 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Conditional Diffusion Transformer for Underwater Image Enhancement
Jul 07, 2024



Underwater image enhancement (UIE) has attracted much attention owing to its importance for underwater operation and marine engineering. Motivated by the recent advance in generative models, we propose a novel UIE method based on image-conditional diffusion transformer (ICDT). Our method takes the degraded underwater image as the conditional input and converts it into latent space where ICDT is applied. ICDT replaces the conventional U-Net backbone in a denoising diffusion probabilistic model (DDPM) with a transformer, and thus inherits favorable properties such as scalability from transformers. Furthermore, we train ICDT with a hybrid loss function involving variances to achieve better log-likelihoods, which meanwhile significantly accelerates the sampling process. We experimentally assess the scalability of ICDTs and compare with prior works in UIE on the Underwater ImageNet dataset. Besides good scaling properties, our largest model, ICDT-XL/2, outperforms all comparison methods, achieving state-of-the-art (SOTA) quality of image enhancement.
Classification of Power Quality Disturbances Using Resnet with Channel Attention Mechanism
Jul 02, 2024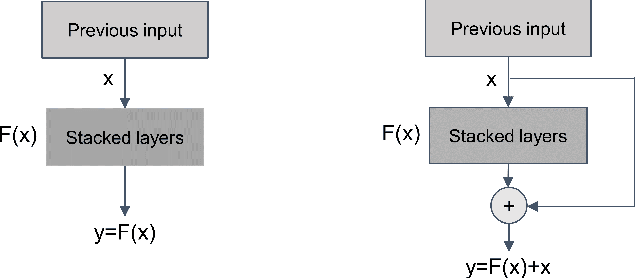
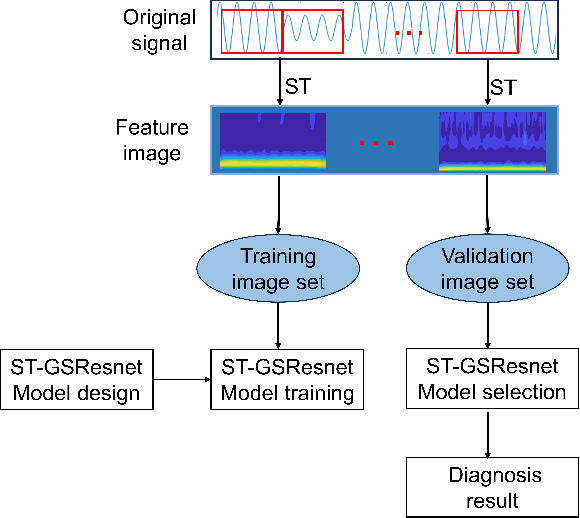
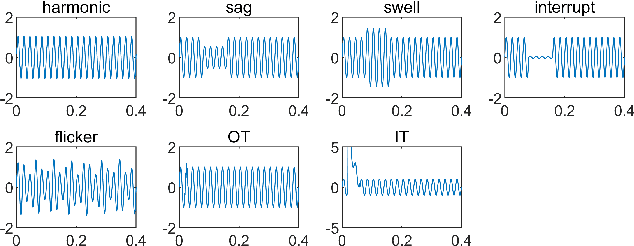
The detection and classification of power quality disturbances (PQDs) carries significant importance for power systems. In response to this imperative, numerous intelligent diagnostic methods have been developed. However, existing identification methods usually concentrate on single-type signals or on complex signals with two types, rendering them susceptible to noisy labels and environmental effects. This study proposes a novel method for the classification of PQDs, termed ST-GSResNet, which utilizes the S-Transform and an improved residual neural network (ResNet) with a channel attention mechanism. The ST-GSResNet approach initially uses the S-Transform to transform a time-series signal into a 2D time-frequency image for feature enhancement. Then, an improved ResNet model is introduced, which employs grouped convolution instead of the traditional convolution operation. This improvement aims to facilitate learning with a block-diagonal structured sparsity on the channel dimension, the highly-correlated filters are learned in a more structured way in the networks with filter groups. By reducing the number of parameters in the network in this significant manner, the model becomes less prone to overfitting. Furthermore, the SE module concentrates on primary components, which enhances the model's robustness in recognition and immunity to noise. Experimental results demonstrate that, compared to existing deep learning models, our approach has advantages in computational efficiency and classification accuracy.
Evaluating User Perception of Speech Recognition System Quality with Semantic Distance Metric
Oct 11, 2021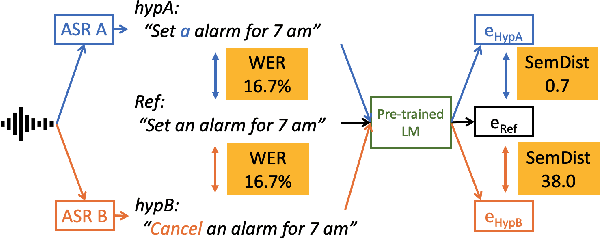
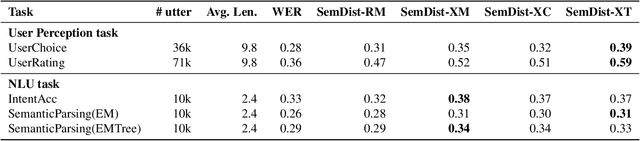
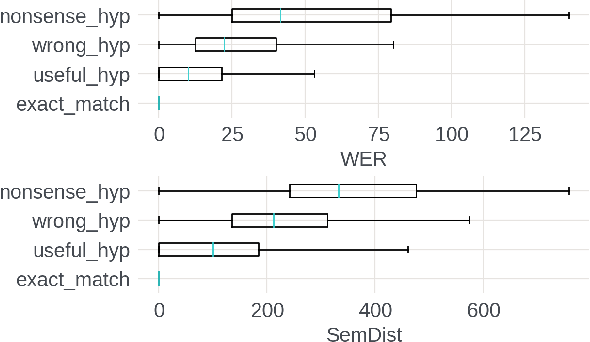
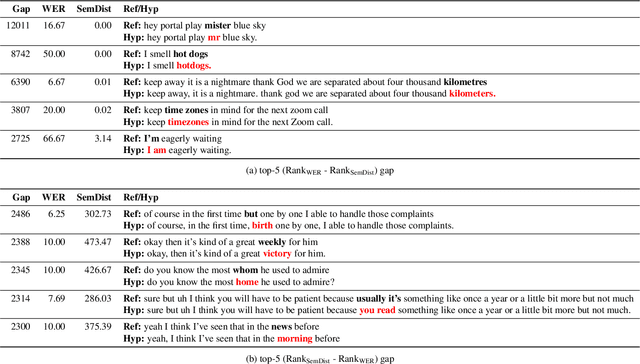
Measuring automatic speech recognition (ASR) system quality is critical for creating user-satisfying voice-driven applications. Word Error Rate (WER) has been traditionally used to evaluate ASR system quality; however, it sometimes correlates poorly with user perception of transcription quality. This is because WER weighs every word equally and does not consider semantic correctness which has a higher impact on user perception. In this work, we propose evaluating ASR output hypotheses quality with SemDist that can measure semantic correctness by using the distance between the semantic vectors of the reference and hypothesis extracted from a pre-trained language model. Our experimental results of 71K and 36K user annotated ASR output quality show that SemDist achieves higher correlation with user perception than WER. We also show that SemDist has higher correlation with downstream NLU tasks than WER.