 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Frozen Large Language Models Can Perceive Paralinguistic Aspects of Speech
Oct 02, 2024



As speech becomes an increasingly common modality for interacting with large language models (LLMs), it is becoming desirable to develop systems where LLMs can take into account users' emotions or speaking styles when providing their responses. In this work, we study the potential of an LLM to understand these aspects of speech without fine-tuning its weights. To do this, we utilize an end-to-end system with a speech encoder; the encoder is trained to produce token embeddings such that the LLM's response to an expressive speech prompt is aligned with its response to a semantically matching text prompt where the speaker's emotion has also been specified. We find that this training framework allows the encoder to generate tokens that capture both semantic and paralinguistic information in speech and effectively convey it to the LLM, even when the LLM remains completely frozen. We also explore training on additional emotion and style-related response alignment tasks, finding that they further increase the amount of paralinguistic information explicitly captured in the speech tokens. Experiments demonstrate that our system is able to produce higher quality and more empathetic responses to expressive speech prompts compared to several baselines.
PRoDeliberation: Parallel Robust Deliberation for End-to-End Spoken Language Understanding
Jun 12, 2024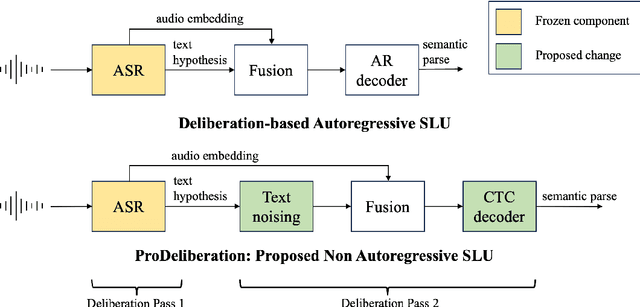
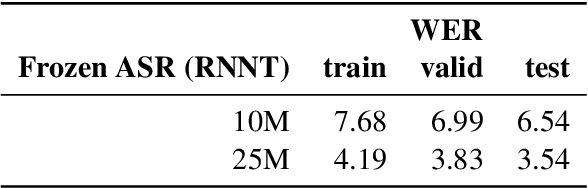
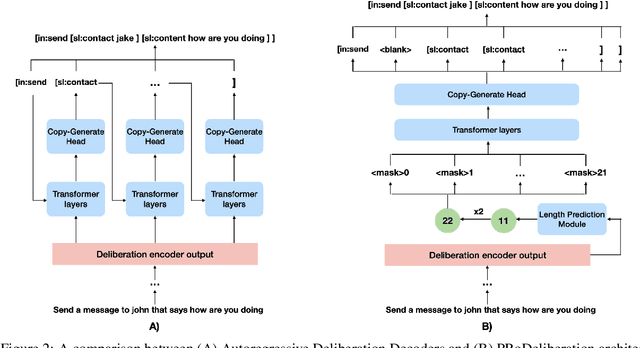

Spoken Language Understanding (SLU) is a critical component of voice assistants; it consists of converting speech to semantic parses for task execution. Previous works have explored end-to-end models to improve the quality and robustness of SLU models with Deliberation, however these models have remained autoregressive, resulting in higher latencies. In this work we introduce PRoDeliberation, a novel method leveraging a Connectionist Temporal Classification-based decoding strategy as well as a denoising objective to train robust non-autoregressive deliberation models. We show that PRoDeliberation achieves the latency reduction of parallel decoding (2-10x improvement over autoregressive models) while retaining the ability to correct Automatic Speech Recognition (ASR) mistranscriptions of autoregressive deliberation systems. We further show that the design of the denoising training allows PRoDeliberation to overcome the limitations of small ASR devices, and we provide analysis on the necessity of each component of the system.
Augmenting text for spoken language understanding with Large Language Models
Sep 17, 2023



Spoken semantic parsing (SSP) involves generating machine-comprehensible parses from input speech. Training robust models for existing application domains represented in training data or extending to new domains requires corresponding triplets of speech-transcript-semantic parse data, which is expensive to obtain. In this paper, we address this challenge by examining methods that can use transcript-semantic parse data (unpaired text) without corresponding speech. First, when unpaired text is drawn from existing textual corpora, Joint Audio Text (JAT) and Text-to-Speech (TTS) are compared as ways to generate speech representations for unpaired text. Experiments on the STOP dataset show that unpaired text from existing and new domains improves performance by 2% and 30% in absolute Exact Match (EM) respectively. Second, we consider the setting when unpaired text is not available in existing textual corpora. We propose to prompt Large Language Models (LLMs) to generate unpaired text for existing and new domains. Experiments show that examples and words that co-occur with intents can be used to generate unpaired text with Llama 2.0. Using the generated text with JAT and TTS for spoken semantic parsing improves EM on STOP by 1.4% and 2.6% absolute for existing and new domains respectively.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Introducing Semantics into Speech Encoders
Nov 15, 2022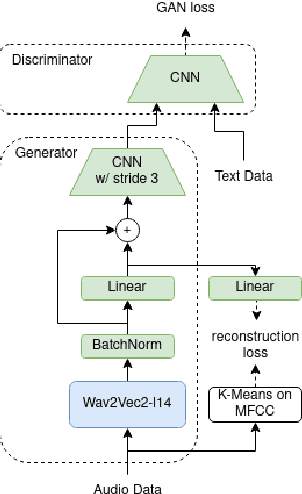
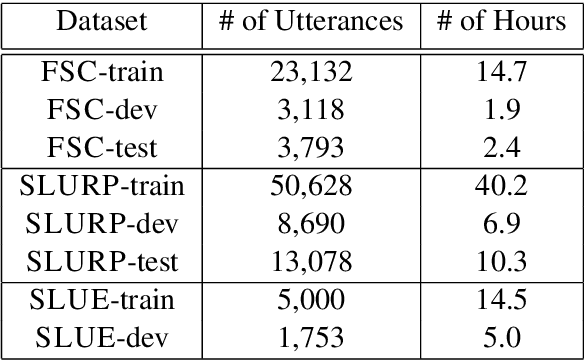
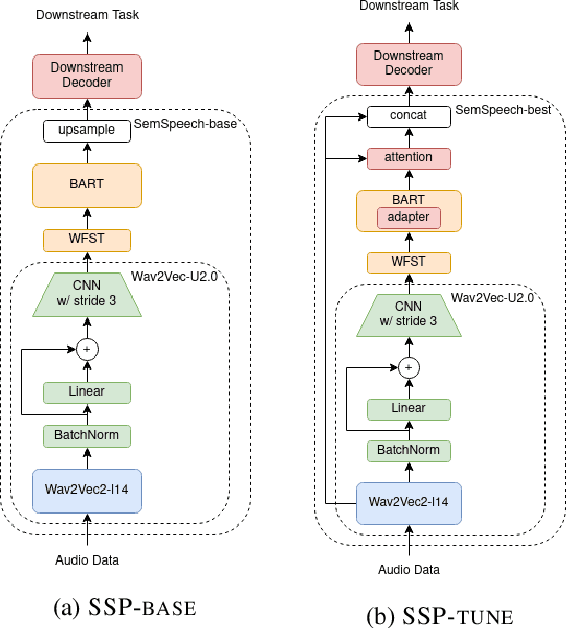
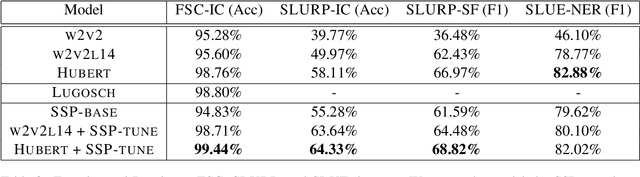
Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
Joint Audio/Text Training for Transformer Rescorer of Streaming Speech Recognition
Oct 31, 2022



Recently, there has been an increasing interest in two-pass streaming end-to-end speech recognition (ASR) that incorporates a 2nd-pass rescoring model on top of the conventional 1st-pass streaming ASR model to improve recognition accuracy while keeping latency low. One of the latest 2nd-pass rescoring model, Transformer Rescorer, takes the n-best initial outputs and audio embeddings from the 1st-pass model, and then choose the best output by re-scoring the n-best initial outputs. However, training this Transformer Rescorer requires expensive paired audio-text training data because the model uses audio embeddings as input. In this work, we present our Joint Audio/Text training method for Transformer Rescorer, to leverage unpaired text-only data which is relatively cheaper than paired audio-text data. We evaluate Transformer Rescorer with our Joint Audio/Text training on Librispeech dataset as well as our large-scale in-house dataset and show that our training method can improve word error rate (WER) significantly compared to standard Transformer Rescorer without requiring any extra model parameters or latency.
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022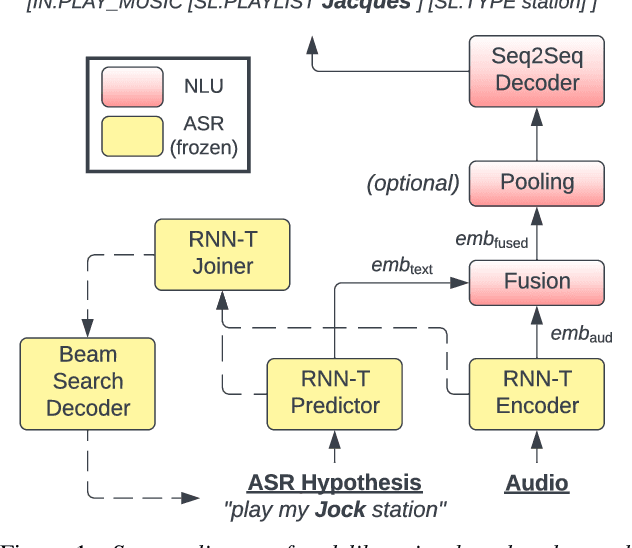

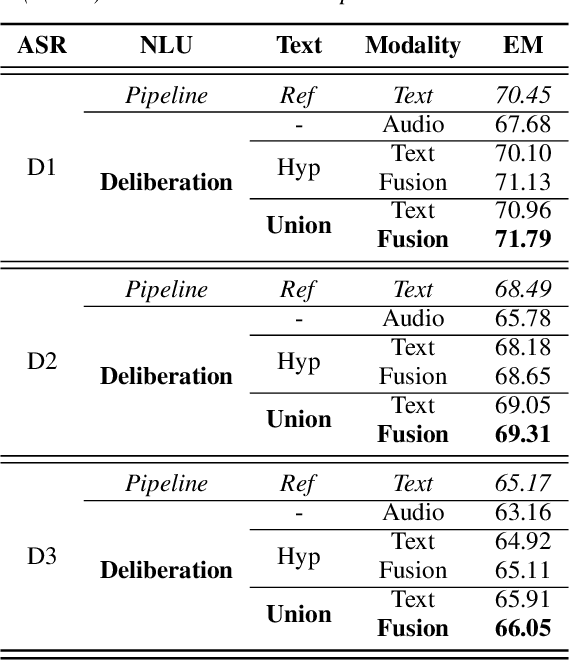
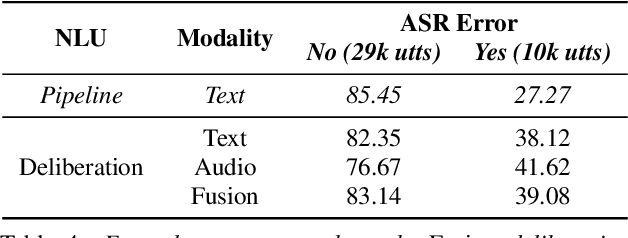
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021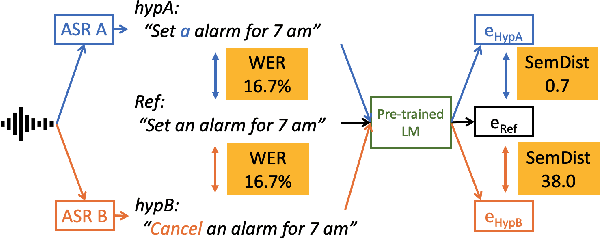
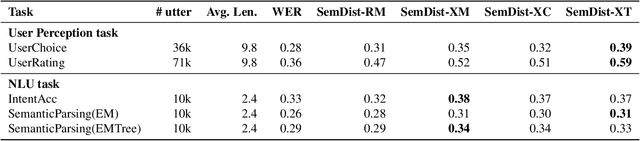
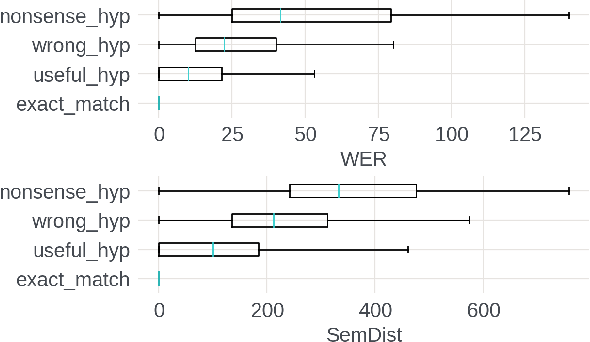
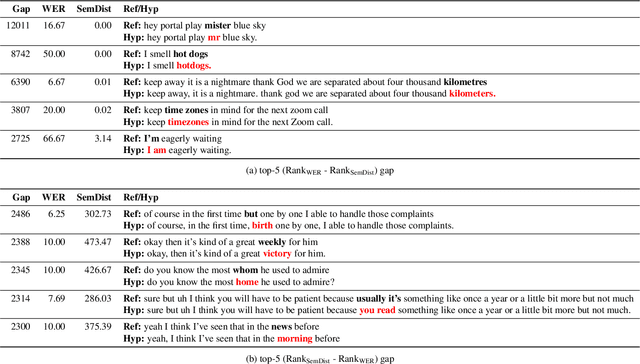
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.
Contextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion
Apr 05, 2021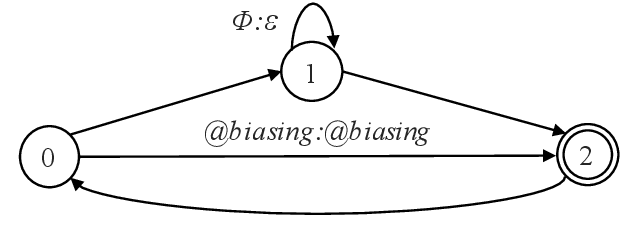
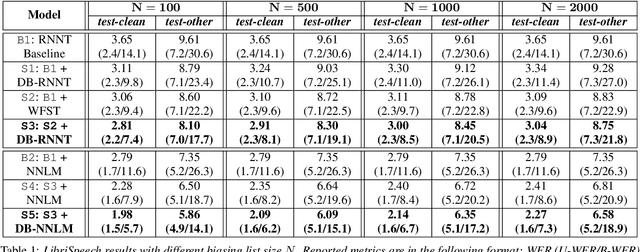
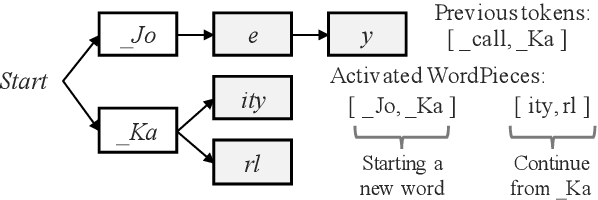
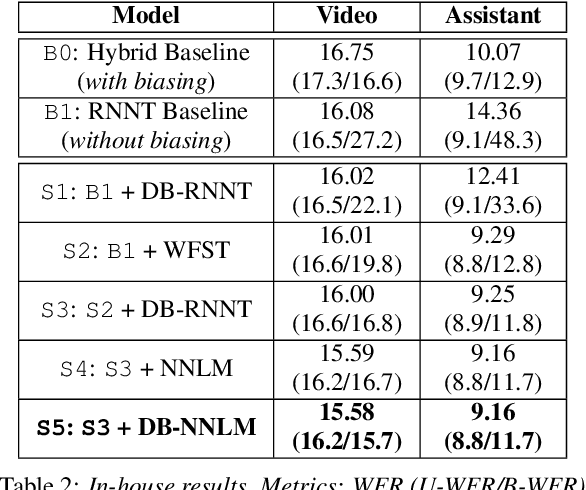
How to leverage dynamic contextual information in end-to-end speech recognition has remained an active research area. Previous solutions to this problem were either designed for specialized use cases that did not generalize well to open-domain scenarios, did not scale to large biasing lists, or underperformed on rare long-tail words. We address these limitations by proposing a novel solution that combines shallow fusion, trie-based deep biasing, and neural network language model contextualization. These techniques result in significant 19.5% relative Word Error Rate improvement over existing contextual biasing approaches and 5.4%-9.3% improvement compared to a strong hybrid baseline on both open-domain and constrained contextualization tasks, where the targets consist of mostly rare long-tail words. Our final system remains lightweight and modular, allowing for quick modification without model re-training.