation studies. VocalAgent demonstrates superior accuracy on voice disorder classification compared to state-of-the-art baselines. Its LLM-based method offers a scalable solution for broader adoption of health diagnostics, while underscoring the importance of ethical and technical validation.
A Demonstration of Adaptive Collaboration of Large Language Models for Medical Decision-Making
Oct 31, 2024



Medical Decision-Making (MDM) is a multi-faceted process that requires clinicians to assess complex multi-modal patient data patient, often collaboratively. Large Language Models (LLMs) promise to streamline this process by synthesizing vast medical knowledge and multi-modal health data. However, single-agent are often ill-suited for nuanced medical contexts requiring adaptable, collaborative problem-solving. Our MDAgents addresses this need by dynamically assigning collaboration structures to LLMs based on task complexity, mimicking real-world clinical collaboration and decision-making. This framework improves diagnostic accuracy and supports adaptive responses in complex, real-world medical scenarios, making it a valuable tool for clinicians in various healthcare settings, and at the same time, being more efficient in terms of computing cost than static multi-agent decision making methods.
EmpathicStories++: A Multimodal Dataset for Empathy towards Personal Experiences
May 24, 2024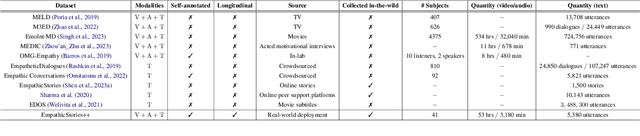
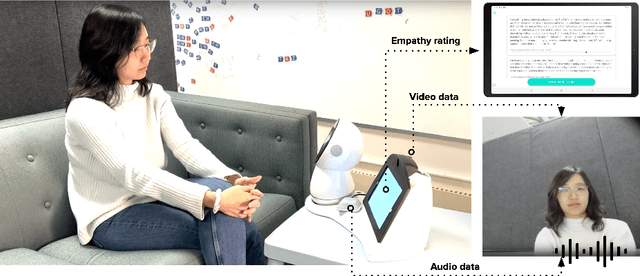
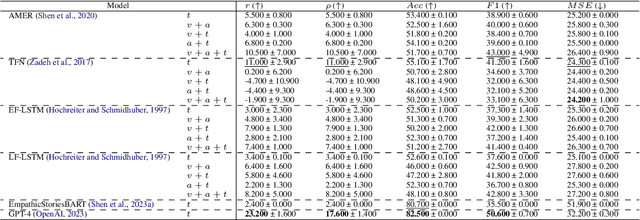
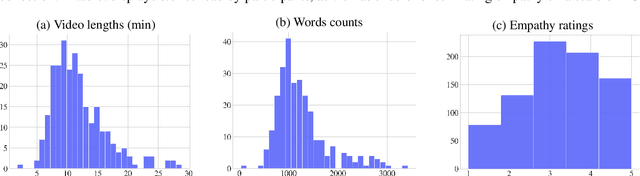
Modeling empathy is a complex endeavor that is rooted in interpersonal and experiential dimensions of human interaction, and remains an open problem within AI. Existing empathy datasets fall short in capturing the richness of empathy responses, often being confined to in-lab or acted scenarios, lacking longitudinal data, and missing self-reported labels. We introduce a new multimodal dataset for empathy during personal experience sharing: the EmpathicStories++ dataset (https://mitmedialab.github.io/empathic-stories-multimodal/) containing 53 hours of video, audio, and text data of 41 participants sharing vulnerable experiences and reading empathically resonant stories with an AI agent. EmpathicStories++ is the first longitudinal dataset on empathy, collected over a month-long deployment of social robots in participants' homes, as participants engage in natural, empathic storytelling interactions with AI agents. We then introduce a novel task of predicting individuals' empathy toward others' stories based on their personal experiences, evaluated in two contexts: participants' own personal shared story context and their reflections on stories they read. We benchmark this task using state-of-the-art models to pave the way for future improvements in contextualized and longitudinal empathy modeling. Our work provides a valuable resource for further research in developing empathetic AI systems and understanding the intricacies of human empathy within genuine, real-world settings.
Adaptive Collaboration Strategy for LLMs in Medical Decision Making
Apr 22, 2024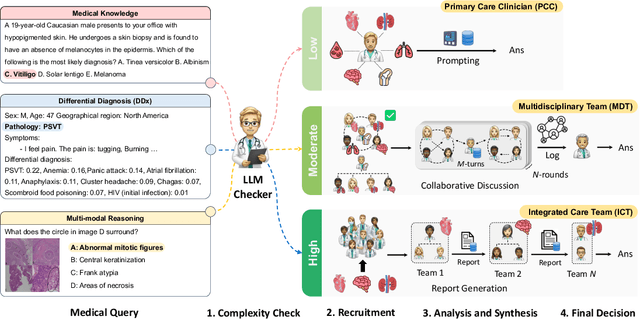
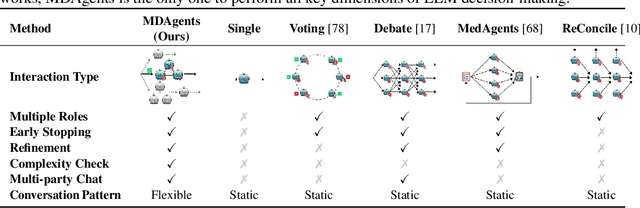
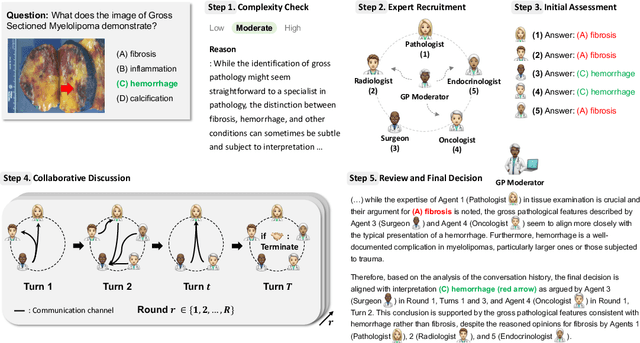
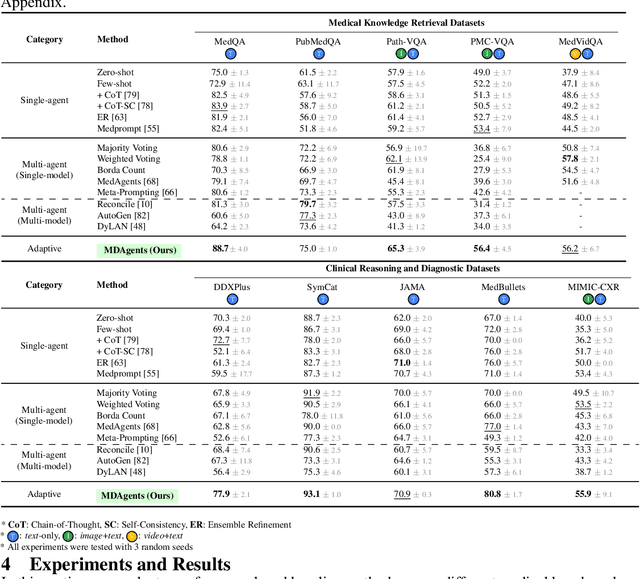
Foundation models have become invaluable in advancing the medical field. Despite their promise, the strategic deployment of LLMs for effective utility in complex medical tasks remains an open question. Our novel framework, Medical Decision-making Agents (MDAgents) aims to address this gap by automatically assigning the effective collaboration structure for LLMs. Assigned solo or group collaboration structure is tailored to the complexity of the medical task at hand, emulating real-world medical decision making processes. We evaluate our framework and baseline methods with state-of-the-art LLMs across a suite of challenging medical benchmarks: MedQA, MedMCQA, PubMedQA, DDXPlus, PMC-VQA, Path-VQA, and MedVidQA, achieving the best performance in 5 out of 7 benchmarks that require an understanding of multi-modal medical reasoning. Ablation studies reveal that MDAgents excels in adapting the number of collaborating agents to optimize efficiency and accuracy, showcasing its robustness in diverse scenarios. We also explore the dynamics of group consensus, offering insights into how collaborative agents could behave in complex clinical team dynamics. Our code can be found at https://github.com/mitmedialab/MDAgents.