 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Role of Relationship Alignment in Large Language Models
Oct 02, 2024
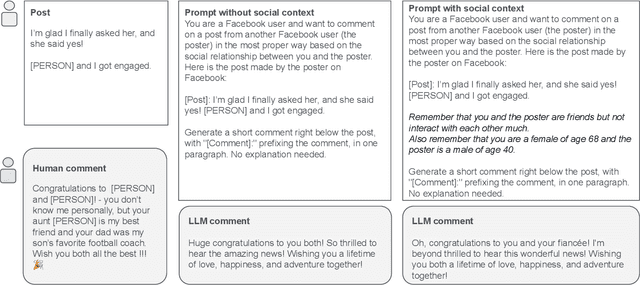
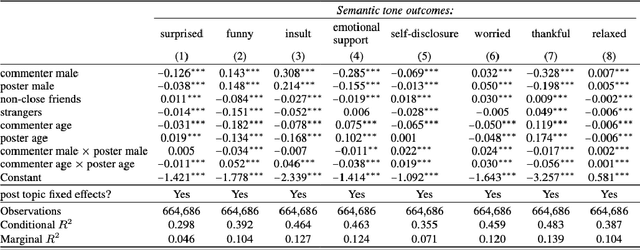

The rapid development and deployment of Generative AI in social settings raise important questions about how to optimally personalize them for users while maintaining accuracy and realism. Based on a Facebook public post-comment dataset, this study evaluates the ability of Llama 3.0 (70B) to predict the semantic tones across different combinations of a commenter's and poster's gender, age, and friendship closeness and to replicate these differences in LLM-generated comments. The study consists of two parts: Part I assesses differences in semantic tones across social relationship categories, and Part II examines the similarity between comments generated by Llama 3.0 (70B) and human comments from Part I given public Facebook posts as input. Part I results show that including social relationship information improves the ability of a model to predict the semantic tone of human comments. However, Part II results show that even without including social context information in the prompt, LLM-generated comments and human comments are equally sensitive to social context, suggesting that LLMs can comprehend semantics from the original post alone. When we include all social relationship information in the prompt, the similarity between human comments and LLM-generated comments decreases. This inconsistency may occur because LLMs did not include social context information as part of their training data. Together these results demonstrate the ability of LLMs to comprehend semantics from the original post and respond similarly to human comments, but also highlights their limitations in generalizing personalized comments through prompting alone.
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
Sep 12, 2024



Large Language Models still struggle in challenging scenarios that leverage structured data, complex reasoning, or tool usage. In this paper, we propose Source2Synth: a new method that can be used for teaching LLMs new skills without relying on costly human annotations. Source2Synth takes as input a custom data source and produces synthetic data points with intermediate reasoning steps grounded in real-world sources. Source2Synth improves the dataset quality by discarding low-quality generations based on their answerability. We demonstrate the generality of this approach by applying it to two challenging domains: we test reasoning abilities in multi-hop question answering (MHQA), and tool usage in tabular question answering (TQA). Our method improves performance by 25.51% for TQA on WikiSQL and 22.57% for MHQA on HotPotQA compared to the fine-tuned baselines.
Self-Taught Evaluators
Aug 05, 2024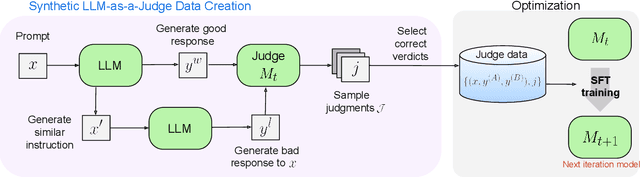
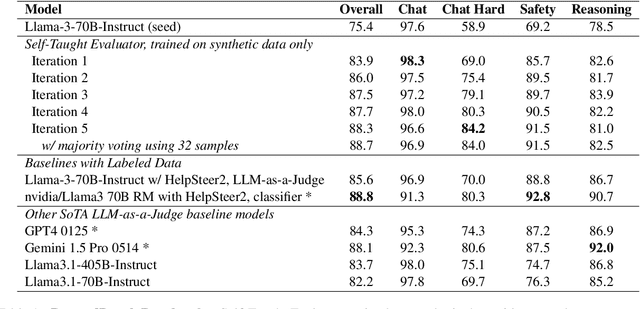

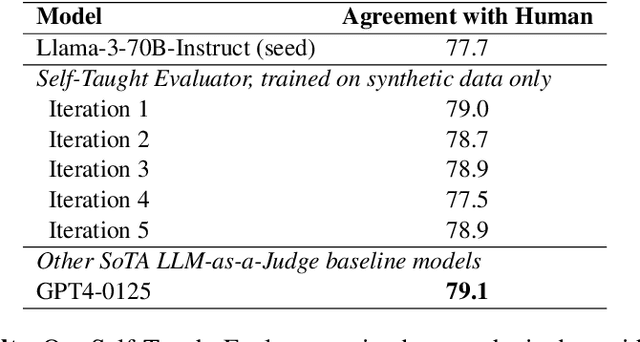
Model-based evaluation is at the heart of successful model development -- as a reward model for training, and as a replacement for human evaluation. To train such evaluators, the standard approach is to collect a large amount of human preference judgments over model responses, which is costly and the data becomes stale as models improve. In this work, we present an approach that aims to im-prove evaluators without human annotations, using synthetic training data only. Starting from unlabeled instructions, our iterative self-improvement scheme generates contrasting model outputs and trains an LLM-as-a-Judge to produce reasoning traces and final judgments, repeating this training at each new iteration using the improved predictions. Without any labeled preference data, our Self-Taught Evaluator can improve a strong LLM (Llama3-70B-Instruct) from 75.4 to 88.3 (88.7 with majority vote) on RewardBench. This outperforms commonly used LLM judges such as GPT-4 and matches the performance of the top-performing reward models trained with labeled examples.
Measuring and Addressing Indexical Bias in Information Retrieval
Jun 06, 2024



Information Retrieval (IR) systems are designed to deliver relevant content, but traditional systems may not optimize rankings for fairness, neutrality, or the balance of ideas. Consequently, IR can often introduce indexical biases, or biases in the positional order of documents. Although indexical bias can demonstrably affect people's opinion, voting patterns, and other behaviors, these issues remain understudied as the field lacks reliable metrics and procedures for automatically measuring indexical bias. Towards this end, we introduce the PAIR framework, which supports automatic bias audits for ranked documents or entire IR systems. After introducing DUO, the first general-purpose automatic bias metric, we run an extensive evaluation of 8 IR systems on a new corpus of 32k synthetic and 4.7k natural documents, with 4k queries spanning 1.4k controversial issue topics. A human behavioral study validates our approach, showing that our bias metric can help predict when and how indexical bias will shift a reader's opinion.
FairPair: A Robust Evaluation of Biases in Language Models through Paired Perturbations
Apr 09, 2024


The accurate evaluation of differential treatment in language models to specific groups is critical to ensuring a positive and safe user experience. An ideal evaluation should have the properties of being robust, extendable to new groups or attributes, and being able to capture biases that appear in typical usage (rather than just extreme, rare cases). Relatedly, bias evaluation should surface not only egregious biases but also ones that are subtle and commonplace, such as a likelihood for talking about appearances with regard to women. We present FairPair, an evaluation framework for assessing differential treatment that occurs during ordinary usage. FairPair operates through counterfactual pairs, but crucially, the paired continuations are grounded in the same demographic group, which ensures equivalent comparison. Additionally, unlike prior work, our method factors in the inherent variability that comes from the generation process itself by measuring the sampling variability. We present an evaluation of several commonly used generative models and a qualitative analysis that indicates a preference for discussing family and hobbies with regard to women.
Teaching Large Language Models to Reason with Reinforcement Learning
Mar 07, 2024



Reinforcement Learning from Human Feedback (\textbf{RLHF}) has emerged as a dominant approach for aligning LLM outputs with human preferences. Inspired by the success of RLHF, we study the performance of multiple algorithms that learn from feedback (Expert Iteration, Proximal Policy Optimization (\textbf{PPO}), Return-Conditioned RL) on improving LLM reasoning capabilities. We investigate both sparse and dense rewards provided to the LLM both heuristically and via a learned reward model. We additionally start from multiple model sizes and initializations both with and without supervised fine-tuning (\textbf{SFT}) data. Overall, we find all algorithms perform comparably, with Expert Iteration performing best in most cases. Surprisingly, we find the sample complexity of Expert Iteration is similar to that of PPO, requiring at most on the order of $10^6$ samples to converge from a pretrained checkpoint. We investigate why this is the case, concluding that during RL training models fail to explore significantly beyond solutions already produced by SFT models. Additionally, we discuss a trade off between maj@1 and pass@96 metric performance during SFT training and how conversely RL training improves both simultaneously. We then conclude by discussing the implications of our findings for RLHF and the future role of RL in LLM fine-tuning.
MultiContrievers: Analysis of Dense Retrieval Representations
Feb 24, 2024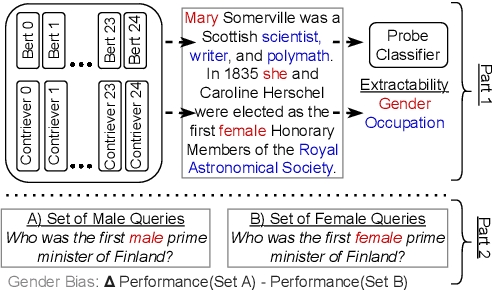

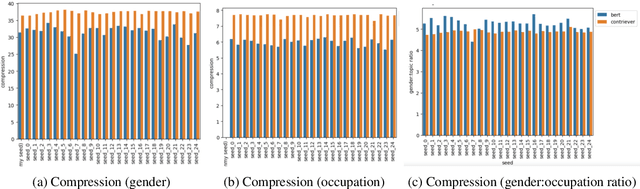
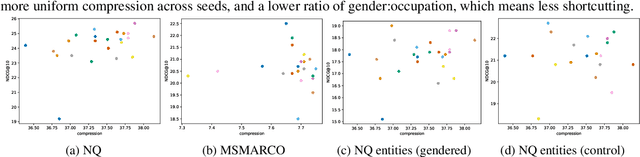
Dense retrievers compress source documents into (possibly lossy) vector representations, yet there is little analysis of what information is lost versus preserved, and how it affects downstream tasks. We conduct the first analysis of the information captured by dense retrievers compared to the language models they are based on (e.g., BERT versus Contriever). We use 25 MultiBert checkpoints as randomized initialisations to train MultiContrievers, a set of 25 contriever models. We test whether specific pieces of information -- such as gender and occupation -- can be extracted from contriever vectors of wikipedia-like documents. We measure this extractability via information theoretic probing. We then examine the relationship of extractability to performance and gender bias, as well as the sensitivity of these results to many random initialisations and data shuffles. We find that (1) contriever models have significantly increased extractability, but extractability usually correlates poorly with benchmark performance 2) gender bias is present, but is not caused by the contriever representations 3) there is high sensitivity to both random initialisation and to data shuffle, suggesting that future retrieval research should test across a wider spread of both.
TOOLVERIFIER: Generalization to New Tools via Self-Verification
Feb 21, 2024



Teaching language models to use tools is an important milestone towards building general assistants, but remains an open problem. While there has been significant progress on learning to use specific tools via fine-tuning, language models still struggle with learning how to robustly use new tools from only a few demonstrations. In this work we introduce a self-verification method which distinguishes between close candidates by self-asking contrastive questions during (1) tool selection; and (2) parameter generation. We construct synthetic, high-quality, self-generated data for this goal using Llama-2 70B, which we intend to release publicly. Extensive experiments on 4 tasks from the ToolBench benchmark, consisting of 17 unseen tools, demonstrate an average improvement of 22% over few-shot baselines, even in scenarios where the distinctions between candidate tools are finely nuanced.
GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements
Feb 13, 2024



State-of-the-art language models can exhibit impressive reasoning refinement capabilities on math, science or coding tasks. However, recent work demonstrates that even the best models struggle to identify \textit{when and where to refine} without access to external feedback. Outcome-based Reward Models (\textbf{ORMs}), trained to predict correctness of the final answer indicating when to refine, offer one convenient solution for deciding when to refine. Process Based Reward Models (\textbf{PRMs}), trained to predict correctness of intermediate steps, can then be used to indicate where to refine. But they are expensive to train, requiring extensive human annotations. In this paper, we propose Stepwise ORMs (\textbf{SORMs}) which are trained, only on synthetic data, to approximate the expected future reward of the optimal policy or $V^{\star}$. More specifically, SORMs are trained to predict the correctness of the final answer when sampling the current policy many times (rather than only once as in the case of ORMs). Our experiments show that SORMs can more accurately detect incorrect reasoning steps compared to ORMs, thus improving downstream accuracy when doing refinements. We then train \textit{global} refinement models, which take only the question and a draft solution as input and predict a corrected solution, and \textit{local} refinement models which also take as input a critique indicating the location of the first reasoning error. We generate training data for both models synthetically by reusing data used to train the SORM. We find combining global and local refinements, using the ORM as a reranker, significantly outperforms either one individually, as well as a best of three sample baseline. With this strategy we can improve the accuracy of a LLaMA-2 13B model (already fine-tuned with RL) on GSM8K from 53\% to 65\% when greedily sampled.
Efficient Tool Use with Chain-of-Abstraction Reasoning
Jan 30, 2024



To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools help LLMs access this external knowledge, but there remains challenges for fine-tuning LLM agents (e.g., Toolformer) to invoke tools in multi-step reasoning problems, where inter-connected tool calls require holistic and efficient tool usage planning. In this work, we propose a new method for LLMs to better leverage tools in multi-step reasoning. Our method, Chain-of-Abstraction (CoA), trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement. LLM agents trained with our method also show more efficient tool use, with inference speed being on average ~1.4x faster than baseline tool-augmented LLMs.