 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual End to End Entity Linking
Jun 15, 2023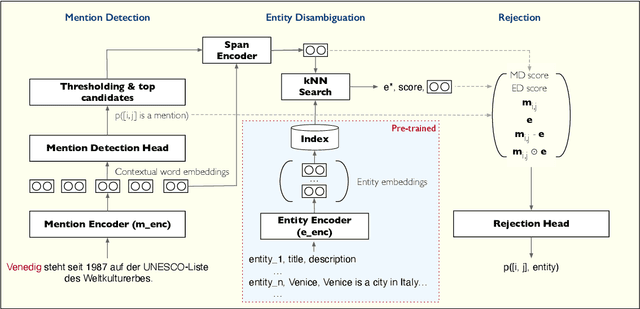
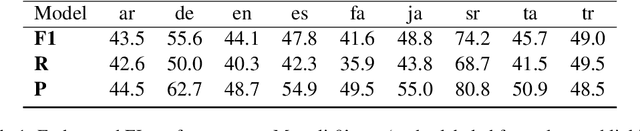

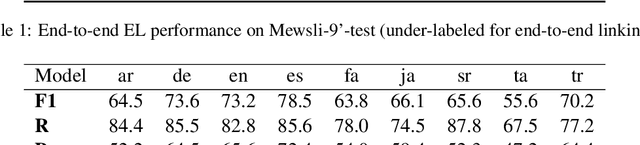
Entity Linking is one of the most common Natural Language Processing tasks in practical applications, but so far efficient end-to-end solutions with multilingual coverage have been lacking, leading to complex model stacks. To fill this gap, we release and open source BELA, the first fully end-to-end multilingual entity linking model that efficiently detects and links entities in texts in any of 97 languages. We provide here a detailed description of the model and report BELA's performance on four entity linking datasets covering high- and low-resource languages.
Entity Tagging: Extracting Entities in Text Without Mention Supervision
Sep 13, 2022

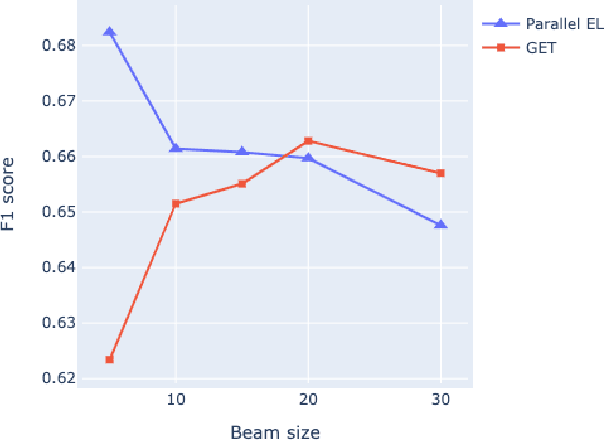
Detection and disambiguation of all entities in text is a crucial task for a wide range of applications. The typical formulation of the problem involves two stages: detect mention boundaries and link all mentions to a knowledge base. For a long time, mention detection has been considered as a necessary step for extracting all entities in a piece of text, even if the information about mention spans is ignored by some downstream applications that merely focus on the set of extracted entities. In this paper we show that, in such cases, detection of mention boundaries does not bring any considerable performance gain in extracting entities, and therefore can be skipped. To conduct our analysis, we propose an "Entity Tagging" formulation of the problem, where models are evaluated purely on the set of extracted entities without considering mentions. We compare a state-of-the-art mention-aware entity linking solution against GET, a mention-agnostic sequence-to-sequence model that simply outputs a list of disambiguated entities given an input context. We find that these models achieve comparable performance when trained both on a fully and partially annotated dataset across multiple benchmarks, demonstrating that GET can extract disambiguated entities with strong performance without explicit mention boundaries supervision.
Open Vocabulary Extreme Classification Using Generative Models
May 12, 2022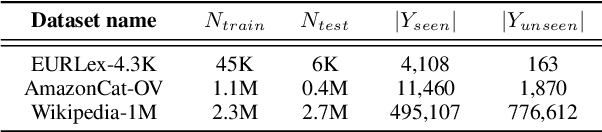
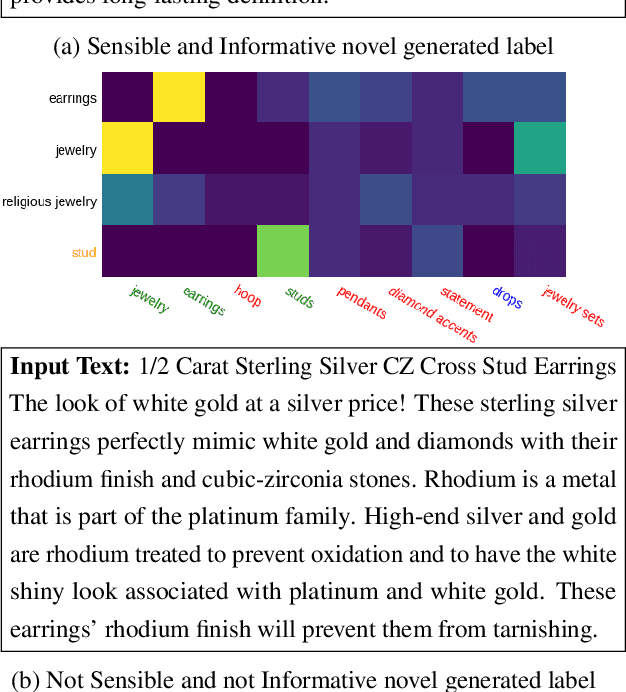
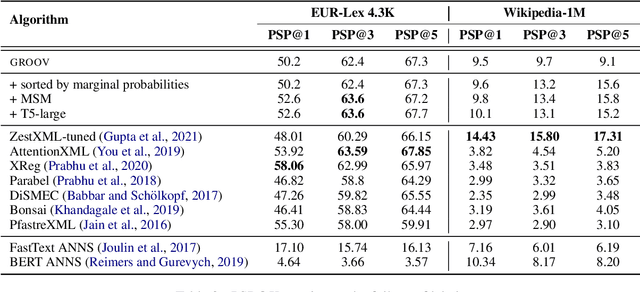

The extreme multi-label classification (XMC) task aims at tagging content with a subset of labels from an extremely large label set. The label vocabulary is typically defined in advance by domain experts and assumed to capture all necessary tags. However in real world scenarios this label set, although large, is often incomplete and experts frequently need to refine it. To develop systems that simplify this process, we introduce the task of open vocabulary XMC (OXMC): given a piece of content, predict a set of labels, some of which may be outside of the known tag set. Hence, in addition to not having training data for some labels - as is the case in zero-shot classification - models need to invent some labels on-the-fly. We propose GROOV, a fine-tuned seq2seq model for OXMC that generates the set of labels as a flat sequence and is trained using a novel loss independent of predicted label order. We show the efficacy of the approach, experimenting with popular XMC datasets for which GROOV is able to predict meaningful labels outside the given vocabulary while performing on par with state-of-the-art solutions for known labels.
Multilingual Autoregressive Entity Linking
Mar 23, 2021



We present mGENRE, a sequence-to-sequence system for the Multilingual Entity Linking (MEL) problem -- the task of resolving language-specific mentions to a multilingual Knowledge Base (KB). For a mention in a given language, mGENRE predicts the name of the target entity left-to-right, token-by-token in an autoregressive fashion. The autoregressive formulation allows us to effectively cross-encode mention string and entity names to capture more interactions than the standard dot product between mention and entity vectors. It also enables fast search within a large KB even for mentions that do not appear in mention tables and with no need for large-scale vector indices. While prior MEL works use a single representation for each entity, we match against entity names of as many languages as possible, which allows exploiting language connections between source input and target name. Moreover, in a zero-shot setting on languages with no training data at all, mGENRE treats the target language as a latent variable that is marginalized at prediction time. This leads to over 50% improvements in average accuracy. We show the efficacy of our approach through extensive evaluation including experiments on three popular MEL benchmarks where mGENRE establishes new state-of-the-art results. Code and pre-trained models at https://github.com/facebookresearch/GENRE.
STANCY: Stance Classification Based on Consistency Cues
Oct 14, 2019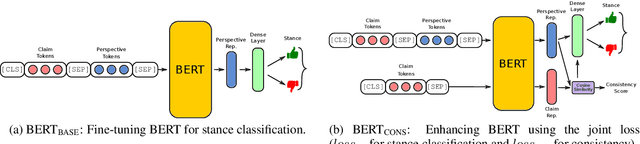
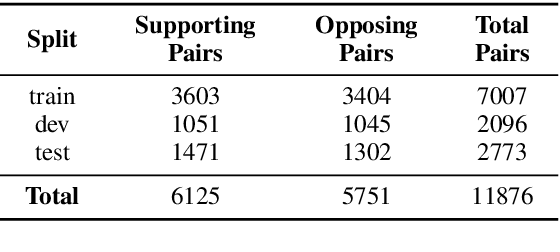
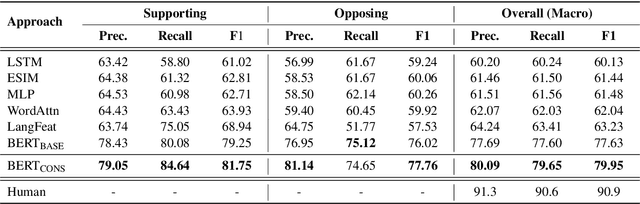
Controversial claims are abundant in online media and discussion forums. A better understanding of such claims requires analyzing them from different perspectives. Stance classification is a necessary step for inferring these perspectives in terms of supporting or opposing the claim. In this work, we present a neural network model for stance classification leveraging BERT representations and augmenting them with a novel consistency constraint. Experiments on the Perspectrum dataset, consisting of claims and users' perspectives from various debate websites, demonstrate the effectiveness of our approach over state-of-the-art baselines.
DeClarE: Debunking Fake News and False Claims using Evidence-Aware Deep Learning
Sep 17, 2018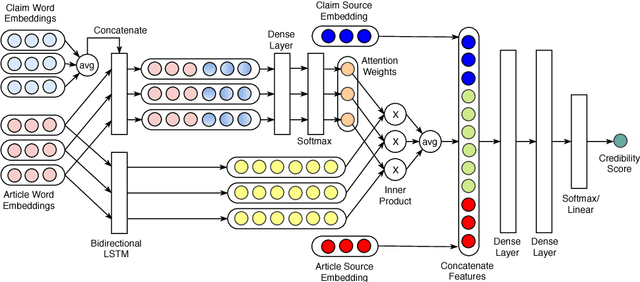
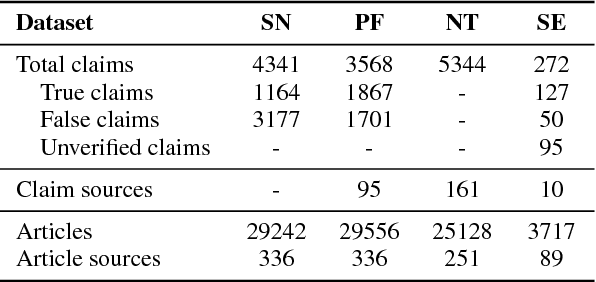


Misinformation such as fake news is one of the big challenges of our society. Research on automated fact-checking has proposed methods based on supervised learning, but these approaches do not consider external evidence apart from labeled training instances. Recent approaches counter this deficit by considering external sources related to a claim. However, these methods require substantial feature modeling and rich lexicons. This paper overcomes these limitations of prior work with an end-to-end model for evidence-aware credibility assessment of arbitrary textual claims, without any human intervention. It presents a neural network model that judiciously aggregates signals from external evidence articles, the language of these articles and the trustworthiness of their sources. It also derives informative features for generating user-comprehensible explanations that makes the neural network predictions transparent to the end-user. Experiments with four datasets and ablation studies show the strength of our method.
Exploring Latent Semantic Factors to Find Useful Product Reviews
May 06, 2017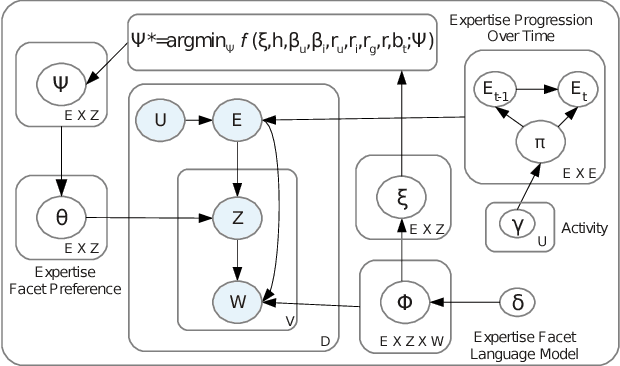
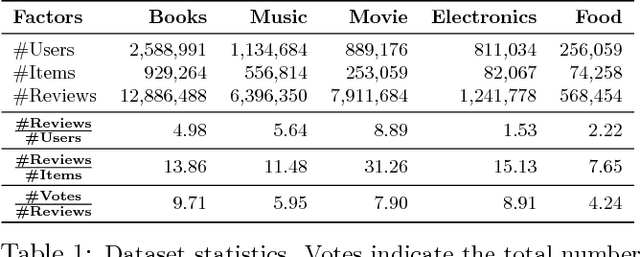

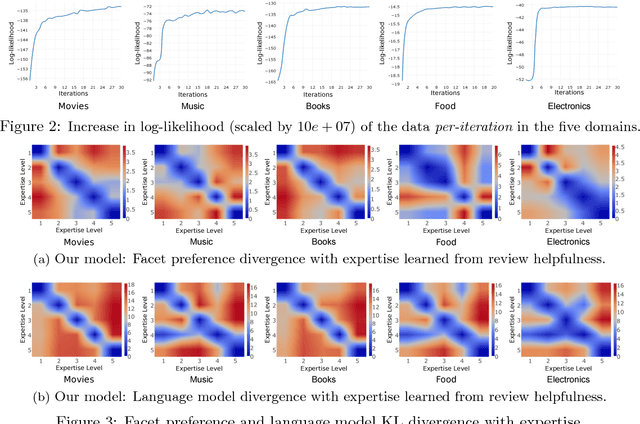
Online reviews provided by consumers are a valuable asset for e-Commerce platforms, influencing potential consumers in making purchasing decisions. However, these reviews are of varying quality, with the useful ones buried deep within a heap of non-informative reviews. In this work, we attempt to automatically identify review quality in terms of its helpfulness to the end consumers. In contrast to previous works in this domain exploiting a variety of syntactic and community-level features, we delve deep into the semantics of reviews as to what makes them useful, providing interpretable explanation for the same. We identify a set of consistency and semantic factors, all from the text, ratings, and timestamps of user-generated reviews, making our approach generalizable across all communities and domains. We explore review semantics in terms of several latent factors like the expertise of its author, his judgment about the fine-grained facets of the underlying product, and his writing style. These are cast into a Hidden Markov Model -- Latent Dirichlet Allocation (HMM-LDA) based model to jointly infer: (i) reviewer expertise, (ii) item facets, and (iii) review helpfulness. Large-scale experiments on five real-world datasets from Amazon show significant improvement over state-of-the-art baselines in predicting and ranking useful reviews.