 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Front-End Text Processing in TTS
Paper and Code
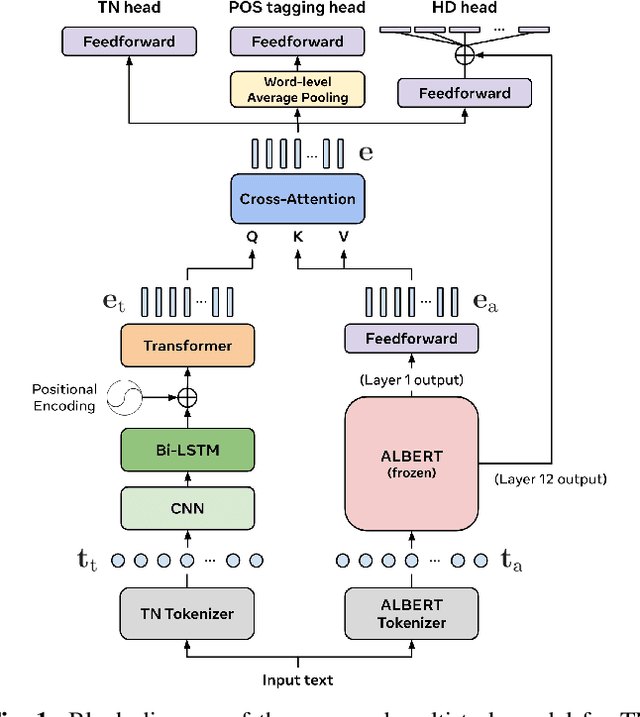


We propose a multi-task learning (MTL) model for jointly performing three tasks that are commonly solved in a text-to-speech (TTS) front-end: text normalization (TN), part-of-speech (POS) tagging, and homograph disambiguation (HD). Our framework utilizes a tree-like structure with a trunk that learns shared representations, followed by separate task-specific heads. We further incorporate a pre-trained language model to utilize its built-in lexical and contextual knowledge, and study how to best use its embeddings so as to most effectively benefit our multi-task model. Through task-wise ablations, we show that our full model trained on all three tasks achieves the strongest overall performance compared to models trained on individual or sub-combinations of tasks, confirming the advantages of our MTL framework. Finally, we introduce a new HD dataset containing a balanced number of sentences in diverse contexts for a variety of homographs and their pronunciations. We demonstrate that incorporating this dataset into training significantly improves HD performance over only using a commonly used, but imbalanced, pre-existing dataset.