 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Dynamic Speech Endpoint Detection with Regression Targets
Oct 25, 2022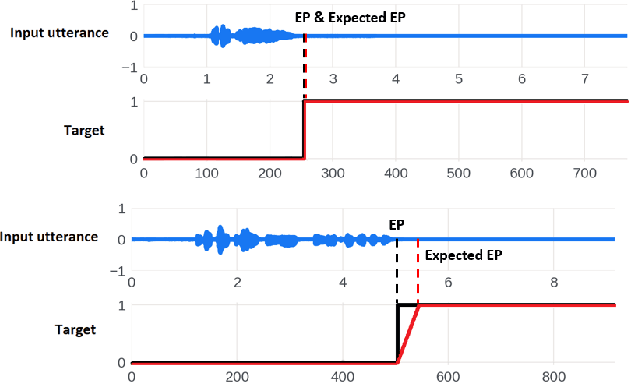

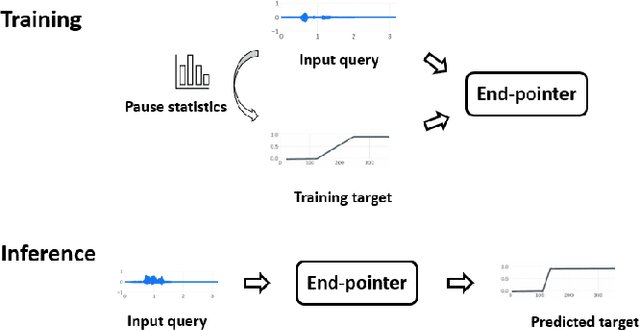

Interactive voice assistants have been widely used as input interfaces in various scenarios, e.g. on smart homes devices, wearables and on AR devices. Detecting the end of a speech query, i.e. speech end-pointing, is an important task for voice assistants to interact with users. Traditionally, speech end-pointing is based on pure classification methods along with arbitrary binary targets. In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method. We further discuss the benefits of this model and generalization of the framework in the paper.
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021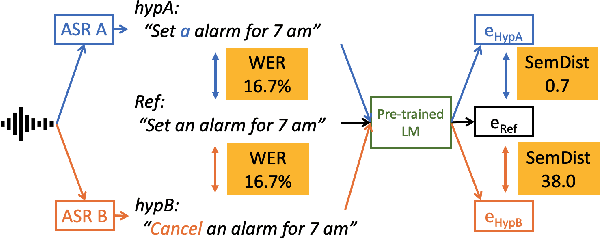
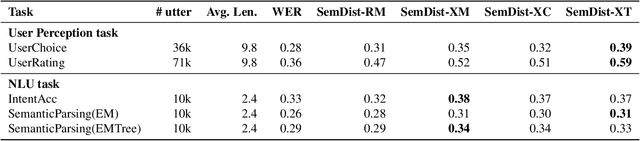
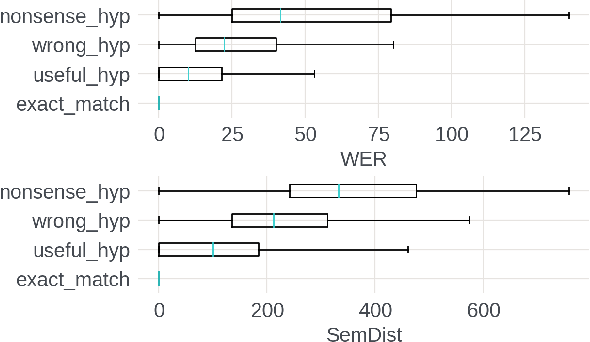
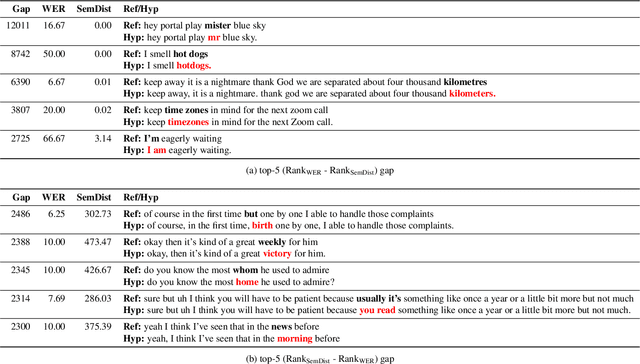
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.