 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Non-Monotonic Attention-based Read/Write Policy Learning for Simultaneous Translation
Mar 28, 2025Simultaneous or streaming machine translation generates translation while reading the input stream. These systems face a quality/latency trade-off, aiming to achieve high translation quality similar to non-streaming models with minimal latency. We propose an approach that efficiently manages this trade-off. By enhancing a pretrained non-streaming model, which was trained with a seq2seq mechanism and represents the upper bound in quality, we convert it into a streaming model by utilizing the alignment between source and target tokens. This alignment is used to learn a read/write decision boundary for reliable translation generation with minimal input. During training, the model learns the decision boundary through a read/write policy module, employing supervised learning on the alignment points (pseudo labels). The read/write policy module, a small binary classification unit, can control the quality/latency trade-off during inference. Experimental results show that our model outperforms several strong baselines and narrows the gap with the non-streaming baseline model.
Transcribing and Translating, Fast and Slow: Joint Speech Translation and Recognition
Dec 19, 2024We propose the joint speech translation and recognition (JSTAR) model that leverages the fast-slow cascaded encoder architecture for simultaneous end-to-end automatic speech recognition (ASR) and speech translation (ST). The model is transducer-based and uses a multi-objective training strategy that optimizes both ASR and ST objectives simultaneously. This allows JSTAR to produce high-quality streaming ASR and ST results. We apply JSTAR in a bilingual conversational speech setting with smart-glasses, where the model is also trained to distinguish speech from different directions corresponding to the wearer and a conversational partner. Different model pre-training strategies are studied to further improve results, including training of a transducer-based streaming machine translation (MT) model for the first time and applying it for parameter initialization of JSTAR. We demonstrate superior performances of JSTAR compared to a strong cascaded ST model in both BLEU scores and latency.
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Effective internal language model training and fusion for factorized transducer model
Apr 02, 2024


The internal language model (ILM) of the neural transducer has been widely studied. In most prior work, it is mainly used for estimating the ILM score and is subsequently subtracted during inference to facilitate improved integration with external language models. Recently, various of factorized transducer models have been proposed, which explicitly embrace a standalone internal language model for non-blank token prediction. However, even with the adoption of factorized transducer models, limited improvement has been observed compared to shallow fusion. In this paper, we propose a novel ILM training and decoding strategy for factorized transducer models, which effectively combines the blank, acoustic and ILM scores. Our experiments show a 17% relative improvement over the standard decoding method when utilizing a well-trained ILM and the proposed decoding strategy on LibriSpeech datasets. Furthermore, when compared to a strong RNN-T baseline enhanced with external LM fusion, the proposed model yields a 5.5% relative improvement on general-sets and an 8.9% WER reduction for rare words. The proposed model can achieve superior performance without relying on external language models, rendering it highly efficient for production use-cases. To further improve the performance, we propose a novel and memory-efficient ILM-fusion-aware minimum word error rate (MWER) training method which improves ILM integration significantly.
AGADIR: Towards Array-Geometry Agnostic Directional Speech Recognition
Jan 18, 2024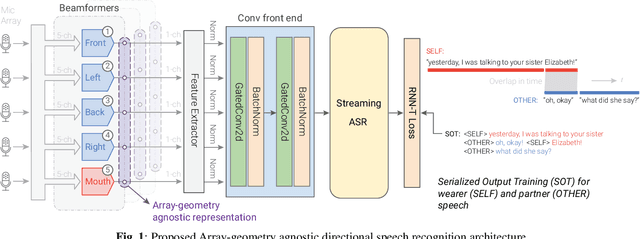

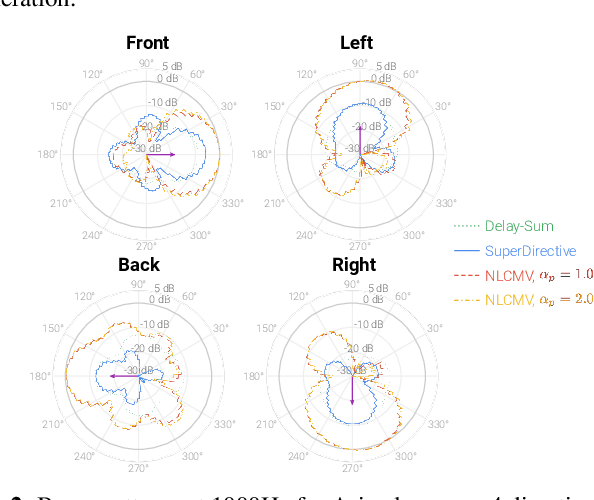

Wearable devices like smart glasses are approaching the compute capability to seamlessly generate real-time closed captions for live conversations. We build on our recently introduced directional Automatic Speech Recognition (ASR) for smart glasses that have microphone arrays, which fuses multi-channel ASR with serialized output training, for wearer/conversation-partner disambiguation as well as suppression of cross-talk speech from non-target directions and noise. When ASR work is part of a broader system-development process, one may be faced with changes to microphone geometries as system development progresses. This paper aims to make multi-channel ASR insensitive to limited variations of microphone-array geometry. We show that a model trained on multiple similar geometries is largely agnostic and generalizes well to new geometries, as long as they are not too different. Furthermore, training the model this way improves accuracy for seen geometries by 15 to 28\% relative. Lastly, we refine the beamforming by a novel Non-Linearly Constrained Minimum Variance criterion.
Towards General-Purpose Speech Abilities for Large Language Models Using Unpaired Data
Nov 12, 2023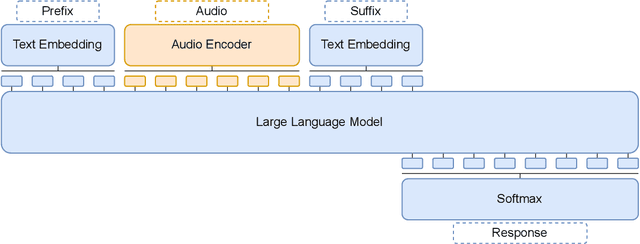

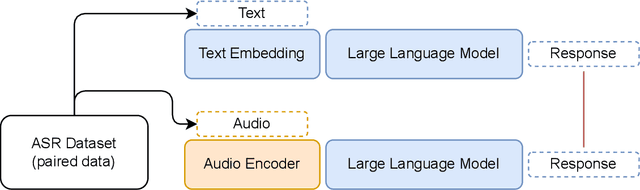
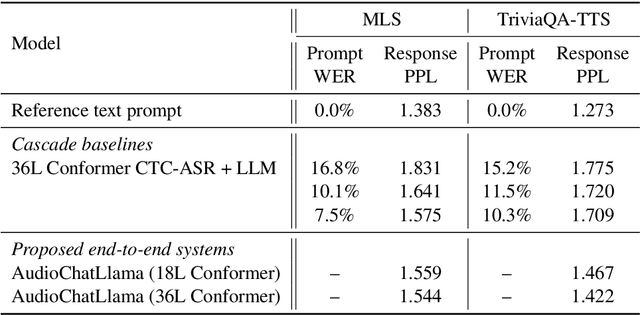
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of LLM capabilities, without using any carefully curated paired data. The proposed model can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform speech question answering, speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. Experiments show that our end-to-end approach is on par with or outperforms a cascaded system (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike a cascade, our approach shows the ability to interchange text and audio modalities and utilize the prior context in a conversation to provide better results.
End-to-End Speech Recognition Contextualization with Large Language Models
Sep 19, 2023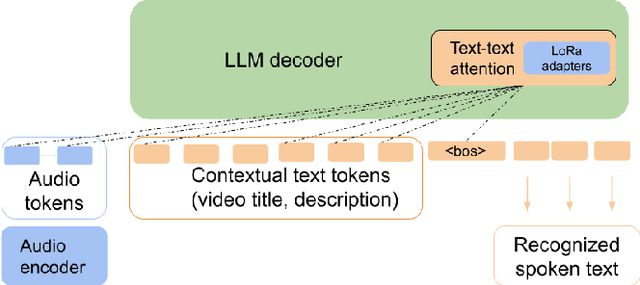

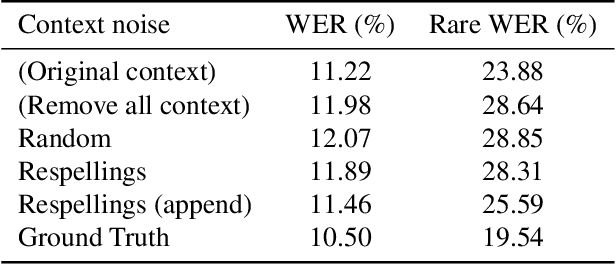

In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
Prompting Large Language Models with Speech Recognition Abilities
Jul 21, 2023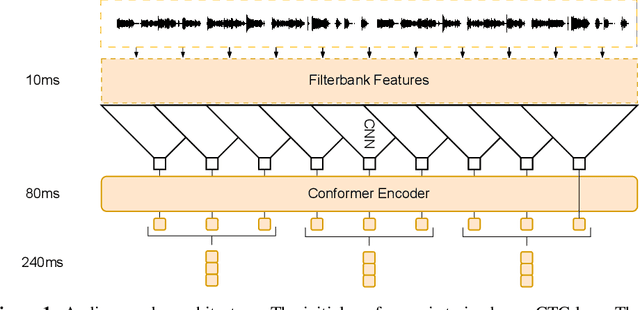
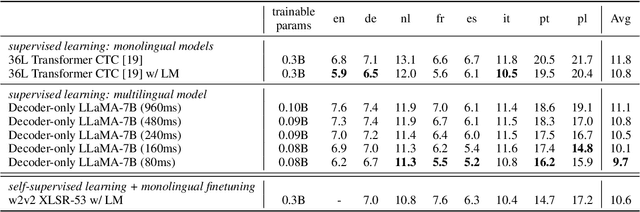
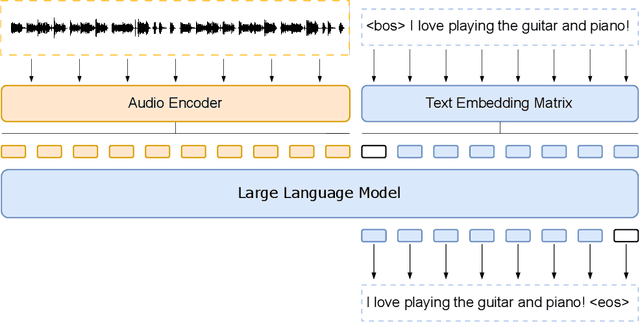

Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a small audio encoder allowing it to perform speech recognition. By directly prepending a sequence of audial embeddings to the text token embeddings, the LLM can be converted to an automatic speech recognition (ASR) system, and be used in the exact same manner as its textual counterpart. Experiments on Multilingual LibriSpeech (MLS) show that incorporating a conformer encoder into the open sourced LLaMA-7B allows it to outperform monolingual baselines by 18% and perform multilingual speech recognition despite LLaMA being trained overwhelmingly on English text. Furthermore, we perform ablation studies to investigate whether the LLM can be completely frozen during training to maintain its original capabilities, scaling up the audio encoder, and increasing the audio encoder striding to generate fewer embeddings. The results from these studies show that multilingual ASR is possible even when the LLM is frozen or when strides of almost 1 second are used in the audio encoder opening up the possibility for LLMs to operate on long-form audio.
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.