 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocalAgent: Large Language Models for Vocal Health Diagnostics with Safety-Aware Evaluation
May 19, 2025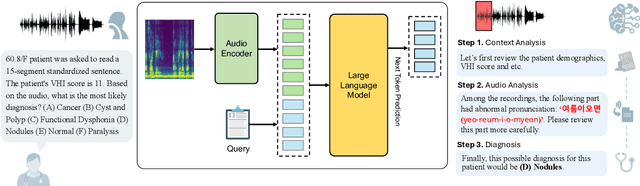
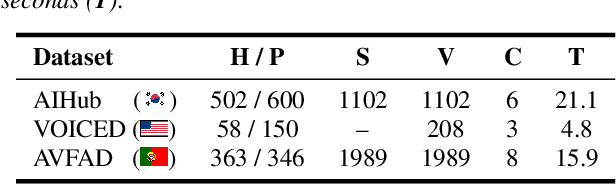
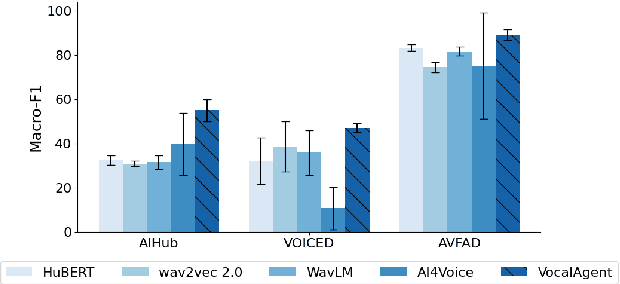
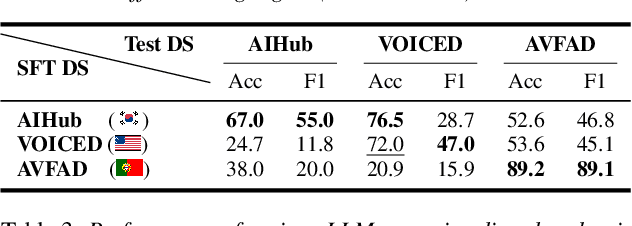
Vocal health plays a crucial role in peoples' lives, significantly impacting their communicative abilities and interactions. However, despite the global prevalence of voice disorders, many lack access to convenient diagnosis and treatment. This paper introduces VocalAgent, an audio large language model (LLM) to address these challenges through vocal health diagnosis. We leverage Qwen-Audio-Chat fine-tuned on three datasets collected in-situ from hospital patients, and present a multifaceted evaluation framework encompassing a safety assessment to mitigate diagnostic biases, cross-lingual performance analysis, and modality ablation studies. VocalAgent demonstrates superior accuracy on voice disorder classification compared to state-of-the-art baselines. Its LLM-based method offers a scalable solution for broader adoption of health diagnostics, while underscoring the importance of ethical and technical validation.
Frozen Large Language Models Can Perceive Paralinguistic Aspects of Speech
Oct 02, 2024



As speech becomes an increasingly common modality for interacting with large language models (LLMs), it is becoming desirable to develop systems where LLMs can take into account users' emotions or speaking styles when providing their responses. In this work, we study the potential of an LLM to understand these aspects of speech without fine-tuning its weights. To do this, we utilize an end-to-end system with a speech encoder; the encoder is trained to produce token embeddings such that the LLM's response to an expressive speech prompt is aligned with its response to a semantically matching text prompt where the speaker's emotion has also been specified. We find that this training framework allows the encoder to generate tokens that capture both semantic and paralinguistic information in speech and effectively convey it to the LLM, even when the LLM remains completely frozen. We also explore training on additional emotion and style-related response alignment tasks, finding that they further increase the amount of paralinguistic information explicitly captured in the speech tokens. Experiments demonstrate that our system is able to produce higher quality and more empathetic responses to expressive speech prompts compared to several baselines.
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Jun 10, 2024In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Multi-Task Learning for Front-End Text Processing in TTS
Jan 12, 2024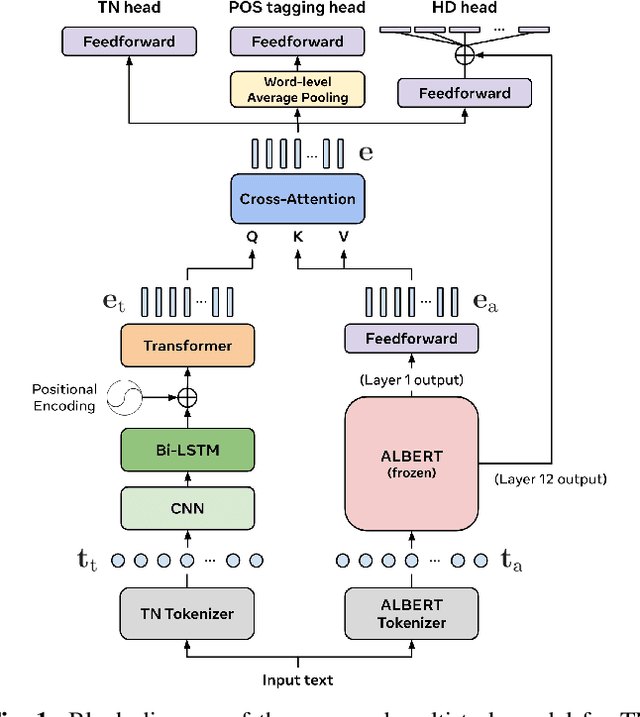


We propose a multi-task learning (MTL) model for jointly performing three tasks that are commonly solved in a text-to-speech (TTS) front-end: text normalization (TN), part-of-speech (POS) tagging, and homograph disambiguation (HD). Our framework utilizes a tree-like structure with a trunk that learns shared representations, followed by separate task-specific heads. We further incorporate a pre-trained language model to utilize its built-in lexical and contextual knowledge, and study how to best use its embeddings so as to most effectively benefit our multi-task model. Through task-wise ablations, we show that our full model trained on all three tasks achieves the strongest overall performance compared to models trained on individual or sub-combinations of tasks, confirming the advantages of our MTL framework. Finally, we introduce a new HD dataset containing a balanced number of sentences in diverse contexts for a variety of homographs and their pronunciations. We demonstrate that incorporating this dataset into training significantly improves HD performance over only using a commonly used, but imbalanced, pre-existing dataset.
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
May 23, 2023We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
End-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
May 19, 2022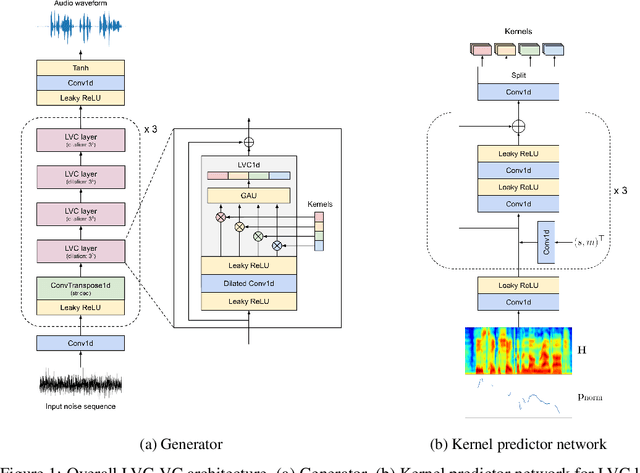
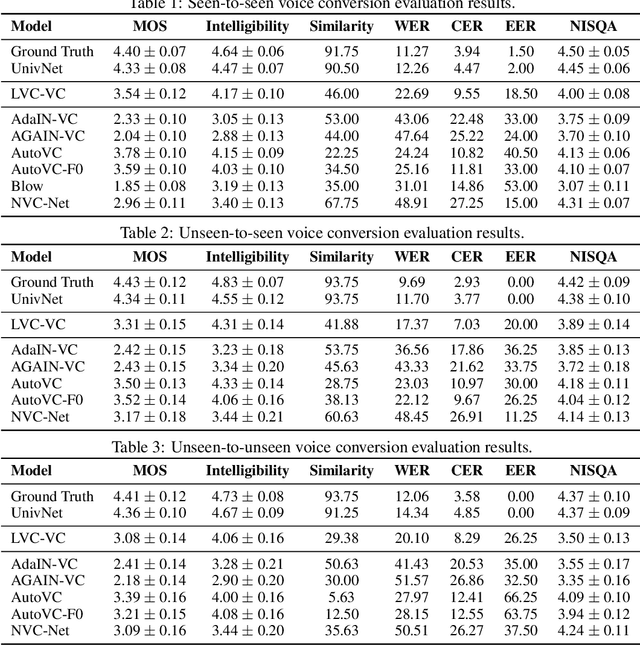

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.