 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigentSearch-Q+: Enhancing Deep Research Agents with Structured Reasoning Tools
Apr 09, 2026Deep research requires reasoning over web evidence to answer open-ended questions, and it is a core capability for AI agents. Yet many deep research agents still rely on implicit, unstructured search behavior that causes redundant exploration and brittle evidence aggregation. Motivated by Anthropic's "think" tool paradigm and insights from the information-retrieval literature, we introduce Q+, a set of query and evidence processing tools that make web search more deliberate by guiding query planning, monitoring search progress, and extracting evidence from long web snapshots. We integrate Q+ into the browser sub-agent of Eigent, an open-source, production-ready multi-agent workforce for computer use, yielding EigentSearch-Q+. Across four benchmarks (SimpleQA-Verified, FRAMES, WebWalkerQA, and X-Bench DeepSearch), Q+ improves Eigent's browser agent benchmark-size-weighted average accuracy by 3.0, 3.8, and 0.6 percentage points (pp) for GPT-4.1, GPT-5.1, and Minimax M2.5 model backends, respectively. Case studies further suggest that EigentSearch-Q+ produces more coherent tool-calling trajectories by making search progress and evidence handling explicit.
Can Large Language Models Generalize Procedures Across Representations?
Feb 03, 2026Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Aug 27, 2025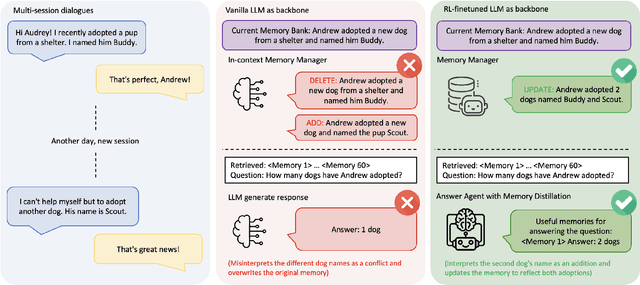
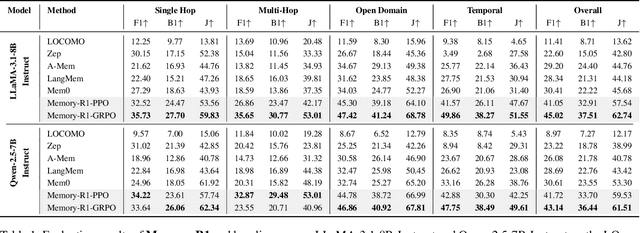
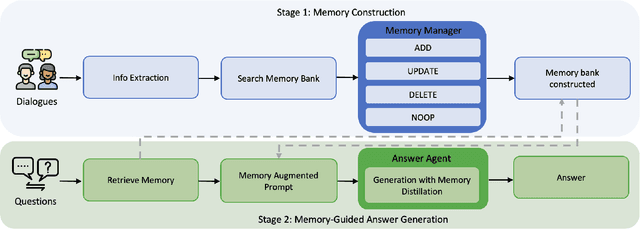

Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking any learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns to perform structured memory operations {ADD, UPDATE, DELETE, NOOP}, and an Answer Agent that selects the most relevant entries and reasons over them to produce an answer. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management and use with minimal supervision. With as few as 152 question-answer pairs and a corresponding temporal memory bank for training, Memory-R1 outperforms the most competitive existing baseline and demonstrates strong generalization across diverse question types and LLM backbones. Beyond presenting an effective approach, this work provides insights into how RL can unlock more agentic, memory-aware behaviors in LLMs, pointing toward richer, more persistent reasoning systems.
Distilling Tool Knowledge into Language Models via Back-Translated Traces
Jun 23, 2025Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
TCP: a Benchmark for Temporal Constraint-Based Planning
May 26, 2025Temporal reasoning and planning are essential capabilities for large language models (LLMs), yet most existing benchmarks evaluate them in isolation and under limited forms of complexity. To address this gap, we introduce the Temporal Constraint-based Planning (TCP) benchmark, that jointly assesses both capabilities. Each instance in TCP features a naturalistic dialogue around a collaborative project, where diverse and interdependent temporal constraints are explicitly or implicitly expressed, and models must infer an optimal schedule that satisfies all constraints. To construct TCP, we first generate abstract problem prototypes that are paired with realistic scenarios from various domains and enriched into dialogues using an LLM. A human quality check is performed on a sampled subset to confirm the reliability of our benchmark. We evaluate state-of-the-art LLMs and find that even the strongest models struggle with TCP, highlighting its difficulty and revealing limitations in LLMs' temporal constraint-based planning abilities. We analyze underlying failure cases, open source our benchmark, and hope our findings can inspire future research.
Image Tokens Matter: Mitigating Hallucination in Discrete Tokenizer-based Large Vision-Language Models via Latent Editing
May 24, 2025Large Vision-Language Models (LVLMs) with discrete image tokenizers unify multimodal representations by encoding visual inputs into a finite set of tokens. Despite their effectiveness, we find that these models still hallucinate non-existent objects. We hypothesize that this may be due to visual priors induced during training: When certain image tokens frequently co-occur in the same spatial regions and represent shared objects, they become strongly associated with the verbalizations of those objects. As a result, the model may hallucinate by evoking visually absent tokens that often co-occur with present ones. To test this assumption, we construct a co-occurrence graph of image tokens using a segmentation dataset and employ a Graph Neural Network (GNN) with contrastive learning followed by a clustering method to group tokens that frequently co-occur in similar visual contexts. We find that hallucinations predominantly correspond to clusters whose tokens dominate the input, and more specifically, that the visually absent tokens in those clusters show much higher correlation with hallucinated objects compared to tokens present in the image. Based on this observation, we propose a hallucination mitigation method that suppresses the influence of visually absent tokens by modifying latent image embeddings during generation. Experiments show our method reduces hallucinations while preserving expressivity. Code is available at https://github.com/weixingW/CGC-VTD/tree/main
AVerImaTeC: A Dataset for Automatic Verification of Image-Text Claims with Evidence from the Web
May 23, 2025Textual claims are often accompanied by images to enhance their credibility and spread on social media, but this also raises concerns about the spread of misinformation. Existing datasets for automated verification of image-text claims remain limited, as they often consist of synthetic claims and lack evidence annotations to capture the reasoning behind the verdict. In this work, we introduce AVerImaTeC, a dataset consisting of 1,297 real-world image-text claims. Each claim is annotated with question-answer (QA) pairs containing evidence from the web, reflecting a decomposed reasoning regarding the verdict. We mitigate common challenges in fact-checking datasets such as contextual dependence, temporal leakage, and evidence insufficiency, via claim normalization, temporally constrained evidence annotation, and a two-stage sufficiency check. We assess the consistency of the annotation in AVerImaTeC via inter-annotator studies, achieving a $\kappa=0.742$ on verdicts and $74.7\%$ consistency on QA pairs. We also propose a novel evaluation method for evidence retrieval and conduct extensive experiments to establish baselines for verifying image-text claims using open-web evidence.
Predicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
May 22, 2025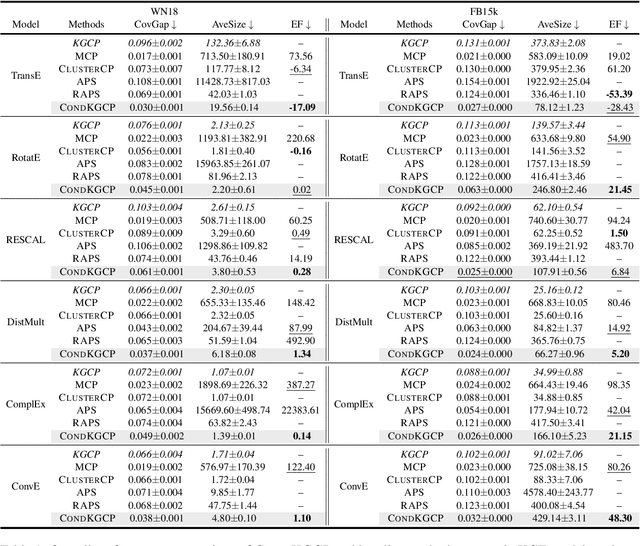
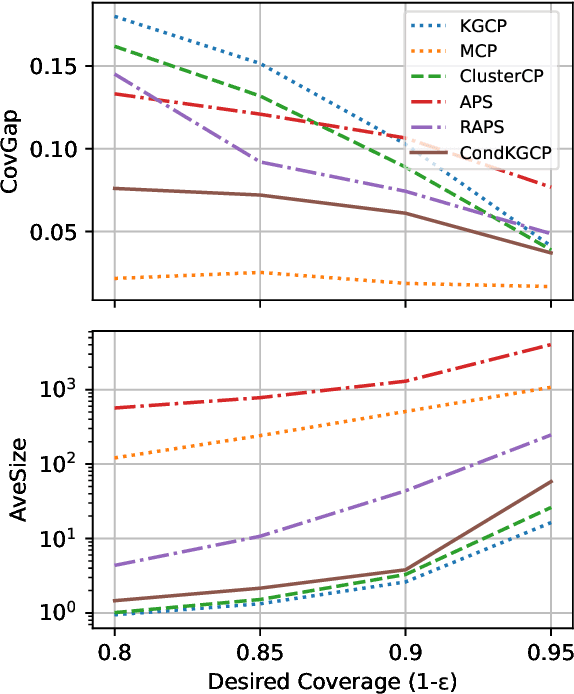
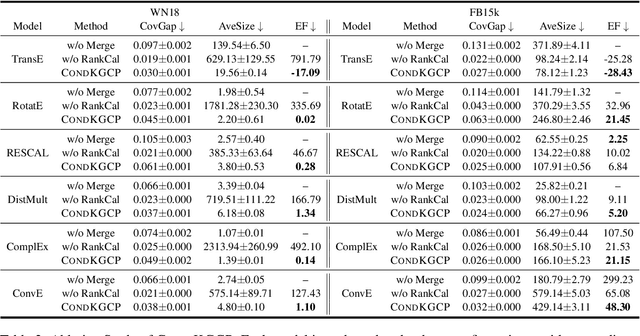
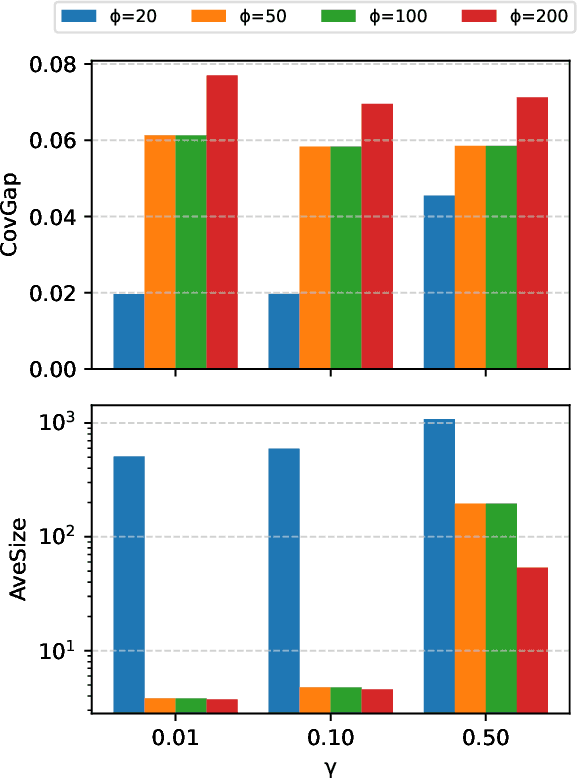
Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
Supposedly Equivalent Facts That Aren't? Entity Frequency in Pre-training Induces Asymmetry in LLMs
Mar 28, 2025Understanding and mitigating hallucinations in Large Language Models (LLMs) is crucial for ensuring reliable content generation. While previous research has primarily focused on "when" LLMs hallucinate, our work explains "why" and directly links model behaviour to the pre-training data that forms their prior knowledge. Specifically, we demonstrate that an asymmetry exists in the recognition of logically equivalent facts, which can be attributed to frequency discrepancies of entities appearing as subjects versus objects. Given that most pre-training datasets are inaccessible, we leverage the fully open-source OLMo series by indexing its Dolma dataset to estimate entity frequencies. Using relational facts (represented as triples) from Wikidata5M, we construct probing datasets to isolate this effect. Our experiments reveal that facts with a high-frequency subject and a low-frequency object are better recognised than their inverse, despite their logical equivalence. The pattern reverses in low-to-high frequency settings, and no statistically significant asymmetry emerges when both entities are high-frequency. These findings highlight the influential role of pre-training data in shaping model predictions and provide insights for inferring the characteristics of pre-training data in closed or partially closed LLMs.
The Future Outcome Reasoning and Confidence Assessment Benchmark
Feb 27, 2025
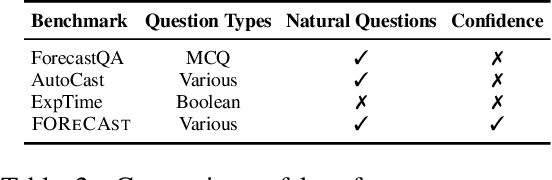
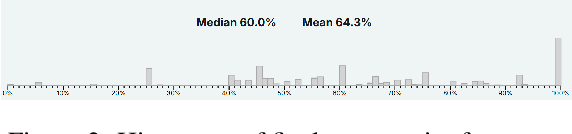
Forecasting is an important task in many domains, such as technology and economics. However existing forecasting benchmarks largely lack comprehensive confidence assessment, focus on limited question types, and often consist of artificial questions that do not align with real-world human forecasting needs. To address these gaps, we introduce FOReCAst (Future Outcome Reasoning and Confidence Assessment), a benchmark that evaluates models' ability to make predictions and their confidence in them. FOReCAst spans diverse forecasting scenarios involving Boolean questions, timeframe prediction, and quantity estimation, enabling a comprehensive evaluation of both prediction accuracy and confidence calibration for real-world applications.