 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentative Debates for Transparent Bias Detection [Technical Report]
Aug 06, 2025As the use of AI systems in society grows, addressing potential biases that emerge from data or are learned by models is essential to prevent systematic disadvantages against specific groups. Several notions of (un)fairness have been proposed in the literature, alongside corresponding algorithmic methods for detecting and mitigating unfairness, but, with very few exceptions, these tend to ignore transparency. Instead, interpretability and explainability are core requirements for algorithmic fairness, even more so than for other algorithmic solutions, given the human-oriented nature of fairness. In this paper, we contribute a novel interpretable, explainable method for bias detection relying on debates about the presence of bias against individuals, based on the values of protected features for the individuals and others in their neighbourhoods. Our method builds upon techniques from formal and computational argumentation, whereby debates result from arguing about biases within and across neighbourhoods. We provide formal, quantitative, and qualitative evaluations of our method, highlighting its strengths in performance against baselines, as well as its interpretability and explainability.
Applying Attribution Explanations in Truth-Discovery Quantitative Bipolar Argumentation Frameworks
Sep 09, 2024



Explaining the strength of arguments under gradual semantics is receiving increasing attention. For example, various studies in the literature offer explanations by computing the attribution scores of arguments or edges in Quantitative Bipolar Argumentation Frameworks (QBAFs). These explanations, known as Argument Attribution Explanations (AAEs) and Relation Attribution Explanations (RAEs), commonly employ removal-based and Shapley-based techniques for computing the attribution scores. While AAEs and RAEs have proven useful in several applications with acyclic QBAFs, they remain largely unexplored for cyclic QBAFs. Furthermore, existing applications tend to focus solely on either AAEs or RAEs, but do not compare them directly. In this paper, we apply both AAEs and RAEs, to Truth Discovery QBAFs (TD-QBAFs), which assess the trustworthiness of sources (e.g., websites) and their claims (e.g., the severity of a virus), and feature complex cycles. We find that both AAEs and RAEs can provide interesting explanations and can give non-trivial and surprising insights.
Predictive Multiplicity of Knowledge Graph Embeddings in Link Prediction
Aug 15, 2024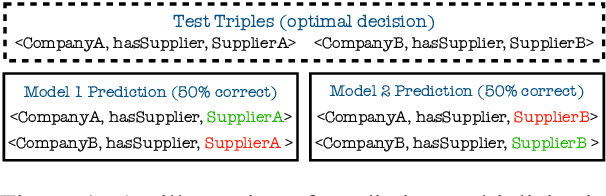

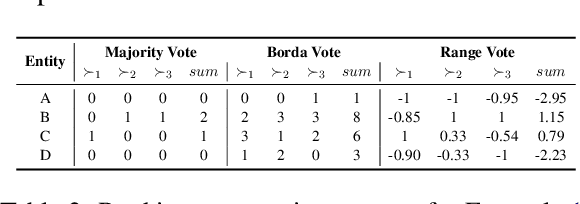

Knowledge graph embedding (KGE) models are often used to predict missing links for knowledge graphs (KGs). However, multiple KG embeddings can perform almost equally well for link prediction yet suggest conflicting predictions for certain queries, termed \textit{predictive multiplicity} in literature. This behavior poses substantial risks for KGE-based applications in high-stake domains but has been overlooked in KGE research. In this paper, we define predictive multiplicity in link prediction. We introduce evaluation metrics and measure predictive multiplicity for representative KGE methods on commonly used benchmark datasets. Our empirical study reveals significant predictive multiplicity in link prediction, with $8\%$ to $39\%$ testing queries exhibiting conflicting predictions. To address this issue, we propose leveraging voting methods from social choice theory, significantly mitigating conflicts by $66\%$ to $78\%$ according to our experiments.
Conformalized Answer Set Prediction for Knowledge Graph Embedding
Aug 15, 2024Knowledge graph embeddings (KGE) apply machine learning methods on knowledge graphs (KGs) to provide non-classical reasoning capabilities based on similarities and analogies. The learned KG embeddings are typically used to answer queries by ranking all potential answers, but rankings often lack a meaningful probabilistic interpretation - lower-ranked answers do not necessarily have a lower probability of being true. This limitation makes it difficult to distinguish plausible from implausible answers, posing challenges for the application of KGE methods in high-stakes domains like medicine. We address this issue by applying the theory of conformal prediction that allows generating answer sets, which contain the correct answer with probabilistic guarantees. We explain how conformal prediction can be used to generate such answer sets for link prediction tasks. Our empirical evaluation on four benchmark datasets using six representative KGE methods validates that the generated answer sets satisfy the probabilistic guarantees given by the theory of conformal prediction. We also demonstrate that the generated answer sets often have a sensible size and that the size adapts well with respect to the difficulty of the query.
Approximating Probabilistic Inference in Statistical EL with Knowledge Graph Embeddings
Jul 16, 2024Statistical information is ubiquitous but drawing valid conclusions from it is prohibitively hard. We explain how knowledge graph embeddings can be used to approximate probabilistic inference efficiently using the example of Statistical EL (SEL), a statistical extension of the lightweight Description Logic EL. We provide proofs for runtime and soundness guarantees, and empirically evaluate the runtime and approximation quality of our approach.
CE-QArg: Counterfactual Explanations for Quantitative Bipolar Argumentation Frameworks (Technical Report)
Jul 11, 2024



There is a growing interest in understanding arguments' strength in Quantitative Bipolar Argumentation Frameworks (QBAFs). Most existing studies focus on attribution-based methods that explain an argument's strength by assigning importance scores to other arguments but fail to explain how to change the current strength to a desired one. To solve this issue, we introduce counterfactual explanations for QBAFs. We discuss problem variants and propose an iterative algorithm named Counterfactual Explanations for Quantitative bipolar Argumentation frameworks (CE-QArg). CE-QArg can identify valid and cost-effective counterfactual explanations based on two core modules, polarity and priority, which help determine the updating direction and magnitude for each argument, respectively. We discuss some formal properties of our counterfactual explanations and empirically evaluate CE-QArg on randomly generated QBAFs.
Contribution Functions for Quantitative Bipolar Argumentation Graphs: A Principle-based Analysis
Jan 16, 2024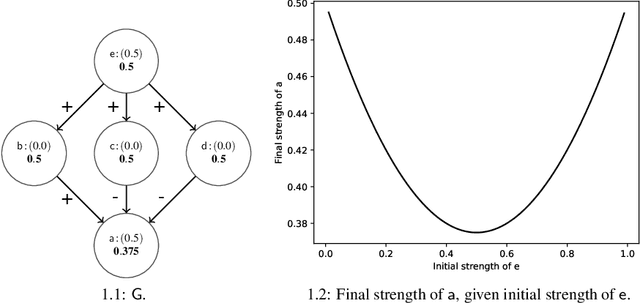
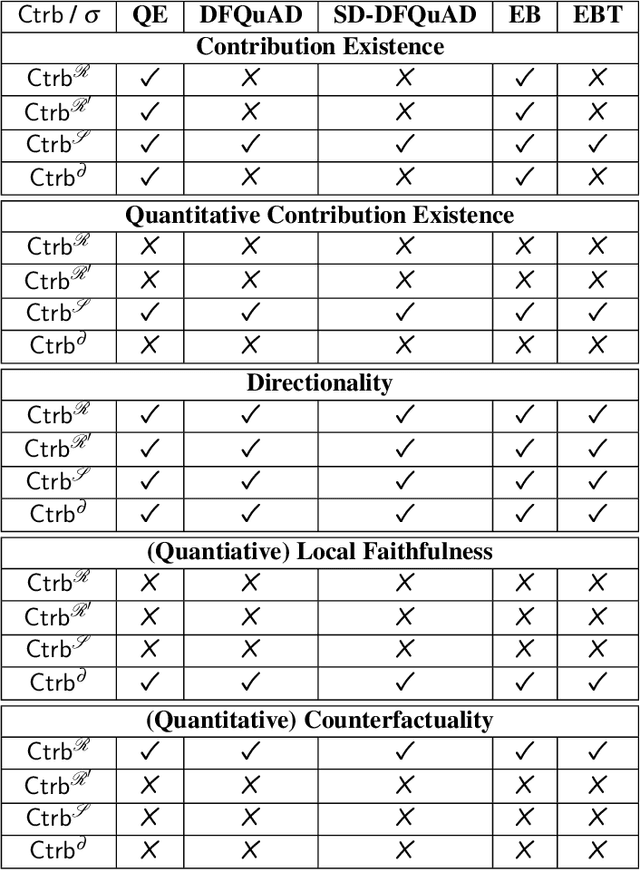

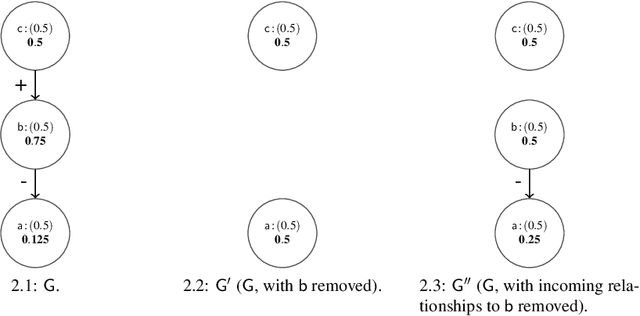
We present a principle-based analysis of contribution functions for quantitative bipolar argumentation graphs that quantify the contribution of one argument to another. The introduced principles formalise the intuitions underlying different contribution functions as well as expectations one would have regarding the behaviour of contribution functions in general. As none of the covered contribution functions satisfies all principles, our analysis can serve as a tool that enables the selection of the most suitable function based on the requirements of a given use case.
Robust Knowledge Extraction from Large Language Models using Social Choice Theory
Dec 22, 2023Large-language models (LLMs) have the potential to support a wide range of applications like conversational agents, creative writing, text improvement, and general query answering. However, they are ill-suited for query answering in high-stake domains like medicine because they generate answers at random and their answers are typically not robust - even the same query can result in different answers when prompted multiple times. In order to improve the robustness of LLM queries, we propose using ranking queries repeatedly and to aggregate the queries using methods from social choice theory. We study ranking queries in diagnostic settings like medical and fault diagnosis and discuss how the Partial Borda Choice function from the literature can be applied to merge multiple query results. We discuss some additional interesting properties in our setting and evaluate the robustness of our approach empirically.
Promoting Counterfactual Robustness through Diversity
Dec 12, 2023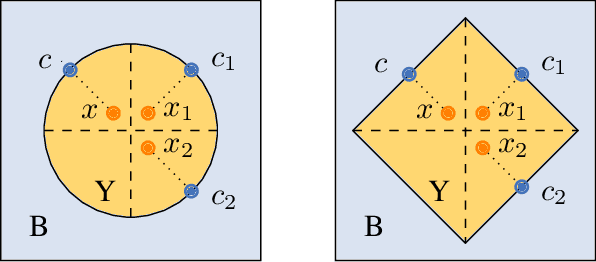

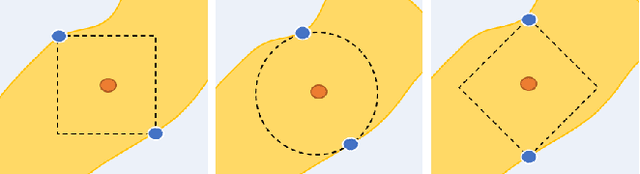

Counterfactual explanations shed light on the decisions of black-box models by explaining how an input can be altered to obtain a favourable decision from the model (e.g., when a loan application has been rejected). However, as noted recently, counterfactual explainers may lack robustness in the sense that a minor change in the input can cause a major change in the explanation. This can cause confusion on the user side and open the door for adversarial attacks. In this paper, we study some sources of non-robustness. While there are fundamental reasons for why an explainer that returns a single counterfactual cannot be robust in all instances, we show that some interesting robustness guarantees can be given by reporting multiple rather than a single counterfactual. Unfortunately, the number of counterfactuals that need to be reported for the theoretical guarantees to hold can be prohibitively large. We therefore propose an approximation algorithm that uses a diversity criterion to select a feasible number of most relevant explanations and study its robustness empirically. Our experiments indicate that our method improves the state-of-the-art in generating robust explanations, while maintaining other desirable properties and providing competitive computational performance.
ProtoArgNet: Interpretable Image Classification with Super-Prototypes and Argumentation [Technical Report]
Nov 26, 2023We propose ProtoArgNet, a novel interpretable deep neural architecture for image classification in the spirit of prototypical-part-learning as found, e.g. in ProtoPNet. While earlier approaches associate every class with multiple prototypical-parts, ProtoArgNet uses super-prototypes that combine prototypical-parts into single prototypical class representations. Furthermore, while earlier approaches use interpretable classification layers, e.g. logistic regression in ProtoPNet, ProtoArgNet improves accuracy with multi-layer perceptrons while relying upon an interpretable reading thereof based on a form of argumentation. ProtoArgNet is customisable to user cognitive requirements by a process of sparsification of the multi-layer perceptron/argumentation component. Also, as opposed to other prototypical-part-learning approaches, ProtoArgNet can recognise spatial relations between different prototypical-parts that are from different regions in images, similar to how CNNs capture relations between patterns recognized in earlier layers.