 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Encoder-Decoder Based on Time-Frequency Correlation for Speech Separation
Mar 31, 2026Speech separation in realistic acoustic environments remains challenging because overlapping speakers, background noise, and reverberation must be resolved simultaneously. Although recent time-frequency (TF) domain models have shown strong performance, most still rely on late-split architectures, where speaker disentanglement is deferred to the final stage, creating an information bottleneck and weakening discriminability under adverse conditions. To address this issue, we propose SR-CorrNet, an asymmetric encoder-decoder framework that introduces the separation-reconstruction (SepRe) strategy into a TF dual-path backbone. The encoder performs coarse separation from mixture observations, while the weight-shared decoder progressively reconstructs speaker-discriminative features with cross-speaker interaction, enabling stage-wise refinement. To complement this architecture, we formulate speech separation as a structured correlation-to-filter problem: spatio-spectro-temporal correlations computed from the observations are used as input features, and the corresponding deep filters are estimated to recover target signals. We further incorporate an attractor-based dynamic split module to adapt the number of output streams to the actual speaker configuration. Experimental results on WSJ0-2/3/4/5Mix, WHAMR!, and LibriCSS demonstrate consistent improvements across anechoic, noisy-reverberant, and real-recorded conditions in both single- and multi-channel settings, highlighting the effectiveness of TF-domain SepRe with correlation-based filter estimation for speech separation.
Deep Filter Estimation from Inter-Frame Correlations for Monaural Speech Dereverberation
Mar 16, 2026Speech dereverberation in distant-microphone scenarios remains challenging due to the high correlation between reverberation and target signals, often leading to poor generalization in real-world environments. We propose IF-CorrNet, a correlation-to-filter architecture designed for robustness against acoustic variability. Unlike conventional black-box mapping methods that directly estimate complex spectra, IF-CorrNet explicitly exploits inter-frame STFT correlations to estimate multi-frame deep filters for each time-frequency bin. By shifting the learning objective from direct mapping to filter estimation, the network effectively constrains the solution space, which simplifies the training process and mitigates overfitting to synthetic data. Experimental results on the REVERB Challenge dataset demonstrate that IF-CorrNet achieves a substantial gain in the SRMR metric on RealData, confirming its robustness in suppressing reverberation and noise in practical, non-synthetic environments.
Stack Less, Repeat More: A Block Reusing Approach for Progressive Speech Enhancement
May 26, 2025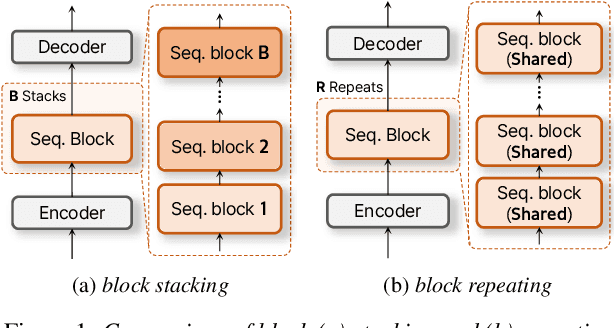
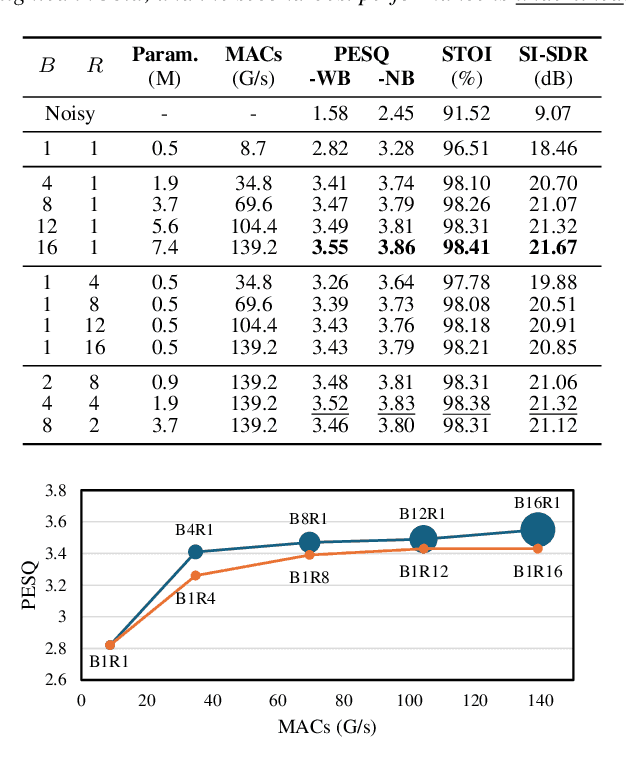
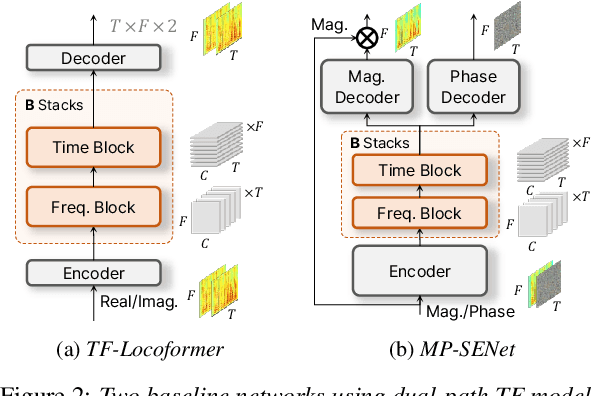
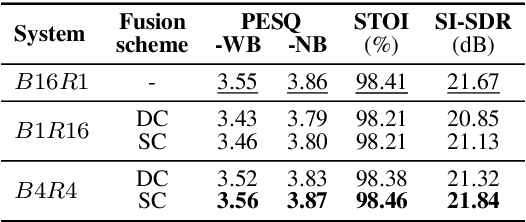
This paper presents an efficient speech enhancement (SE) approach that reuses a processing block repeatedly instead of conventional stacking. Rather than increasing the number of blocks for learning deep latent representations, repeating a single block leads to progressive refinement while reducing parameter redundancy. We also minimize domain transformation by keeping an encoder and decoder shallow and reusing a single sequence modeling block. Experimental results show that the number of processing stages is more critical to performance than the number of blocks with different weights. Also, we observed that the proposed method gradually refines a noisy input within a single block. Furthermore, with the block reuse method, we demonstrate that deepening the encoder and decoder can be redundant for learning deep complex representation. Therefore, the experimental results confirm that the proposed block reusing enables progressive learning and provides an efficient alternative for SE.
Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation
Jun 10, 2024Since the success of a time-domain speech separation, further improvements have been made by expanding the length and channel of a feature sequence to increase the amount of computation. When temporally expanded to a long sequence, the feature is segmented into chunks as a dual-path model in most studies of speech separation. In particular, it is common for the process of separating features corresponding to each speaker to be located in the final stage of the network. However, it is more advantageous and intuitive to proactively expand the feature sequence to include the number of speakers as an extra dimension. In this paper, we present an asymmetric strategy in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, as Siamese network, in addition to cross-speaker processing. By using the Siamese network in the decoder, without using speaker information, the network directly learns to discriminate the features using a separation objective. With a common split layer, intermediate encoder features for skip connections are also split for the reconstruction decoder based on the U-Net structure. In addition, instead of segmenting the feature into chunks as dual-path, we design global and local Transformer blocks to directly process long sequences. The experimental results demonstrated that this separation-and-reconstruction framework is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of inter- and intra-chunk processing in dual-path structure. Finally, the presented model including both of these achieved state-of-the-art performance with less computation than before in various benchmark datasets.
NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
Dec 15, 2023In speaker verification, ECAPA-TDNN has shown remarkable improvement by utilizing one-dimensional(1D) Res2Net block and squeeze-and-excitation(SE) module, along with multi-layer feature aggregation (MFA). Meanwhile, in vision tasks, ConvNet structures have been modernized by referring to Transformer, resulting in improved performance. In this paper, we present an improved block design for TDNN in speaker verification. Inspired by recent ConvNet structures, we replace the SE-Res2Net block in ECAPA-TDNN with a novel 1D two-step multi-scale ConvNeXt block, which we call TS-ConvNeXt. The TS-ConvNeXt block is constructed using two separated sub-modules: a temporal multi-scale convolution (MSC) and a frame-wise feed-forward network (FFN). This two-step design allows for flexible capturing of inter-frame and intra-frame contexts. Additionally, we introduce global response normalization (GRN) for the FFN modules to enable more selective feature propagation, similar to the SE module in ECAPA-TDNN. Experimental results demonstrate that NeXt-TDNN, with a modernized backbone block, significantly improved performance in speaker verification tasks while reducing parameter size and inference time. We have released our code for future studies.
Statistical Beamformer Exploiting Non-stationarity and Sparsity with Spatially Constrained ICA for Robust Speech Recognition
Jun 13, 2023In this paper, we present a statistical beamforming algorithm as a pre-processing step for robust automatic speech recognition (ASR). By modeling the target speech as a non-stationary Laplacian distribution, a mask-based statistical beamforming algorithm is proposed to exploit both its output and masked input variance for robust estimation of the beamformer. In addition, we also present a method for steering vector estimation (SVE) based on a noise power ratio obtained from the target and noise outputs in independent component analysis (ICA). To update the beamformer in the same ICA framework, we derive ICA with distortionless and null constraints on target speech, which yields beamformed speech at the target output and noises at the other outputs, respectively. The demixing weights for the target output result in a statistical beamformer with the weighted spatial covariance matrix (wSCM) using a weighting function characterized by a source model. To enhance the SVE, the strict null constraints imposed by the Lagrange multiplier methods are relaxed by generalized penalties with weight parameters, while the strict distortionless constraints are maintained. Furthermore, we derive an online algorithm based on an optimization technique of recursive least squares (RLS) for practical applications. Experimental results on various environments using CHiME-4 and LibriCSS datasets demonstrate the effectiveness of the presented algorithm compared to conventional beamforming and blind source extraction (BSE) based on ICA on both batch and online processing.