 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Source Reasoning-based Correction for Author Name Disambiguation
Jun 07, 2026Author name disambiguation is a critical challenge in academic search systems, often addressed through from-scratch and real-time disambiguation approaches. However, current algorithms remain vulnerable to cumulative errors of paper-author assignments and overlook inconsistent assignments across different sources. Resorting to expert annotation is resource-intensive. To this end, this paper explores a new perspective for author name disambiguation: cross-source correction by leveraging inconsistent assignments across sources. We propose CrossND, a full-stack framework that integrates data refinement, cross-source reasoning, and test-time scaling. First, a chain-of-refinement pipeline denoises author profiles and produces more accurate paper-author matching probabilities. Second, a supervised fine-tuning process incorporates these refined signals and a probabilistic soft logic-based cross-correction module to infer the assignments of which sources are incorrect. Third, test-time scaling further enhances the accuracy and robustness of the predictions. Experiments on real-world datasets indicate that CrossND consistently outperforms 17 baselines by leveraging cross-source reasoning without human intervention.
Leveraging Graph Structure in Seq2Seq Models for Knowledge Graph Link Prediction
May 18, 2026We introduce Graph-Augmented Sequence-to-Sequence (GA-S2S), a novel framework that integrates a T5-small encoder-decoder with a Relational Graph Attention Network (RGAT) to improve link prediction in knowledge graphs. While existing Seq2Seq models rely solely on surface-level textual descriptions of entities and relations and at best, flatten the neighborhoods of a query entity into a single linear sequence, thereby discarding the inherent graph structure, GA-S2S jointly encodes both textual features and the full $k$-hop subgraph topology surrounding the query entity. By integrating raw encoder outputs with RGAT's relation-aware embeddings, our model captures and leverages richer multi-hop relational patterns and textual information. Our preliminary experiments on the CoDEx dataset demonstrate that GA-S2S outperforms competitive Seq2Seq-based baseline models, achieving up to a 19\% relative gain in link prediction accuracy.
Integrating Meta-Features with Knowledge Graph Embeddings for Meta-Learning
Mar 20, 2026The vast collection of machine learning records available on the web presents a significant opportunity for meta-learning, where past experiments are leveraged to improve performance. Two crucial meta-learning tasks are pipeline performance estimation (PPE), which predicts pipeline performance on target datasets, and dataset performance-based similarity estimation (DPSE), which identifies datasets with similar performance patterns. Existing approaches primarily rely on dataset meta-features (e.g., number of instances, class entropy, etc.) to represent datasets numerically and approximate these meta-learning tasks. However, these approaches often overlook the wealth of past experimental results and pipeline metadata available. This limits their ability to capture dataset - pipeline interactions that reveal performance similarity patterns. In this work, we propose KGmetaSP, a knowledge-graph-embeddings approach that leverages existing experiment data to capture these interactions and improve both PPE and DPSE. We represent datasets and pipelines within a unified knowledge graph (KG) and derive embeddings that support pipeline-agnostic meta-models for PPE and distance-based retrieval for DPSE. To validate our approach, we construct a large-scale benchmark comprising 144,177 OpenML experiments, enabling a rich cross-dataset evaluation. KGmetaSP enables accurate PPE using a single pipeline-agnostic meta-model and improves DPSE over baselines. The proposed KGmetaSP, KG, and benchmark are released, establishing a new reference point for meta-learning and demonstrating how consolidating open experiment data into a unified KG advances the field.
GR-Agent: Adaptive Graph Reasoning Agent under Incomplete Knowledge
Dec 16, 2025

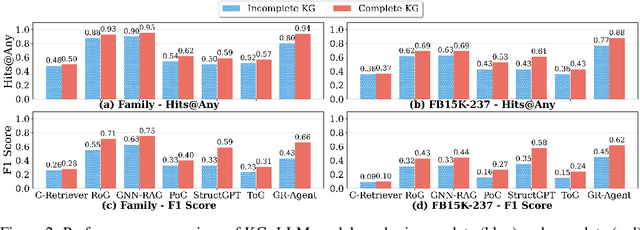

Large language models (LLMs) achieve strong results on knowledge graph question answering (KGQA), but most benchmarks assume complete knowledge graphs (KGs) where direct supporting triples exist. This reduces evaluation to shallow retrieval and overlooks the reality of incomplete KGs, where many facts are missing and answers must be inferred from existing facts. We bridge this gap by proposing a methodology for constructing benchmarks under KG incompleteness, which removes direct supporting triples while ensuring that alternative reasoning paths required to infer the answer remain. Experiments on benchmarks constructed using our methodology show that existing methods suffer consistent performance degradation under incompleteness, highlighting their limited reasoning ability. To overcome this limitation, we present the Adaptive Graph Reasoning Agent (GR-Agent). It first constructs an interactive environment from the KG, and then formalizes KGQA as agent environment interaction within this environment. GR-Agent operates over an action space comprising graph reasoning tools and maintains a memory of potential supporting reasoning evidence, including relevant relations and reasoning paths. Extensive experiments demonstrate that GR-Agent outperforms non-training baselines and performs comparably to training-based methods under both complete and incomplete settings.
What Breaks Knowledge Graph based RAG? Empirical Insights into Reasoning under Incomplete Knowledge
Aug 11, 2025Knowledge Graph-based Retrieval-Augmented Generation (KG-RAG) is an increasingly explored approach for combining the reasoning capabilities of large language models with the structured evidence of knowledge graphs. However, current evaluation practices fall short: existing benchmarks often include questions that can be directly answered using existing triples in KG, making it unclear whether models perform reasoning or simply retrieve answers directly. Moreover, inconsistent evaluation metrics and lenient answer matching criteria further obscure meaningful comparisons. In this work, we introduce a general method for constructing benchmarks, together with an evaluation protocol, to systematically assess KG-RAG methods under knowledge incompleteness. Our empirical results show that current KG-RAG methods have limited reasoning ability under missing knowledge, often rely on internal memorization, and exhibit varying degrees of generalization depending on their design.
Predicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
May 22, 2025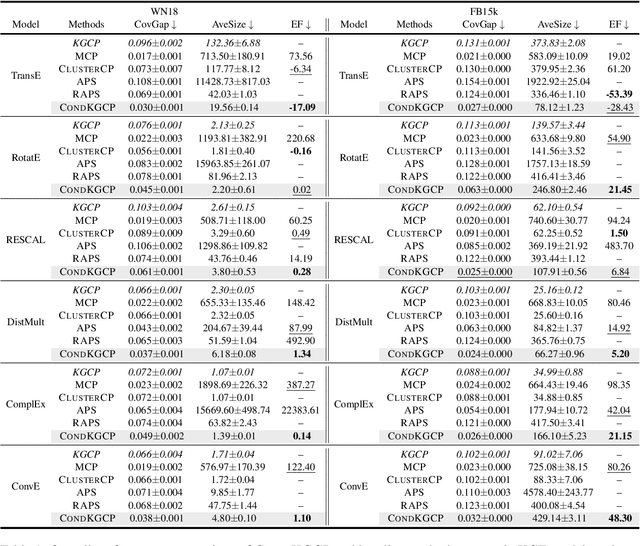
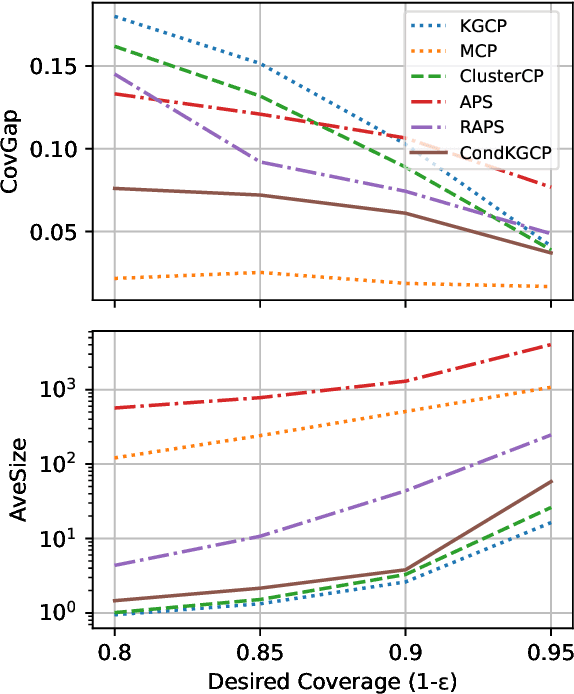
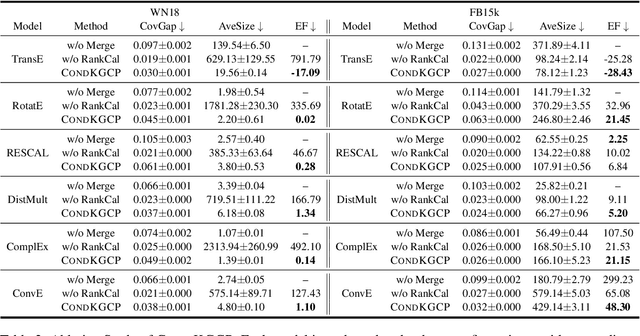
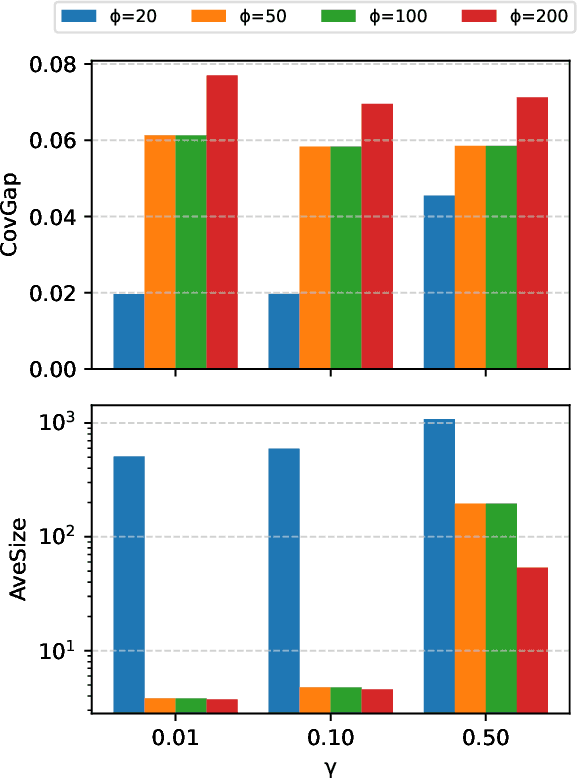
Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
Apr 07, 2025

Knowledge Graph based Retrieval-Augmented Generation (KG-RAG) is a technique that enhances Large Language Model (LLM) inference in tasks like Question Answering (QA) by retrieving relevant information from knowledge graphs (KGs). However, real-world KGs are often incomplete, meaning that essential information for answering questions may be missing. Existing benchmarks do not adequately capture the impact of KG incompleteness on KG-RAG performance. In this paper, we systematically evaluate KG-RAG methods under incomplete KGs by removing triples using different methods and analyzing the resulting effects. We demonstrate that KG-RAG methods are sensitive to KG incompleteness, highlighting the need for more robust approaches in realistic settings.
ReaLitE: Enrichment of Relation Embeddings in Knowledge Graphs using Numeric Literals
Apr 01, 2025



Most knowledge graph embedding (KGE) methods tailored for link prediction focus on the entities and relations in the graph, giving little attention to other literal values, which might encode important information. Therefore, some literal-aware KGE models attempt to either integrate numerical values into the embeddings of the entities or convert these numerics into entities during preprocessing, leading to information loss. Other methods concerned with creating relation-specific numerical features assume completeness of numerical data, which does not apply to real-world graphs. In this work, we propose ReaLitE, a novel relation-centric KGE model that dynamically aggregates and merges entities' numerical attributes with the embeddings of the connecting relations. ReaLitE is designed to complement existing conventional KGE methods while supporting multiple variations for numerical aggregations, including a learnable method. We comprehensively evaluated the proposed relation-centric embedding using several benchmarks for link prediction and node classification tasks. The results showed the superiority of ReaLitE over the state of the art in both tasks.
DAGE: DAG Query Answering via Relational Combinator with Logical Constraints
Oct 29, 2024Predicting answers to queries over knowledge graphs is called a complex reasoning task because answering a query requires subdividing it into subqueries. Existing query embedding methods use this decomposition to compute the embedding of a query as the combination of the embedding of the subqueries. This requirement limits the answerable queries to queries having a single free variable and being decomposable, which are called tree-form queries and correspond to the $\mathcal{SROI}^-$ description logic. In this paper, we define a more general set of queries, called DAG queries and formulated in the $\mathcal{ALCOIR}$ description logic, propose a query embedding method for them, called DAGE, and a new benchmark to evaluate query embeddings on them. Given the computational graph of a DAG query, DAGE combines the possibly multiple paths between two nodes into a single path with a trainable operator that represents the intersection of relations and learns DAG-DL from tautologies. We show that it is possible to implement DAGE on top of existing query embedding methods, and we empirically measure the improvement of our method over the results of vanilla methods evaluated in tree-form queries that approximate the DAG queries of our proposed benchmark.
Conformalized Answer Set Prediction for Knowledge Graph Embedding
Aug 15, 2024Knowledge graph embeddings (KGE) apply machine learning methods on knowledge graphs (KGs) to provide non-classical reasoning capabilities based on similarities and analogies. The learned KG embeddings are typically used to answer queries by ranking all potential answers, but rankings often lack a meaningful probabilistic interpretation - lower-ranked answers do not necessarily have a lower probability of being true. This limitation makes it difficult to distinguish plausible from implausible answers, posing challenges for the application of KGE methods in high-stakes domains like medicine. We address this issue by applying the theory of conformal prediction that allows generating answer sets, which contain the correct answer with probabilistic guarantees. We explain how conformal prediction can be used to generate such answer sets for link prediction tasks. Our empirical evaluation on four benchmark datasets using six representative KGE methods validates that the generated answer sets satisfy the probabilistic guarantees given by the theory of conformal prediction. We also demonstrate that the generated answer sets often have a sensible size and that the size adapts well with respect to the difficulty of the query.