 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Multilingual End to End Entity Linking
Jun 15, 2023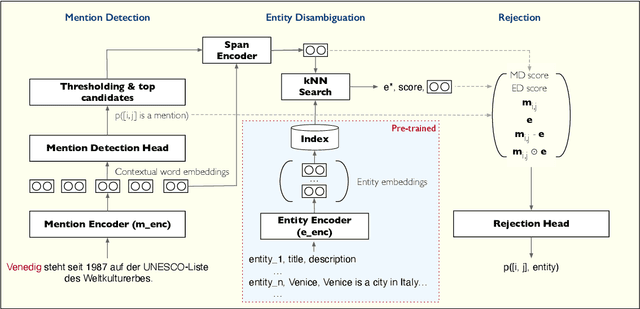
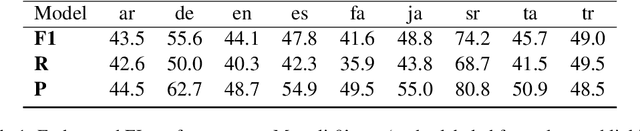

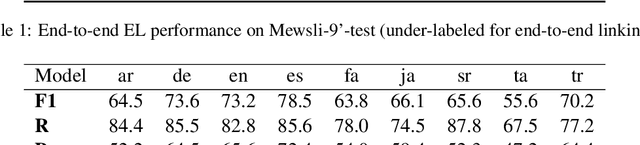
Entity Linking is one of the most common Natural Language Processing tasks in practical applications, but so far efficient end-to-end solutions with multilingual coverage have been lacking, leading to complex model stacks. To fill this gap, we release and open source BELA, the first fully end-to-end multilingual entity linking model that efficiently detects and links entities in texts in any of 97 languages. We provide here a detailed description of the model and report BELA's performance on four entity linking datasets covering high- and low-resource languages.
Polar Ducks and Where to Find Them: Enhancing Entity Linking with Duck Typing and Polar Box Embeddings
May 19, 2023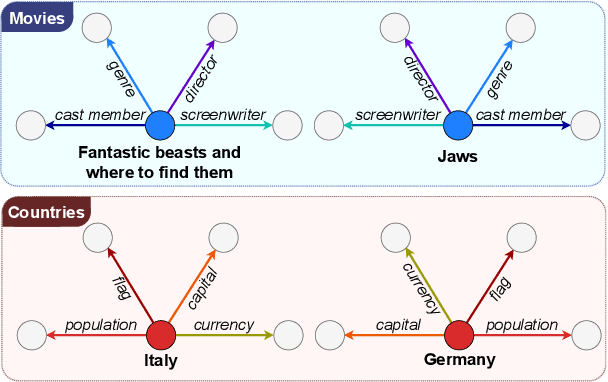
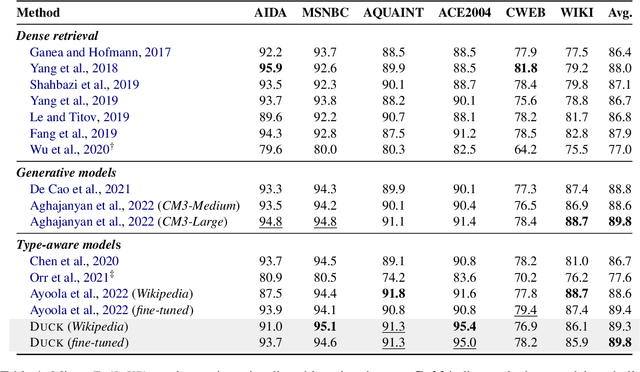
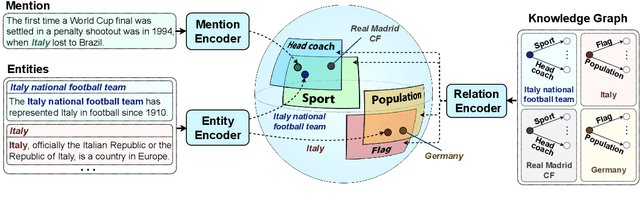
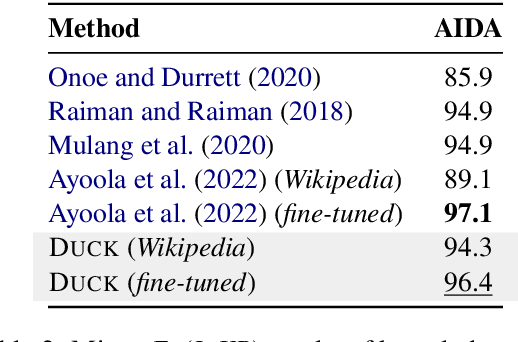
Entity linking methods based on dense retrieval are an efficient and widely used solution in large-scale applications, but they fall short of the performance of generative models, as they are sensitive to the structure of the embedding space. In order to address this issue, this paper introduces DUCK, an approach to infusing structural information in the space of entity representations, using prior knowledge of entity types. Inspired by duck typing in programming languages, we propose to define the type of an entity based on the relations that it has with other entities in a knowledge graph. Then, porting the concept of box embeddings to spherical polar coordinates, we propose to represent relations as boxes on the hypersphere. We optimize the model to cluster entities of similar type by placing them inside the boxes corresponding to their relations. Our experiments show that our method sets new state-of-the-art results on standard entity-disambiguation benchmarks, it improves the performance of the model by up to 7.9 F1 points, outperforms other type-aware approaches, and matches the results of generative models with 18 times more parameters.
EDIN: An End-to-end Benchmark and Pipeline for Unknown Entity Discovery and Indexing
May 25, 2022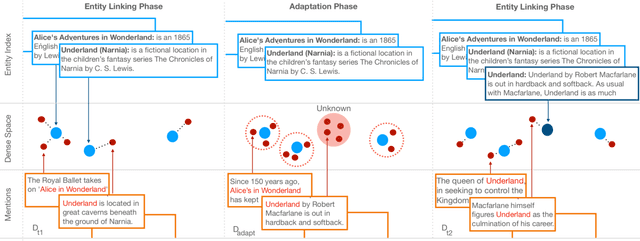



Existing work on Entity Linking mostly assumes that the reference knowledge base is complete, and therefore all mentions can be linked. In practice this is hardly ever the case, as knowledge bases are incomplete and because novel concepts arise constantly. This paper created the Unknown Entity Discovery and Indexing (EDIN) benchmark where unknown entities, that is entities without a description in the knowledge base and labeled mentions, have to be integrated into an existing entity linking system. By contrasting EDIN with zero-shot entity linking, we provide insight on the additional challenges it poses. Building on dense-retrieval based entity linking, we introduce the end-to-end EDIN pipeline that detects, clusters, and indexes mentions of unknown entities in context. Experiments show that indexing a single embedding per entity unifying the information of multiple mentions works better than indexing mentions independently.
Multilingual Autoregressive Entity Linking
Mar 23, 2021



We present mGENRE, a sequence-to-sequence system for the Multilingual Entity Linking (MEL) problem -- the task of resolving language-specific mentions to a multilingual Knowledge Base (KB). For a mention in a given language, mGENRE predicts the name of the target entity left-to-right, token-by-token in an autoregressive fashion. The autoregressive formulation allows us to effectively cross-encode mention string and entity names to capture more interactions than the standard dot product between mention and entity vectors. It also enables fast search within a large KB even for mentions that do not appear in mention tables and with no need for large-scale vector indices. While prior MEL works use a single representation for each entity, we match against entity names of as many languages as possible, which allows exploiting language connections between source input and target name. Moreover, in a zero-shot setting on languages with no training data at all, mGENRE treats the target language as a latent variable that is marginalized at prediction time. This leads to over 50% improvements in average accuracy. We show the efficacy of our approach through extensive evaluation including experiments on three popular MEL benchmarks where mGENRE establishes new state-of-the-art results. Code and pre-trained models at https://github.com/facebookresearch/GENRE.