 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Federated Domain Adaptation for ASR with Full Self-Supervision
Apr 05, 2022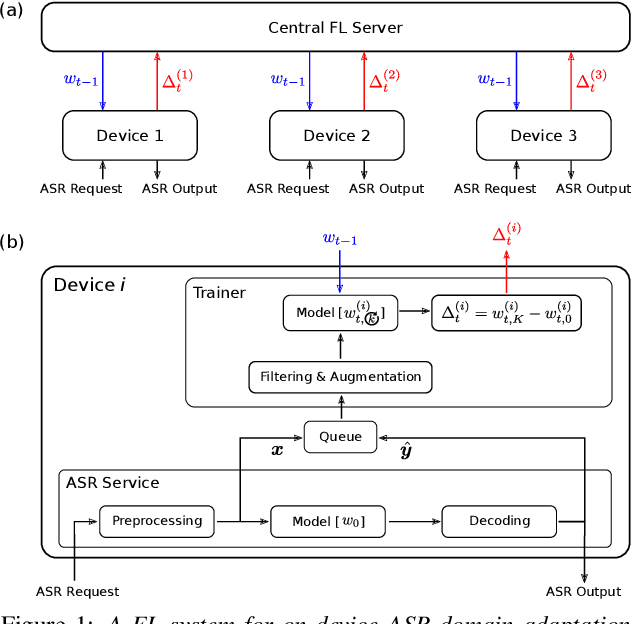

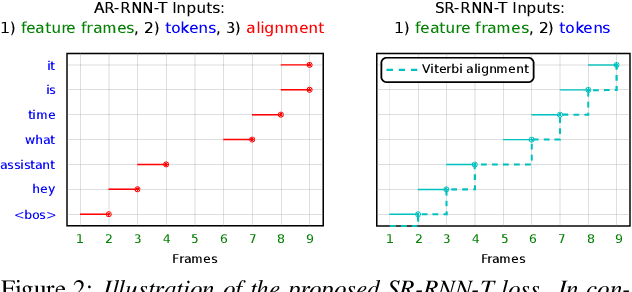
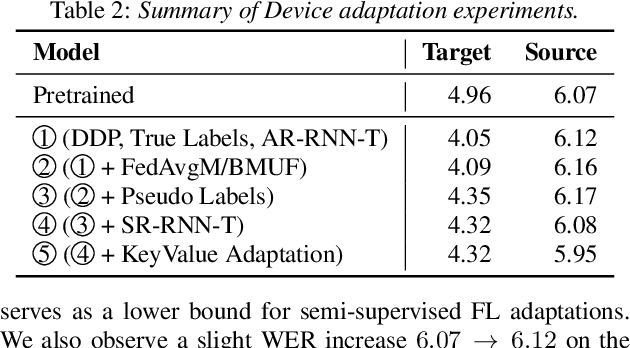
Cross-device federated learning (FL) protects user privacy by collaboratively training a model on user devices, therefore eliminating the need for collecting, storing, and manually labeling user data. While important topics such as the FL training algorithm, non-IID-ness, and Differential Privacy have been well studied in the literature, this paper focuses on two challenges of practical importance for improving on-device ASR: the lack of ground-truth transcriptions and the scarcity of compute resource and network bandwidth on edge devices. First, we propose a FL system for on-device ASR domain adaptation with full self-supervision, which uses self-labeling together with data augmentation and filtering techniques. The system can improve a strong Emformer-Transducer based ASR model pretrained on out-of-domain data, using in-domain audio without any ground-truth transcriptions. Second, to reduce the training cost, we propose a self-restricted RNN Transducer (SR-RNN-T) loss, a variant of alignment-restricted RNN-T that uses Viterbi alignments from self-supervision. To further reduce the compute and network cost, we systematically explore adapting only a subset of weights in the Emformer-Transducer. Our best training recipe achieves a $12.9\%$ relative WER reduction over the strong out-of-domain baseline, which equals $70\%$ of the reduction achievable with full human supervision and centralized training.
Scaling ASR Improves Zero and Few Shot Learning
Nov 29, 2021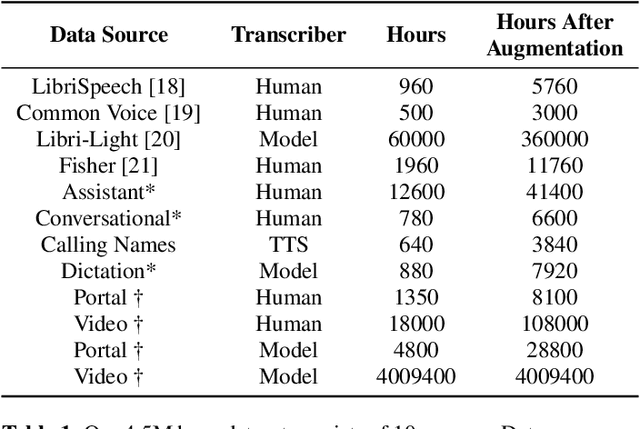
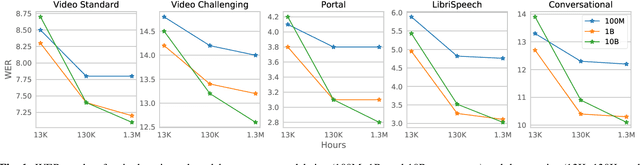
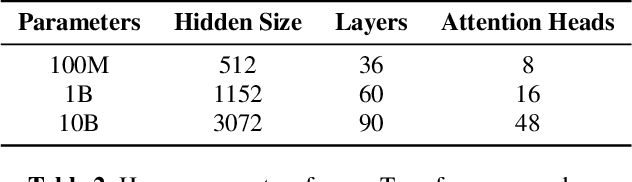
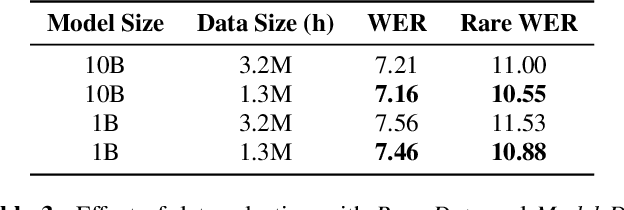
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021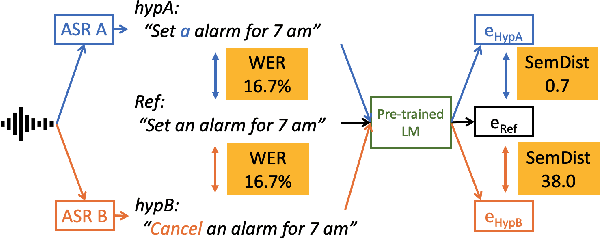
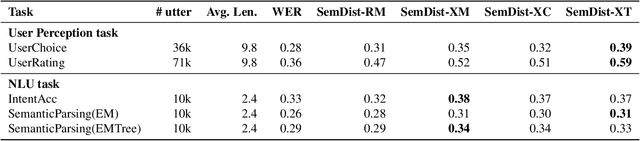
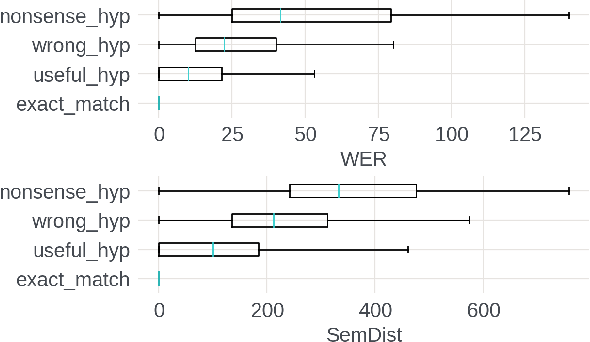
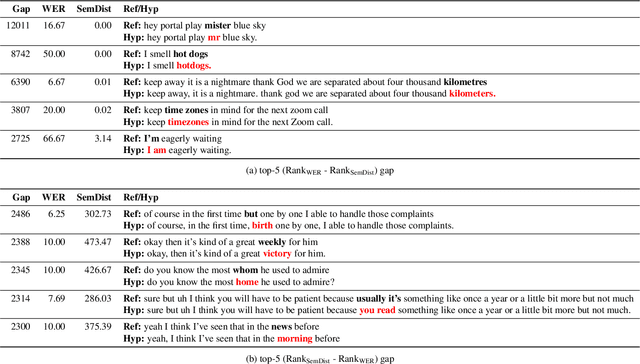
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Dec 17, 2019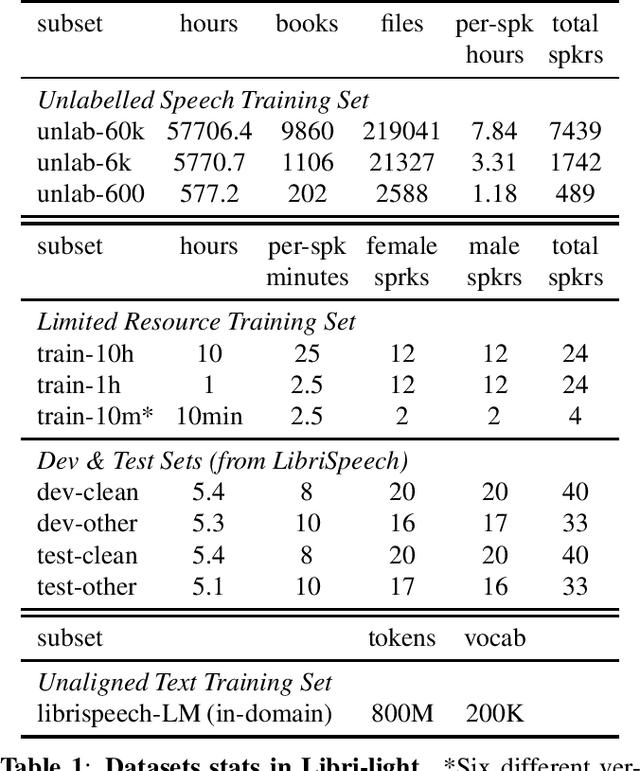
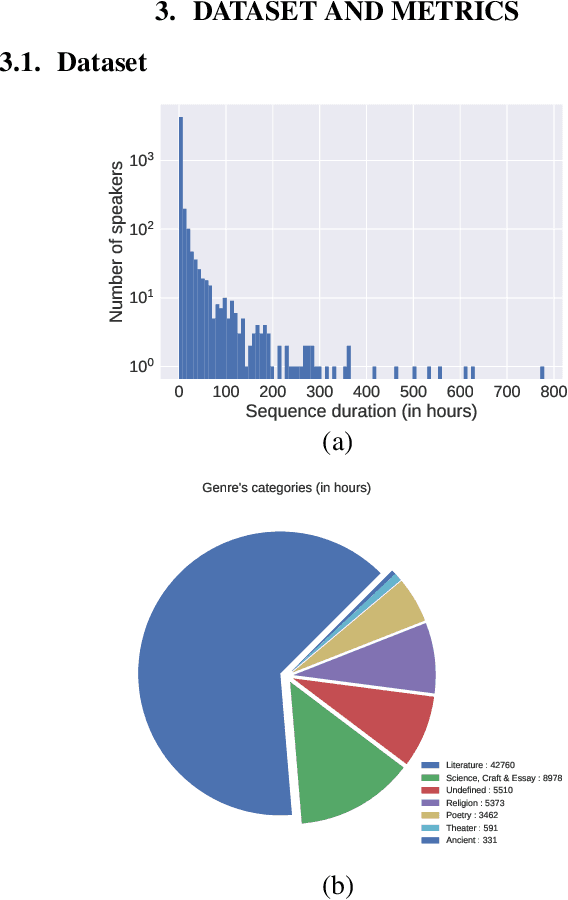
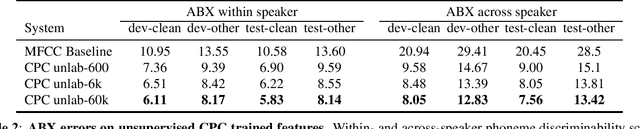
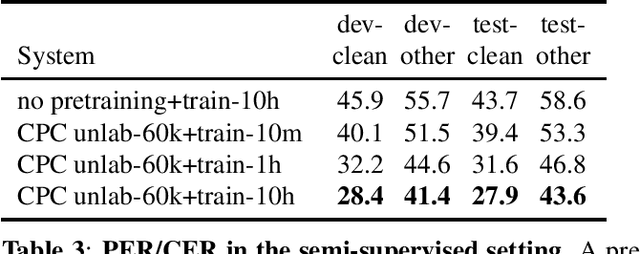
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.
From Senones to Chenones: Tied Context-Dependent Graphemes for Hybrid Speech Recognition
Oct 11, 2019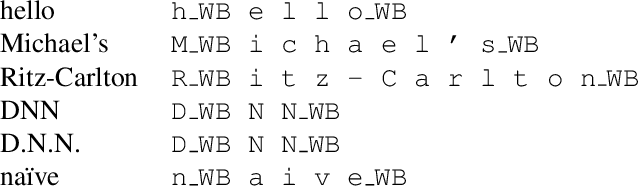
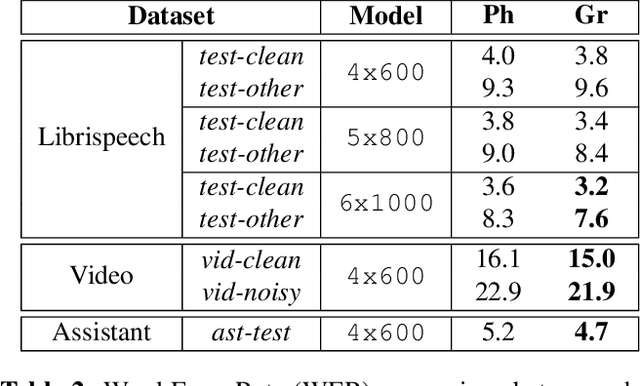
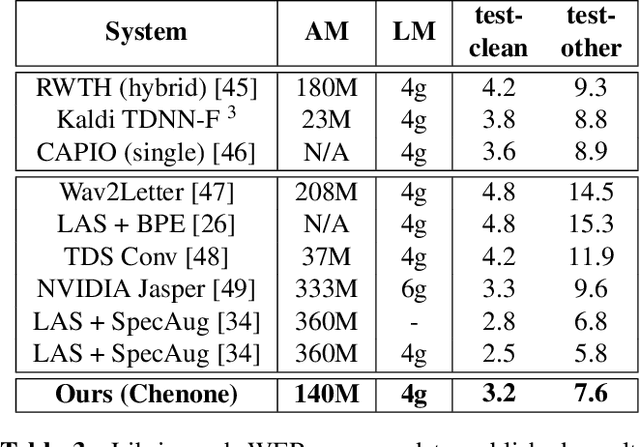
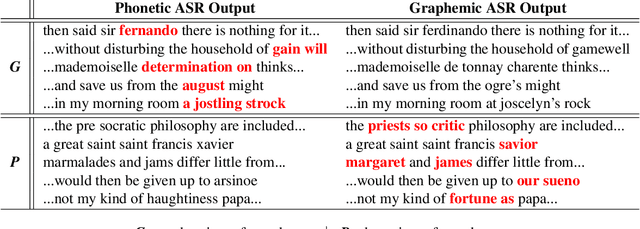
There is an implicit assumption that traditional hybrid approaches for automatic speech recognition (ASR) cannot directly model graphemes and need to rely on phonetic lexicons to get competitive performance, especially on English which has poor grapheme-phoneme correspondence. In this work, we show for the first time that, on English, hybrid ASR systems can in fact model graphemes effectively by leveraging tied context-dependent graphemes, i.e., chenones. Our chenone-based systems significantly outperform equivalent senone baselines by 4.5% to 11.1% relative on three different English datasets. Our results on Librispeech are state-of-the-art compared to other hybrid approaches and competitive with previously published end-to-end numbers. Further analysis shows that chenones can better utilize powerful acoustic models and large training data, and require context- and position-dependent modeling to work well. Chenone-based systems also outperform senone baselines on proper noun and rare word recognition, an area where the latter is traditionally thought to have an advantage. Our work provides an alternative for end-to-end ASR and establishes that hybrid systems can be improved by dropping the reliance on phonetic knowledge.