 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow-π: Knowledge Distillation for Flow-based VLAs
Jan 28, 2026The growing demand for real-time robotic deployment necessitates fast and on-device inference for vision-language-action (VLA) models. Within the VLA literature, efficiency has been extensively studied at the token level, such as visual token pruning. In contrast, systematic transformer layer reduction has received limited attention and, to the best of our knowledge, has not been explored for flow-based VLA models under knowledge distillation. In this work, we propose Shallow-pi, a principled knowledge distillation framework that aggressively reduces the transformer depth of both the VLM backbone and the flow-based action head, compressing the model from 18 to 6 layers. Shallow-pi achieves over two times faster inference with less than one percent absolute drop in success rate on standard manipulation benchmarks, establishing state-of-the-art performance among reduced VLA models. Crucially, we validate our approach through industrial-scale real-world experiments on Jetson Orin and Jetson Thor across multiple robot platforms, including humanoid systems, in complex and dynamic manipulation scenarios.
InvThink: Towards AI Safety via Inverse Reasoning
Oct 02, 2025



We present InvThink, a simple yet powerful approach that gives large language models (LLMs) the capability of inverse thinking: reasoning through failure modes before generating responses. Unlike existing safety alignment methods that optimize directly for safe response, InvThink instructs models to 1) enumerate potential harms, 2) analyze their consequences, and 3) generate safe outputs that proactively avoid these risks. Our method reveals three key findings: (i) safety improvements show stronger scaling with model size compared to existing safety methods. (ii) InvThink mitigates safety tax; by training models to systematically consider failure modes, it preserves general reasoning capabilities on standard benchmarks. (iii) beyond general safety tasks, InvThink excels in high-stakes domains including external-facing (medicine, finance, law) and agentic (blackmail, murder) risk scenarios, achieving up to 15.7% reduction in harmful responses compared to baseline methods like SafetyPrompt. We further implement InvThink via supervised fine-tuning, and reinforcement learning across three LLM families. These results suggest that inverse reasoning provides a scalable and generalizable path toward safer, more capable language models.
Collective Voice: Recovered-Peer Support Mediated by An LLM-Based Chatbot for Eating Disorder Recovery
Sep 18, 2025Peer recovery narratives provide unique benefits beyond professional or lay mentoring by fostering hope and sustained recovery in eating disorder (ED) contexts. Yet, such support is limited by the scarcity of peer-involved programs and potential drawbacks on recovered peers, including relapse risk. To address this, we designed RecoveryTeller, a chatbot adopting a recovered-peer persona that portrays itself as someone recovered from an ED. We examined whether such a persona can reproduce the support affordances of peer recovery narratives. We compared RecoveryTeller with a lay-mentor persona chatbot offering similar guidance but without a recovery background. We conducted a 20-day cross-over deployment study with 26 ED participants, each using both chatbots for 10 days. RecoveryTeller elicited stronger emotional resonance than a lay-mentor chatbot, yet tensions between emotional and epistemic trust led participants to view the two personas as complementary rather than substitutes. We provide design implications for mental health chatbot persona design.
VocalAgent: Large Language Models for Vocal Health Diagnostics with Safety-Aware Evaluation
May 19, 2025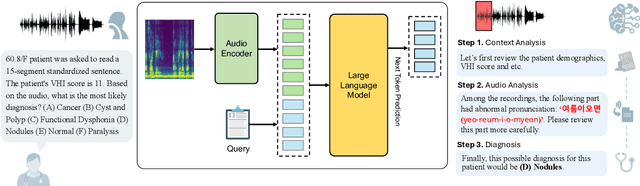
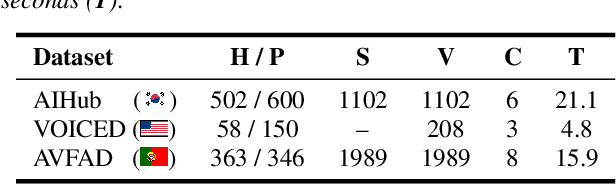
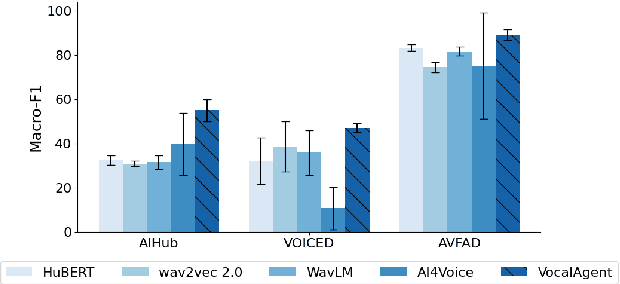
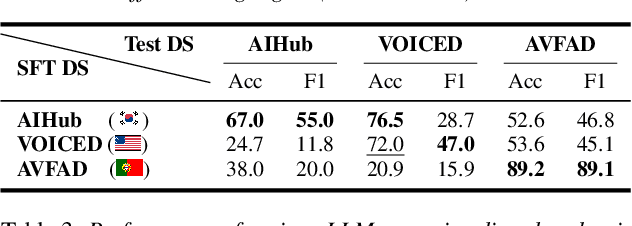
Vocal health plays a crucial role in peoples' lives, significantly impacting their communicative abilities and interactions. However, despite the global prevalence of voice disorders, many lack access to convenient diagnosis and treatment. This paper introduces VocalAgent, an audio large language model (LLM) to address these challenges through vocal health diagnosis. We leverage Qwen-Audio-Chat fine-tuned on three datasets collected in-situ from hospital patients, and present a multifaceted evaluation framework encompassing a safety assessment to mitigate diagnostic biases, cross-lingual performance analysis, and modality ablation studies. VocalAgent demonstrates superior accuracy on voice disorder classification compared to state-of-the-art baselines. Its LLM-based method offers a scalable solution for broader adoption of health diagnostics, while underscoring the importance of ethical and technical validation.
Pesti-Gen: Unleashing a Generative Molecule Approach for Toxicity Aware Pesticide Design
Jan 24, 2025



Global climate change has reduced crop resilience and pesticide efficacy, making reliance on synthetic pesticides inevitable, even though their widespread use poses significant health and environmental risks. While these pesticides remain a key tool in pest management, previous machine-learning applications in pesticide and agriculture have focused on classification or regression, leaving the fundamental challenge of generating new molecular structures or designing novel candidates unaddressed. In this paper, we propose Pesti-Gen, a novel generative model based on variational auto-encoders, designed to create pesticide candidates with optimized properties for the first time. Specifically, Pesti-Gen leverages a two-stage learning process: an initial pre-training phase that captures a generalized chemical structure representation, followed by a fine-tuning stage that incorporates toxicity-specific information. The model simultaneously optimizes over multiple toxicity metrics, such as (1) livestock toxicity and (2) aqua toxicity to generate environmentally friendly pesticide candidates. Notably, Pesti-Gen achieves approximately 68\% structural validity in generating new molecular structures, demonstrating the model's effectiveness in producing optimized and feasible pesticide candidates, thereby providing a new way for safer and more sustainable pest management solutions.
Private Yet Social: How LLM Chatbots Support and Challenge Eating Disorder Recovery
Dec 16, 2024


Eating disorders (ED) are complex mental health conditions that require long-term management and support. Recent advancements in large language model (LLM)-based chatbots offer the potential to assist individuals in receiving immediate support. Yet, concerns remain about their reliability and safety in sensitive contexts such as ED. We explore the opportunities and potential harms of using LLM-based chatbots for ED recovery. We observe the interactions between 26 participants with ED and an LLM-based chatbot, WellnessBot, designed to support ED recovery, over 10 days. We discovered that our participants have felt empowered in recovery by discussing ED-related stories with the chatbot, which served as a personal yet social avenue. However, we also identified harmful chatbot responses, especially concerning individuals with ED, that went unnoticed partly due to participants' unquestioning trust in the chatbot's reliability. Based on these findings, we provide design implications for safe and effective LLM-based interventions in ED management.
Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation
Jun 10, 2024Since the success of a time-domain speech separation, further improvements have been made by expanding the length and channel of a feature sequence to increase the amount of computation. When temporally expanded to a long sequence, the feature is segmented into chunks as a dual-path model in most studies of speech separation. In particular, it is common for the process of separating features corresponding to each speaker to be located in the final stage of the network. However, it is more advantageous and intuitive to proactively expand the feature sequence to include the number of speakers as an extra dimension. In this paper, we present an asymmetric strategy in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, as Siamese network, in addition to cross-speaker processing. By using the Siamese network in the decoder, without using speaker information, the network directly learns to discriminate the features using a separation objective. With a common split layer, intermediate encoder features for skip connections are also split for the reconstruction decoder based on the U-Net structure. In addition, instead of segmenting the feature into chunks as dual-path, we design global and local Transformer blocks to directly process long sequences. The experimental results demonstrated that this separation-and-reconstruction framework is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of inter- and intra-chunk processing in dual-path structure. Finally, the presented model including both of these achieved state-of-the-art performance with less computation than before in various benchmark datasets.
A Knowledge-Component-Based Methodology for Evaluating AI Assistants
Jun 09, 2024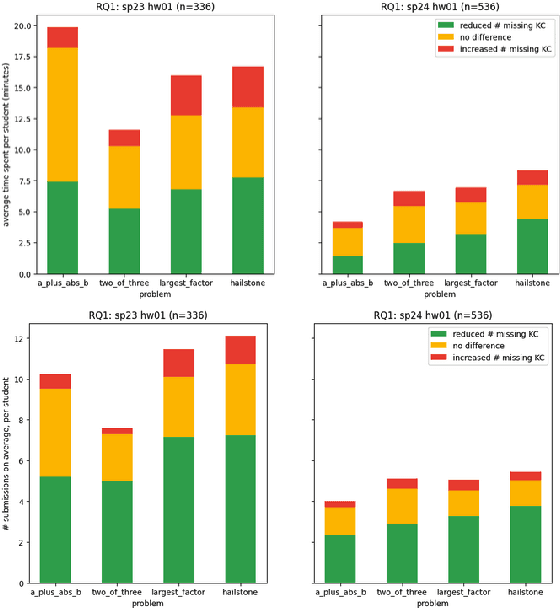
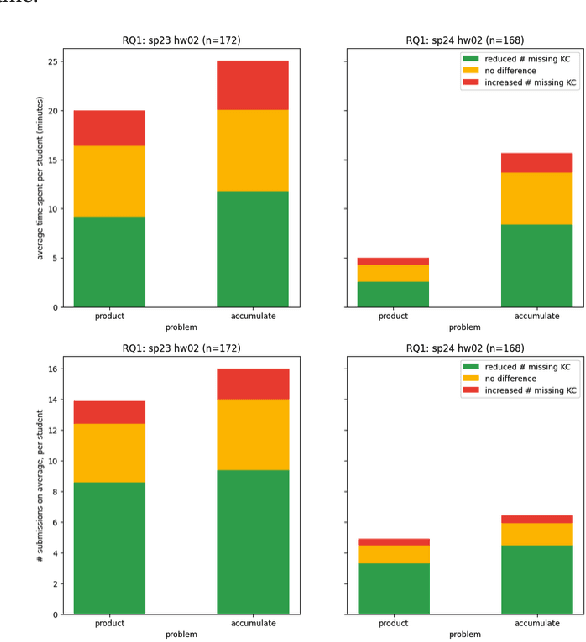
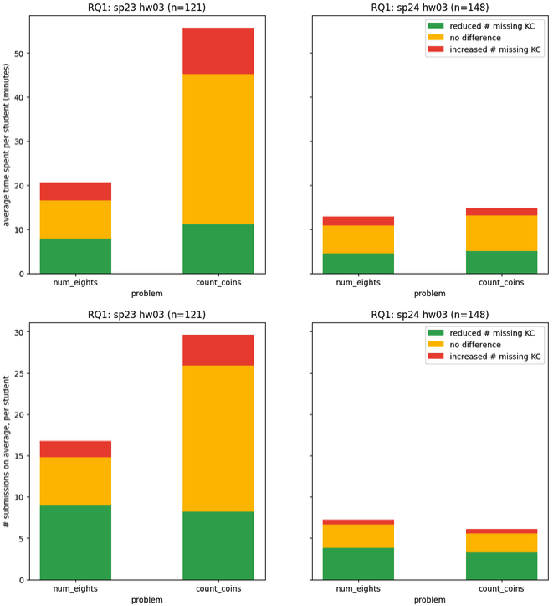
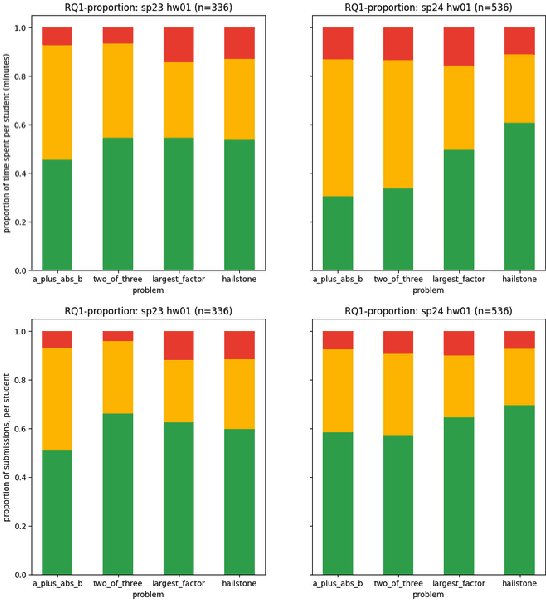
We evaluate an automatic hint generator for CS1 programming assignments powered by GPT-4, a large language model. This system provides natural language guidance about how students can improve their incorrect solutions to short programming exercises. A hint can be requested each time a student fails a test case. Our evaluation addresses three Research Questions: RQ1: Do the hints help students improve their code? RQ2: How effectively do the hints capture problems in student code? RQ3: Are the issues that students resolve the same as the issues addressed in the hints? To address these research questions quantitatively, we identified a set of fine-grained knowledge components and determined which ones apply to each exercise, incorrect solution, and generated hint. Comparing data from two large CS1 offerings, we found that access to the hints helps students to address problems with their code more quickly, that hints are able to consistently capture the most pressing errors in students' code, and that hints that address a few issues at once rather than a single bug are more likely to lead to direct student progress.
Diffusion-EDFs: Bi-equivariant Denoising Generative Modeling on SE(3) for Visual Robotic Manipulation
Sep 07, 2023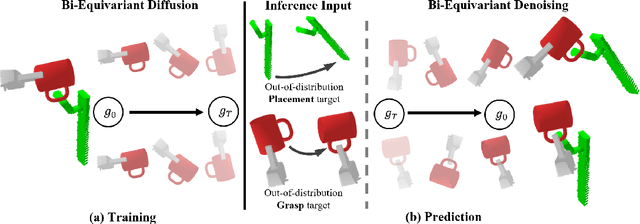



Recent studies have verified that equivariant methods can significantly improve the data efficiency, generalizability, and robustness in robot learning. Meanwhile, denoising diffusion-based generative modeling has recently gained significant attention as a promising approach for robotic manipulation learning from demonstrations with stochastic behaviors. In this paper, we present Diffusion-EDFs, a novel approach that incorporates spatial roto-translation equivariance, i.e., SE(3)-equivariance to diffusion generative modeling. By integrating SE(3)-equivariance into our model architectures, we demonstrate that our proposed method exhibits remarkable data efficiency, requiring only 5 to 10 task demonstrations for effective end-to-end training. Furthermore, our approach showcases superior generalizability compared to previous diffusion-based manipulation methods.