 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD4: Improving LLM Pretraining via Document De-Duplication and Diversification
Aug 23, 2023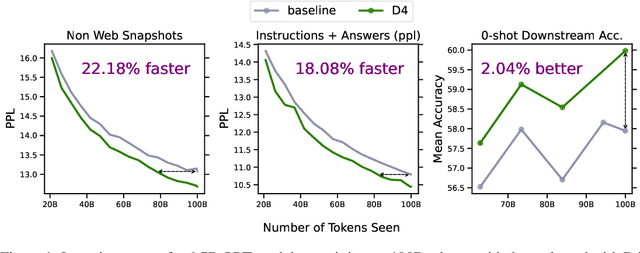
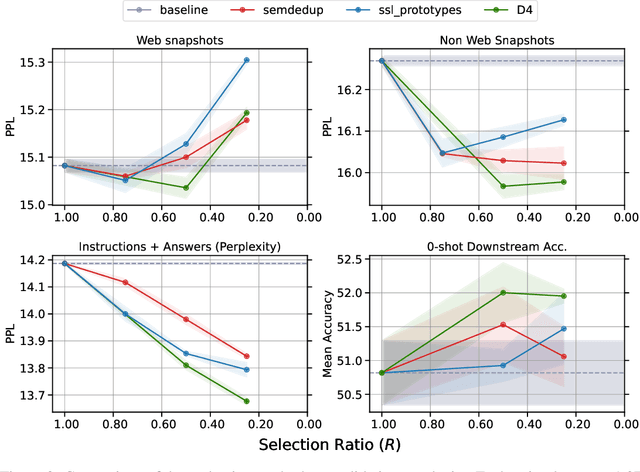
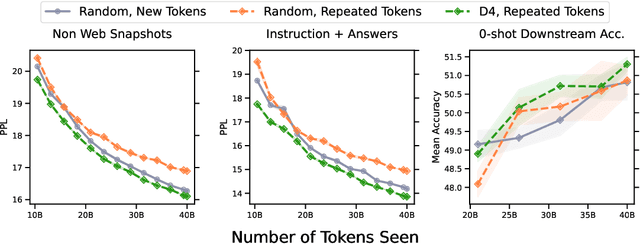
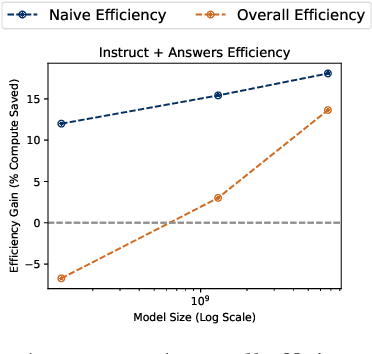
Over recent years, an increasing amount of compute and data has been poured into training large language models (LLMs), usually by doing one-pass learning on as many tokens as possible randomly selected from large-scale web corpora. While training on ever-larger portions of the internet leads to consistent performance improvements, the size of these improvements diminishes with scale, and there has been little work exploring the effect of data selection on pre-training and downstream performance beyond simple de-duplication methods such as MinHash. Here, we show that careful data selection (on top of de-duplicated data) via pre-trained model embeddings can speed up training (20% efficiency gains) and improves average downstream accuracy on 16 NLP tasks (up to 2%) at the 6.7B model scale. Furthermore, we show that repeating data intelligently consistently outperforms baseline training (while repeating random data performs worse than baseline training). Our results indicate that clever data selection can significantly improve LLM pre-training, calls into question the common practice of training for a single epoch on as much data as possible, and demonstrates a path to keep improving our models past the limits of randomly sampling web data.
Understanding In-Context Learning via Supportive Pretraining Data
Jun 26, 2023



In-context learning (ICL) improves language models' performance on a variety of NLP tasks by simply demonstrating a handful of examples at inference time. It is not well understood why ICL ability emerges, as the model has never been specifically trained on such demonstrations. Unlike prior work that explores implicit mechanisms behind ICL, we study ICL via investigating the pretraining data. Specifically, we first adapt an iterative, gradient-based approach to find a small subset of pretraining data that supports ICL. We observe that a continued pretraining on this small subset significantly improves the model's ICL ability, by up to 18%. We then compare the supportive subset constrastively with random subsets of pretraining data and discover: (1) The supportive pretraining data to ICL do not have a higher domain relevance to downstream tasks. (2) The supportive pretraining data have a higher mass of rarely occurring, long-tail tokens. (3) The supportive pretraining data are challenging examples where the information gain from long-range context is below average, indicating learning to incorporate difficult long-range context encourages ICL. Our work takes a first step towards understanding ICL via analyzing instance-level pretraining data. Our insights have a potential to enhance the ICL ability of language models by actively guiding the construction of pretraining data in the future.
Evaluating end-to-end entity linking on domain-specific knowledge bases: Learning about ancient technologies from museum collections
May 23, 2023



To study social, economic, and historical questions, researchers in the social sciences and humanities have started to use increasingly large unstructured textual datasets. While recent advances in NLP provide many tools to efficiently process such data, most existing approaches rely on generic solutions whose performance and suitability for domain-specific tasks is not well understood. This work presents an attempt to bridge this domain gap by exploring the use of modern Entity Linking approaches for the enrichment of museum collection data. We collect a dataset comprising of more than 1700 texts annotated with 7,510 mention-entity pairs, evaluate some off-the-shelf solutions in detail using this dataset and finally fine-tune a recent end-to-end EL model on this data. We show that our fine-tuned model significantly outperforms other approaches currently available in this domain and present a proof-of-concept use case of this model. We release our dataset and our best model.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
Text Characterization Toolkit
Oct 04, 2022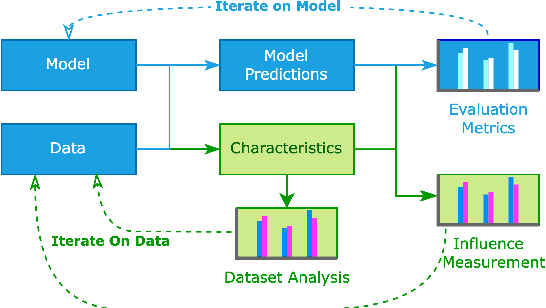
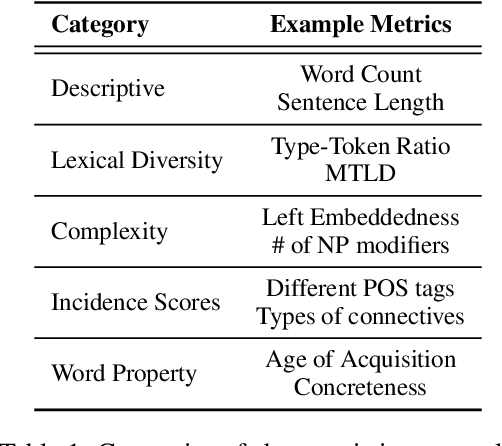
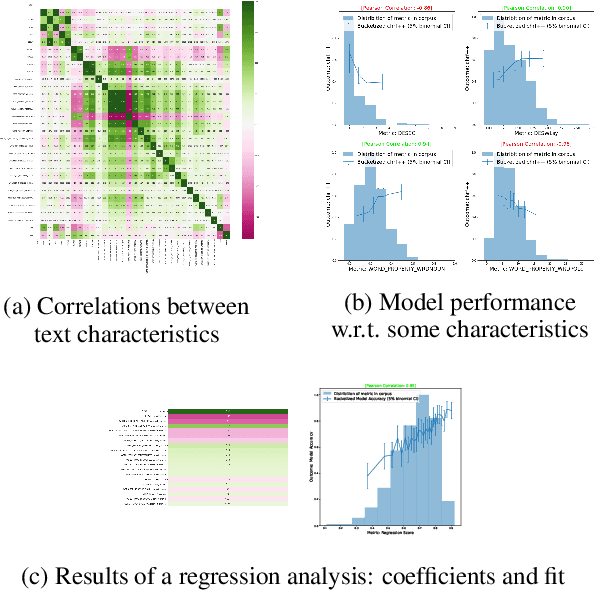
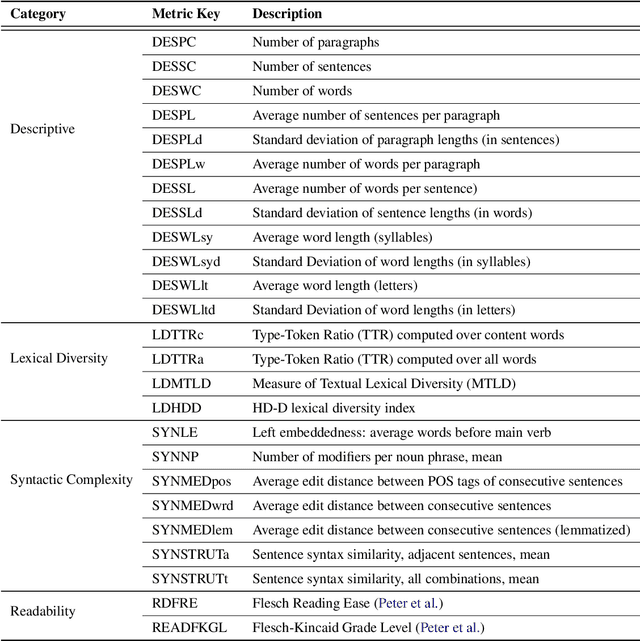
In NLP, models are usually evaluated by reporting single-number performance scores on a number of readily available benchmarks, without much deeper analysis. Here, we argue that - especially given the well-known fact that benchmarks often contain biases, artefacts, and spurious correlations - deeper results analysis should become the de-facto standard when presenting new models or benchmarks. We present a tool that researchers can use to study properties of the dataset and the influence of those properties on their models' behaviour. Our Text Characterization Toolkit includes both an easy-to-use annotation tool, as well as off-the-shelf scripts that can be used for specific analyses. We also present use-cases from three different domains: we use the tool to predict what are difficult examples for given well-known trained models and identify (potentially harmful) biases and heuristics that are present in a dataset.
Open Vocabulary Extreme Classification Using Generative Models
May 12, 2022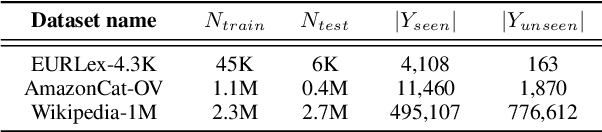
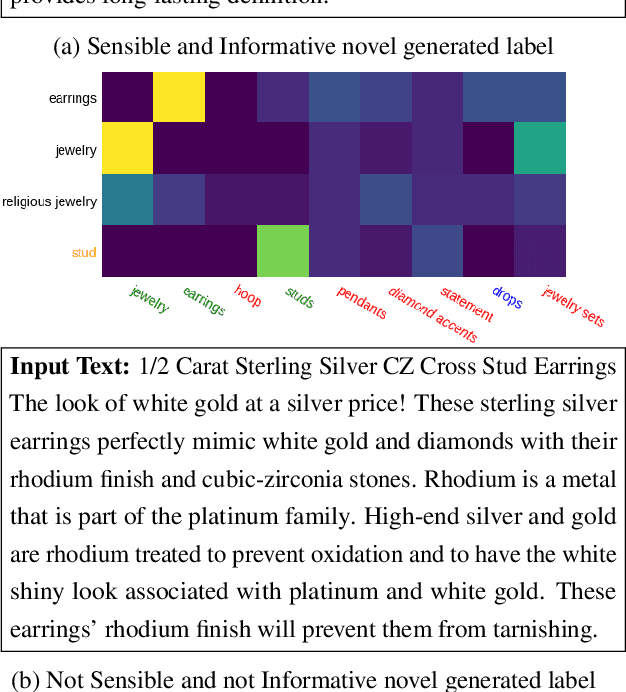
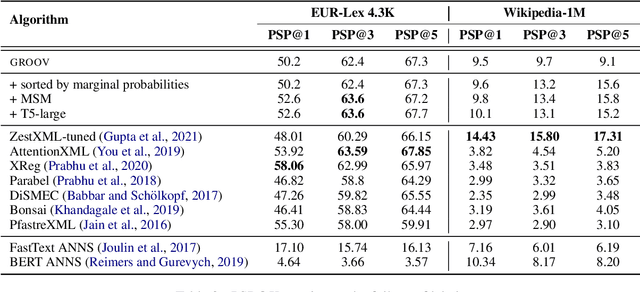

The extreme multi-label classification (XMC) task aims at tagging content with a subset of labels from an extremely large label set. The label vocabulary is typically defined in advance by domain experts and assumed to capture all necessary tags. However in real world scenarios this label set, although large, is often incomplete and experts frequently need to refine it. To develop systems that simplify this process, we introduce the task of open vocabulary XMC (OXMC): given a piece of content, predict a set of labels, some of which may be outside of the known tag set. Hence, in addition to not having training data for some labels - as is the case in zero-shot classification - models need to invent some labels on-the-fly. We propose GROOV, a fine-tuned seq2seq model for OXMC that generates the set of labels as a flat sequence and is trained using a novel loss independent of predicted label order. We show the efficacy of the approach, experimenting with popular XMC datasets for which GROOV is able to predict meaningful labels outside the given vocabulary while performing on par with state-of-the-art solutions for known labels.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022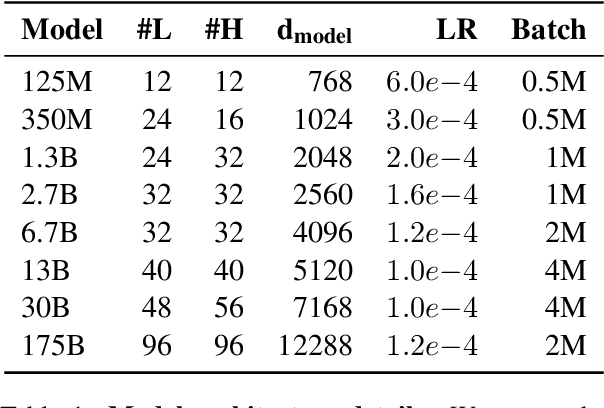
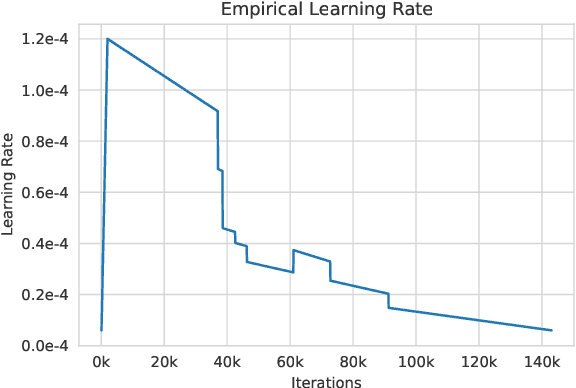
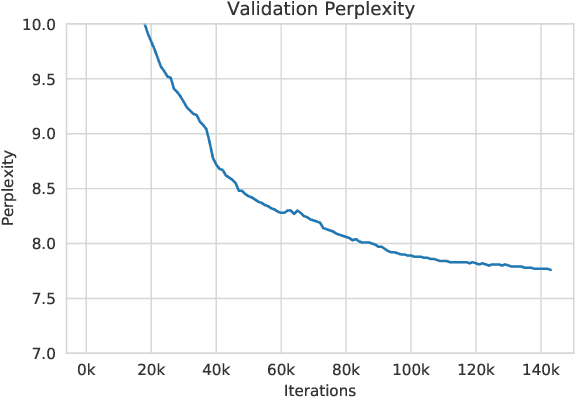
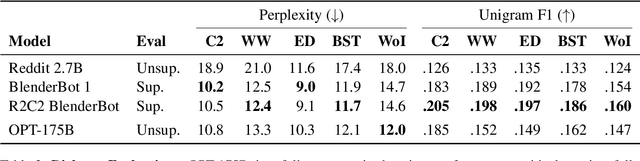
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
Few-shot Learning with Multilingual Language Models
Dec 20, 2021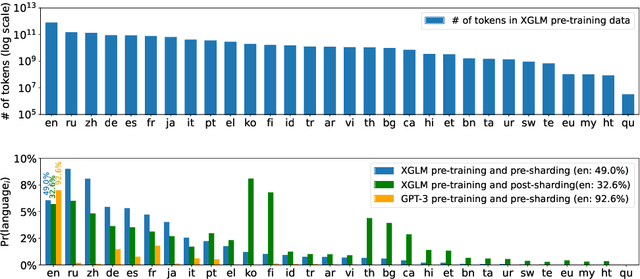
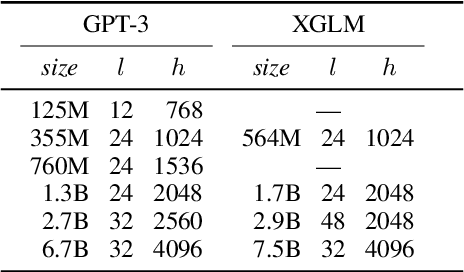
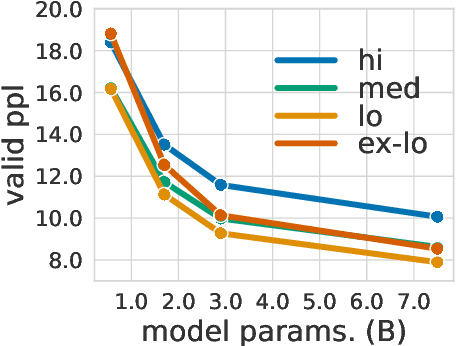

Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language tasks without fine-tuning. While these models are known to be able to jointly represent many different languages, their training data is dominated by English, potentially limiting their cross-lingual generalization. In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages, and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings) and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark, our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails, showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.