 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs
Mar 28, 2025Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
Sep 12, 2024



Large Language Models still struggle in challenging scenarios that leverage structured data, complex reasoning, or tool usage. In this paper, we propose Source2Synth: a new method that can be used for teaching LLMs new skills without relying on costly human annotations. Source2Synth takes as input a custom data source and produces synthetic data points with intermediate reasoning steps grounded in real-world sources. Source2Synth improves the dataset quality by discarding low-quality generations based on their answerability. We demonstrate the generality of this approach by applying it to two challenging domains: we test reasoning abilities in multi-hop question answering (MHQA), and tool usage in tabular question answering (TQA). Our method improves performance by 25.51% for TQA on WikiSQL and 22.57% for MHQA on HotPotQA compared to the fine-tuned baselines.
Does Double Descent Occur in Self-Supervised Learning?
Jul 15, 2023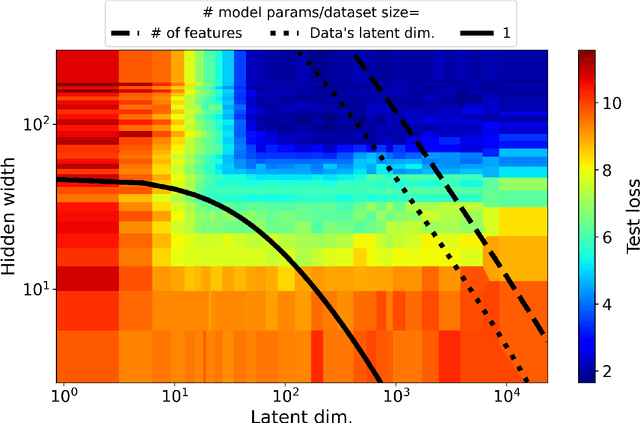
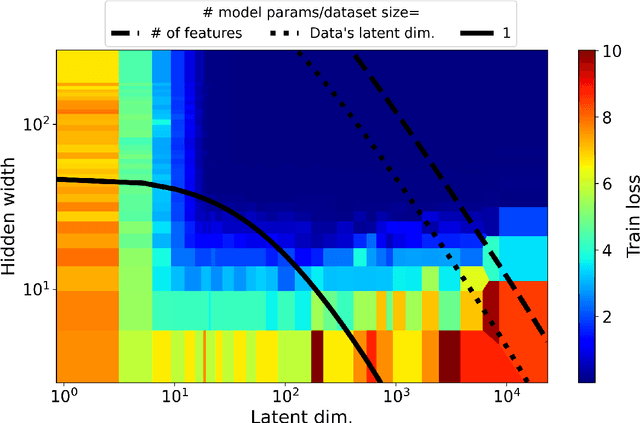
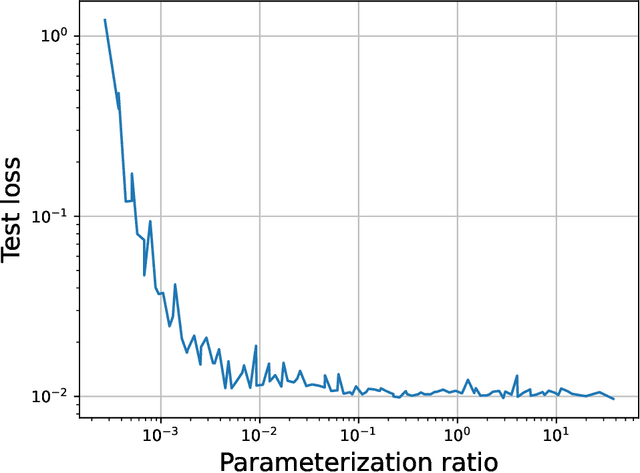
Most investigations into double descent have focused on supervised models while the few works studying self-supervised settings find a surprising lack of the phenomenon. These results imply that double descent may not exist in self-supervised models. We show this empirically using a standard and linear autoencoder, two previously unstudied settings. The test loss is found to have either a classical U-shape or to monotonically decrease instead of exhibiting a double-descent curve. We hope that further work on this will help elucidate the theoretical underpinnings of this phenomenon.