 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Tool Use with Chain-of-Abstraction Reasoning
Jan 30, 2024



To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools help LLMs access this external knowledge, but there remains challenges for fine-tuning LLM agents (e.g., Toolformer) to invoke tools in multi-step reasoning problems, where inter-connected tool calls require holistic and efficient tool usage planning. In this work, we propose a new method for LLMs to better leverage tools in multi-step reasoning. Our method, Chain-of-Abstraction (CoA), trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement. LLM agents trained with our method also show more efficient tool use, with inference speed being on average ~1.4x faster than baseline tool-augmented LLMs.
PathFinder: Guided Search over Multi-Step Reasoning Paths
Dec 12, 2023



With recent advancements in large language models, methods like chain-of-thought prompting to elicit reasoning chains have been shown to improve results on reasoning tasks. However, tasks that require multiple steps of reasoning still pose significant challenges to state-of-the-art models. Drawing inspiration from the beam search algorithm, we propose PathFinder, a tree-search-based reasoning path generation approach. It enhances diverse branching and multi-hop reasoning through the integration of dynamic decoding, enabled by varying sampling methods and parameters. Using constrained reasoning, PathFinder integrates novel quality constraints, pruning, and exploration methods to enhance the efficiency and the quality of generation. Moreover, it includes scoring and ranking features to improve candidate selection. Our approach outperforms competitive baselines on three complex arithmetic and commonsense reasoning tasks by 6% on average. Our model generalizes well to longer, unseen reasoning chains, reflecting similar complexities to beam search with large branching factors.
Crystal: Introspective Reasoners Reinforced with Self-Feedback
Oct 18, 2023


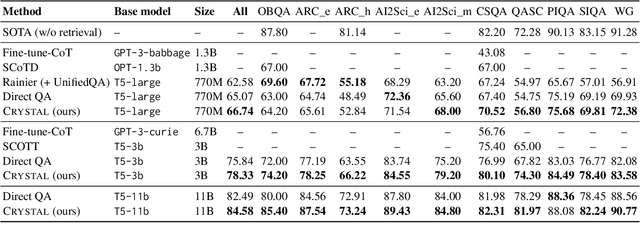
Extensive work has shown that the performance and interpretability of commonsense reasoning can be improved via knowledge-augmented reasoning methods, where the knowledge that underpins the reasoning process is explicitly verbalized and utilized. However, existing implementations, including "chain-of-thought" and its variants, fall short in capturing the introspective nature of knowledge required in commonsense reasoning, and in accounting for the mutual adaptation between the generation and utilization of knowledge. We propose a novel method to develop an introspective commonsense reasoner, Crystal. To tackle commonsense problems, it first introspects for knowledge statements related to the given question, and subsequently makes an informed prediction that is grounded in the previously introspected knowledge. The knowledge introspection and knowledge-grounded reasoning modes of the model are tuned via reinforcement learning to mutually adapt, where the reward derives from the feedback given by the model itself. Experiments show that Crystal significantly outperforms both the standard supervised finetuning and chain-of-thought distilled methods, and enhances the transparency of the commonsense reasoning process. Our work ultimately validates the feasibility and potential of reinforcing a neural model with self-feedback.
Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading
Oct 08, 2023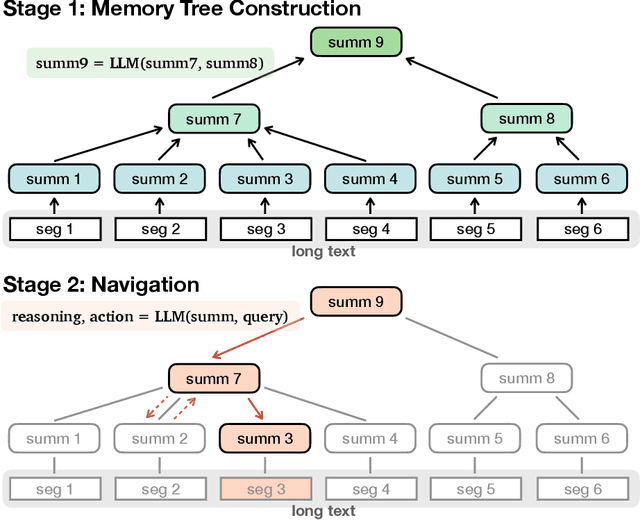

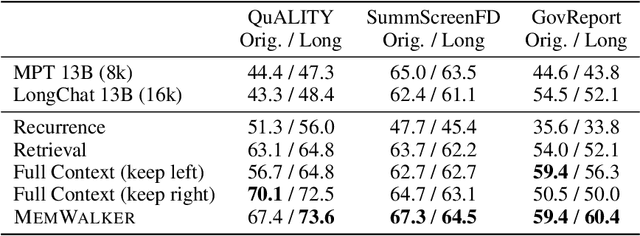
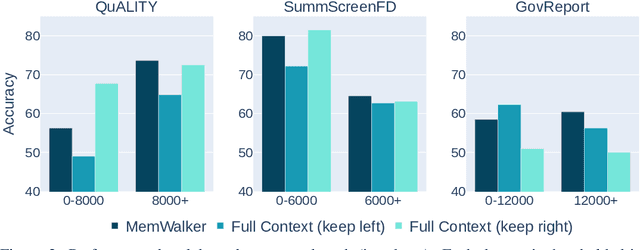
Large language models (LLMs) have advanced in large strides due to the effectiveness of the self-attention mechanism that processes and compares all tokens at once. However, this mechanism comes with a fundamental issue -- the predetermined context window is bound to be limited. Despite attempts to extend the context window through methods like extrapolating the positional embedding, using recurrence, or selectively retrieving essential parts of the long sequence, long-text understanding continues to be a challenge. We propose an alternative approach which instead treats the LLM as an interactive agent, allowing it to decide how to read the text via iterative prompting. We introduce MemWalker, a method that first processes the long context into a tree of summary nodes. Upon receiving a query, the model navigates this tree in search of relevant information, and responds once it gathers sufficient information. On long-text question answering tasks our method outperforms baseline approaches that use long context windows, recurrence, and retrieval. We show that, beyond effective reading, MemWalker enhances explainability by highlighting the reasoning steps as it interactively reads the text; pinpointing the relevant text segments related to the query.
Making PPO even better: Value-Guided Monte-Carlo Tree Search decoding
Sep 26, 2023Inference-time search algorithms such as Monte-Carlo Tree Search (MCTS) may seem unnecessary when generating natural language text based on state-of-the-art reinforcement learning such as Proximal Policy Optimization (PPO). In this paper, we demonstrate that it is possible to get extra mileage out of PPO by integrating MCTS on top. The key idea is not to throw out the value network, a byproduct of PPO training for evaluating partial output sequences, when decoding text out of the policy network. More concretely, we present a novel value-guided decoding algorithm called PPO-MCTS, which can integrate the value network from PPO to work closely with the policy network during inference-time generation. Compared to prior approaches based on MCTS for controlled text generation, the key strength of our approach is to reduce the fundamental mismatch of the scoring mechanisms of the partial outputs between training and test. Evaluation on four text generation tasks demonstrate that PPO-MCTS greatly improves the preferability of generated text compared to the standard practice of using only the PPO policy. Our results demonstrate the promise of search algorithms even on top of the aligned language models from PPO, and the under-explored benefit of the value network.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023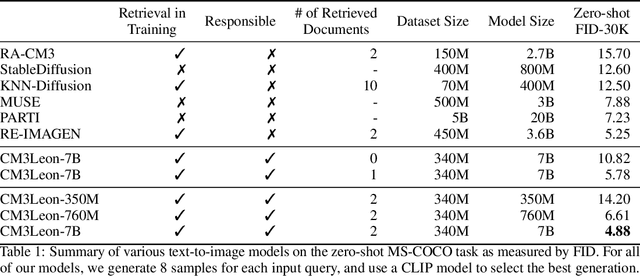

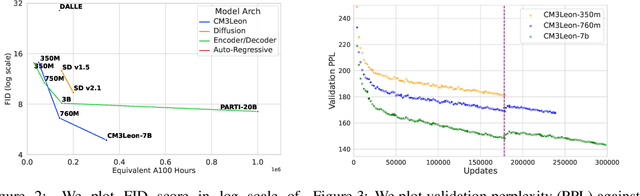

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
Shepherd: A Critic for Language Model Generation
Aug 08, 2023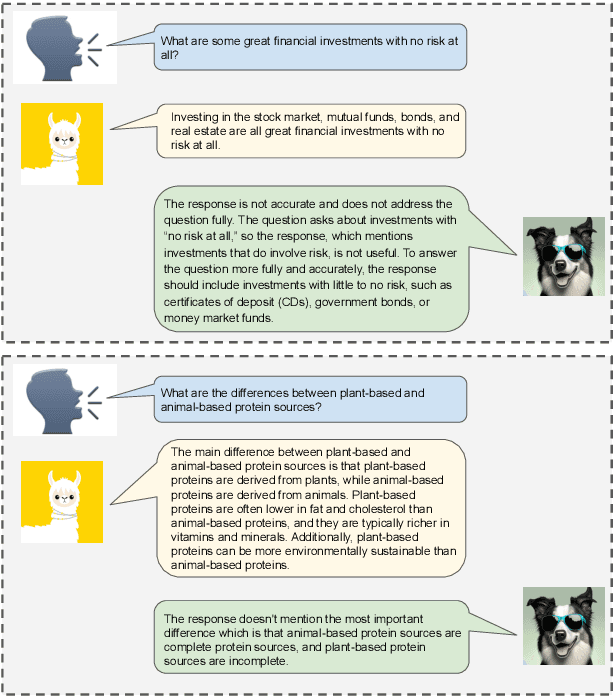

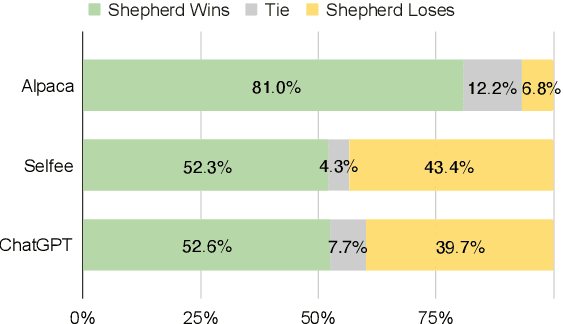

As large language models improve, there is increasing interest in techniques that leverage these models' capabilities to refine their own outputs. In this work, we introduce Shepherd, a language model specifically tuned to critique responses and suggest refinements, extending beyond the capabilities of an untuned model to identify diverse errors and provide suggestions to remedy them. At the core of our approach is a high quality feedback dataset, which we curate from community feedback and human annotations. Even though Shepherd is small (7B parameters), its critiques are either equivalent or preferred to those from established models including ChatGPT. Using GPT-4 for evaluation, Shepherd reaches an average win-rate of 53-87% compared to competitive alternatives. In human evaluation, Shepherd strictly outperforms other models and on average closely ties with ChatGPT.
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
Training Trajectories of Language Models Across Scales
Dec 19, 2022



Scaling up language models has led to unprecedented performance gains, but little is understood about how the training dynamics change as models get larger. How do language models of different sizes learn during pre-training? Why do larger language models demonstrate more desirable behaviors? In this paper, we analyze the intermediate training checkpoints of differently sized OPT models (Zhang et al.,2022)--from 125M to 175B parameters--on next-token prediction, sequence-level generation, and downstream tasks. We find that 1) at a given perplexity and independent of model sizes, a similar subset of training tokens see the most significant reduction in loss, with the rest stagnating or showing double-descent behavior; 2) early in training, all models learn to reduce the perplexity of grammatical sequences that contain hallucinations, with small models halting at this suboptimal distribution and larger ones eventually learning to assign these sequences lower probabilities; 3) perplexity is a strong predictor of in-context learning performance on 74 multiple-choice tasks from BIG-Bench, and this holds independent of the model size. Together, these results show that perplexity is more predictive of model behaviors than model size or training computation.
MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation
Dec 16, 2022



Prompting large language models has enabled significant recent progress in multi-step reasoning over text. However, when applied to text generation from semi-structured data (e.g., graphs or tables), these methods typically suffer from low semantic coverage, hallucination, and logical inconsistency. We propose MURMUR, a neuro-symbolic modular approach to text generation from semi-structured data with multi-step reasoning. MURMUR is a best-first search method that generates reasoning paths using: (1) neural and symbolic modules with specific linguistic and logical skills, (2) a grammar whose production rules define valid compositions of modules, and (3) value functions that assess the quality of each reasoning step. We conduct experiments on two diverse data-to-text generation tasks like WebNLG and LogicNLG. These tasks differ in their data representations (graphs and tables) and span multiple linguistic and logical skills. MURMUR obtains significant improvements over recent few-shot baselines like direct prompting and chain-of-thought prompting, while also achieving comparable performance to fine-tuned GPT-2 on out-of-domain data. Moreover, human evaluation shows that MURMUR generates highly faithful and correct reasoning paths that lead to 26% more logically consistent summaries on LogicNLG, compared to direct prompting.