 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Audio/Text Training for Transformer Rescorer of Streaming Speech Recognition
Oct 31, 2022



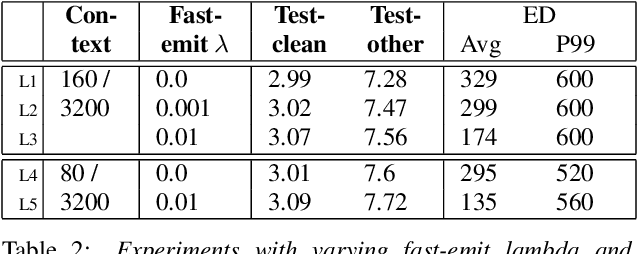
Recently, there has been an increasing interest in two-pass streaming end-to-end speech recognition (ASR) that incorporates a 2nd-pass rescoring model on top of the conventional 1st-pass streaming ASR model to improve recognition accuracy while keeping latency low. One of the latest 2nd-pass rescoring model, Transformer Rescorer, takes the n-best initial outputs and audio embeddings from the 1st-pass model, and then choose the best output by re-scoring the n-best initial outputs. However, training this Transformer Rescorer requires expensive paired audio-text training data because the model uses audio embeddings as input. In this work, we present our Joint Audio/Text training method for Transformer Rescorer, to leverage unpaired text-only data which is relatively cheaper than paired audio-text data. We evaluate Transformer Rescorer with our Joint Audio/Text training on Librispeech dataset as well as our large-scale in-house dataset and show that our training method can improve word error rate (WER) significantly compared to standard Transformer Rescorer without requiring any extra model parameters or latency.
Dynamic Speech Endpoint Detection with Regression Targets
Oct 25, 2022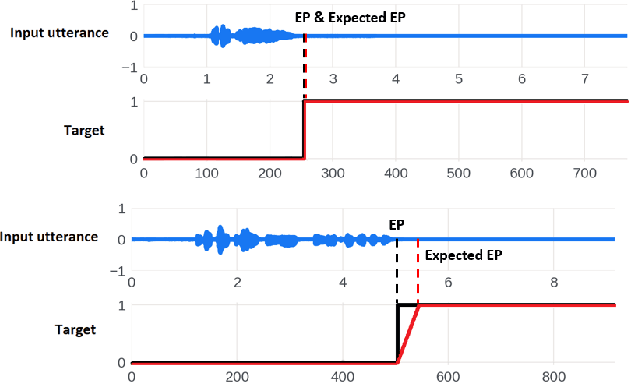

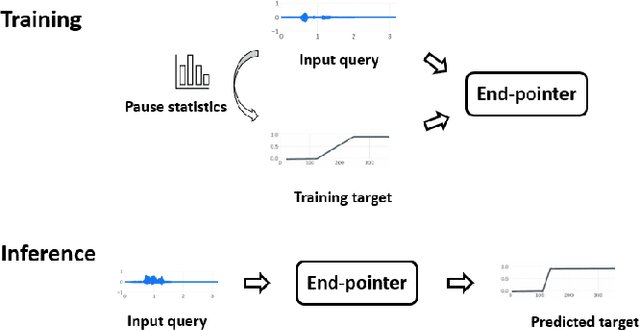

Interactive voice assistants have been widely used as input interfaces in various scenarios, e.g. on smart homes devices, wearables and on AR devices. Detecting the end of a speech query, i.e. speech end-pointing, is an important task for voice assistants to interact with users. Traditionally, speech end-pointing is based on pure classification methods along with arbitrary binary targets. In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method. We further discuss the benefits of this model and generalization of the framework in the paper.
Streaming parallel transducer beam search with fast-slow cascaded encoders
Mar 29, 2022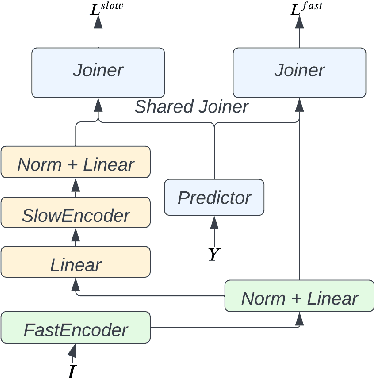
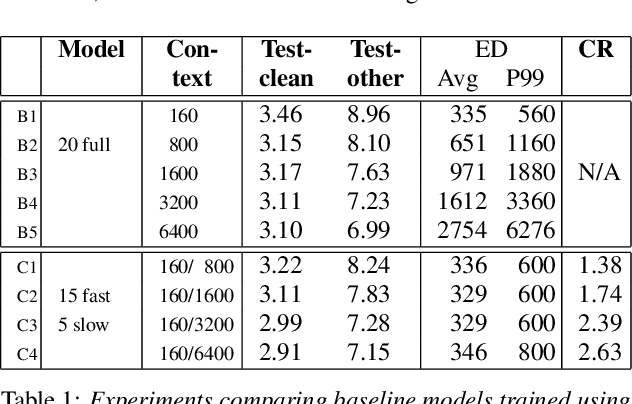
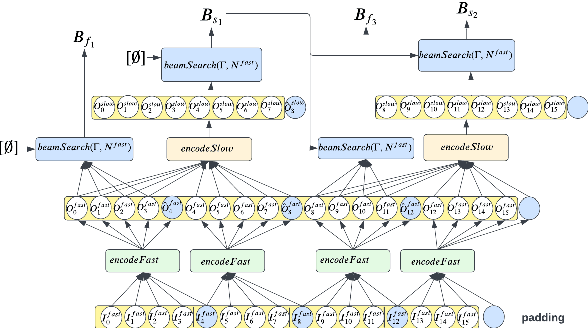
Streaming ASR with strict latency constraints is required in many speech recognition applications. In order to achieve the required latency, streaming ASR models sacrifice accuracy compared to non-streaming ASR models due to lack of future input context. Previous research has shown that streaming and non-streaming ASR for RNN Transducers can be unified by cascading causal and non-causal encoders. This work improves upon this cascaded encoders framework by leveraging two streaming non-causal encoders with variable input context sizes that can produce outputs at different audio intervals (e.g. fast and slow). We propose a novel parallel time-synchronous beam search algorithm for transducers that decodes from fast-slow encoders, where the slow encoder corrects the mistakes generated from the fast encoder. The proposed algorithm, achieves up to 20% WER reduction with a slight increase in token emission delays on the public Librispeech dataset and in-house datasets. We also explore techniques to reduce the computation by distributing processing between the fast and slow encoders. Lastly, we explore sharing the parameters in the fast encoder to reduce the memory footprint. This enables low latency processing on edge devices with low computation cost and a low memory footprint.
Efficient Dynamic WFST Decoding for Personalized Language Models
Oct 23, 2019
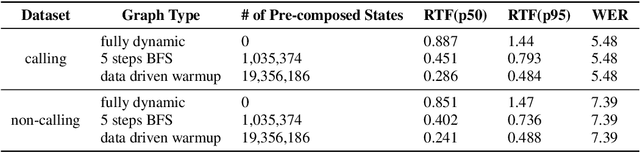
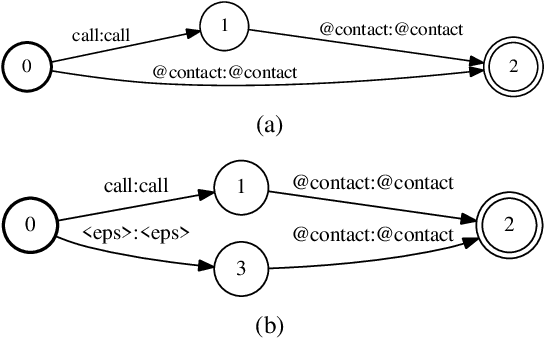
We propose a two-layer cache mechanism to speed up dynamic WFST decoding with personalized language models. The first layer is a public cache that stores most of the static part of the graph. This is shared globally among all users. A second layer is a private cache that caches the graph that represents the personalized language model, which is only shared by the utterances from a particular user. We also propose two simple yet effective pre-initialization methods, one based on breadth-first search, and another based on a data-driven exploration of decoder states using previous utterances. Experiments with a calling speech recognition task using a personalized contact list demonstrate that the proposed public cache reduces decoding time by factor of three compared to decoding without pre-initialization. Using the private cache provides additional efficiency gains, reducing the decoding time by a factor of five.