 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERFT: Parameter-Efficient Routed Fine-Tuning for Mixture-of-Expert Model
Paper and Code

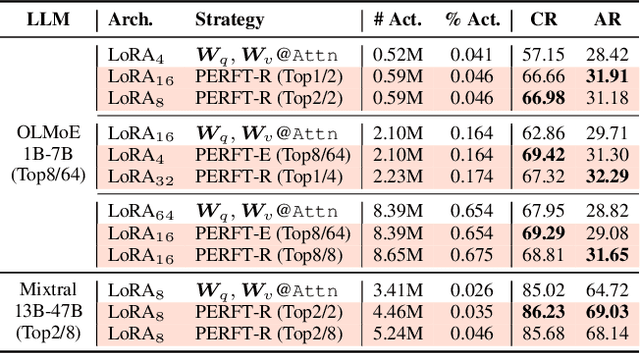


The Mixture-of-Experts (MoE) paradigm has emerged as a powerful approach for scaling transformers with improved resource utilization. However, efficiently fine-tuning MoE models remains largely underexplored. Inspired by recent works on Parameter-Efficient Fine-Tuning (PEFT), we present a unified framework for integrating PEFT modules directly into the MoE mechanism. Aligning with the core principles and architecture of MoE, our framework encompasses a set of design dimensions including various functional and composition strategies. By combining design choices within our framework, we introduce Parameter-Efficient Routed Fine-Tuning (PERFT) as a flexible and scalable family of PEFT strategies tailored for MoE models. Extensive experiments on adapting OLMoE-1B-7B and Mixtral-8$\times$7B for commonsense and arithmetic reasoning tasks demonstrate the effectiveness, scalability, and intriguing dynamics of PERFT. Additionally, we provide empirical findings for each specific design choice to facilitate better application of MoE and PEFT.