 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Speech Naturalness Predictor
Mar 02, 2026Evaluation of conversational naturalness is essential for developing human-like speech agents. However, existing speech naturalness predictors are often designed to assess utterances from a single speaker, failing to capture conversation-level naturalness qualities. In this paper, we present a framework for an automatic naturalness predictor for two-speaker, multi-turn conversations. We first show that existing naturalness estimators have low, or sometimes even negative, correlations with conversational naturalness, based on conversational recordings annotated with human ratings. We then propose a dual-channel naturalness estimator, in which we investigate multiple pre-trained encoders with data augmentation. Our proposed model achieves substantially higher correlation with human judgments compared to existing naturalness predictors for both in-domain and out-of-domain conditions.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Non-Monotonic Attention-based Read/Write Policy Learning for Simultaneous Translation
Mar 28, 2025Simultaneous or streaming machine translation generates translation while reading the input stream. These systems face a quality/latency trade-off, aiming to achieve high translation quality similar to non-streaming models with minimal latency. We propose an approach that efficiently manages this trade-off. By enhancing a pretrained non-streaming model, which was trained with a seq2seq mechanism and represents the upper bound in quality, we convert it into a streaming model by utilizing the alignment between source and target tokens. This alignment is used to learn a read/write decision boundary for reliable translation generation with minimal input. During training, the model learns the decision boundary through a read/write policy module, employing supervised learning on the alignment points (pseudo labels). The read/write policy module, a small binary classification unit, can control the quality/latency trade-off during inference. Experimental results show that our model outperforms several strong baselines and narrows the gap with the non-streaming baseline model.
Transcribing and Translating, Fast and Slow: Joint Speech Translation and Recognition
Dec 19, 2024We propose the joint speech translation and recognition (JSTAR) model that leverages the fast-slow cascaded encoder architecture for simultaneous end-to-end automatic speech recognition (ASR) and speech translation (ST). The model is transducer-based and uses a multi-objective training strategy that optimizes both ASR and ST objectives simultaneously. This allows JSTAR to produce high-quality streaming ASR and ST results. We apply JSTAR in a bilingual conversational speech setting with smart-glasses, where the model is also trained to distinguish speech from different directions corresponding to the wearer and a conversational partner. Different model pre-training strategies are studied to further improve results, including training of a transducer-based streaming machine translation (MT) model for the first time and applying it for parameter initialization of JSTAR. We demonstrate superior performances of JSTAR compared to a strong cascaded ST model in both BLEU scores and latency.
Multilingual End to End Entity Linking
Jun 15, 2023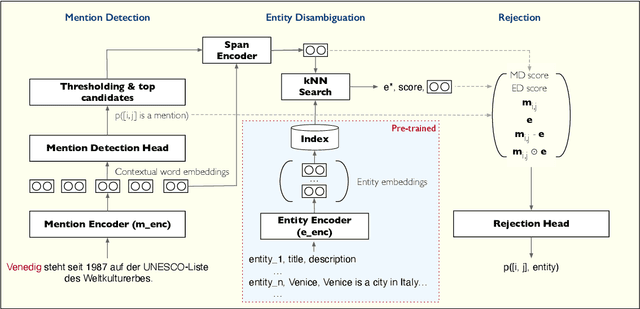
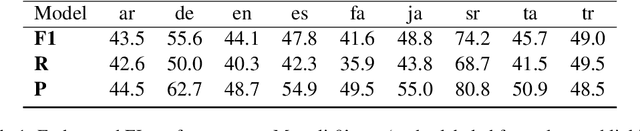

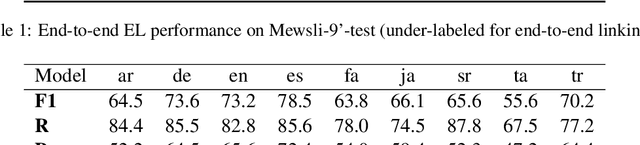
Entity Linking is one of the most common Natural Language Processing tasks in practical applications, but so far efficient end-to-end solutions with multilingual coverage have been lacking, leading to complex model stacks. To fill this gap, we release and open source BELA, the first fully end-to-end multilingual entity linking model that efficiently detects and links entities in texts in any of 97 languages. We provide here a detailed description of the model and report BELA's performance on four entity linking datasets covering high- and low-resource languages.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023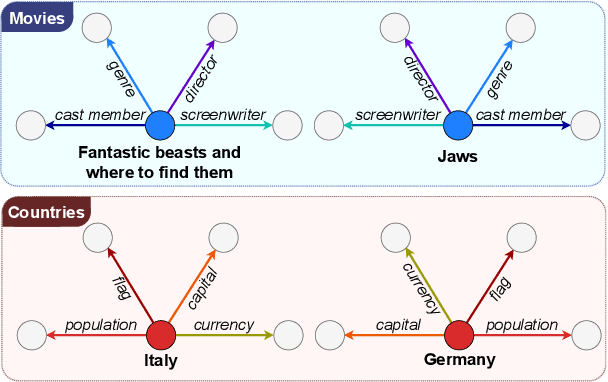
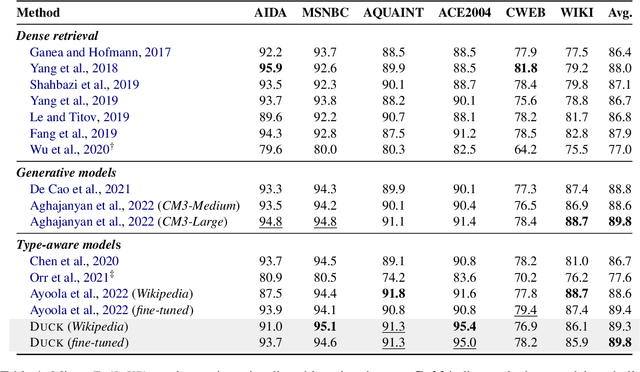
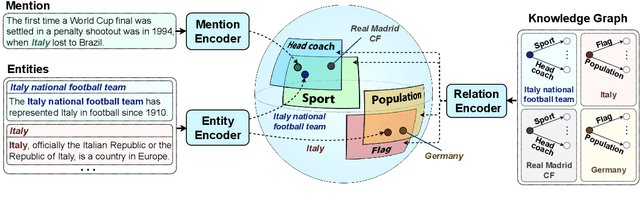
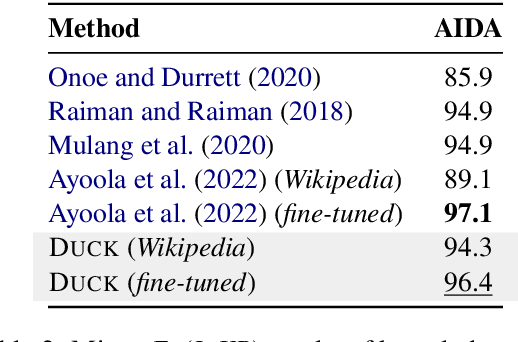
Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.