 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lattice Representation Hypothesis of Large Language Models
Mar 01, 2026We propose the Lattice Representation Hypothesis of large language models: a symbolic backbone that grounds conceptual hierarchies and logical operations in embedding geometry. Our framework unifies the Linear Representation Hypothesis with Formal Concept Analysis (FCA), showing that linear attribute directions with separating thresholds induce a concept lattice via half-space intersections. This geometry enables symbolic reasoning through geometric meet (intersection) and join (union) operations, and admits a canonical form when attribute directions are linearly independent. Experiments on WordNet sub-hierarchies provide empirical evidence that LLM embeddings encode concept lattices and their logical structure, revealing a principled bridge between continuous geometry and symbolic abstraction.
SEMMA: A Semantic Aware Knowledge Graph Foundation Model
May 26, 2025Knowledge Graph Foundation Models (KGFMs) have shown promise in enabling zero-shot reasoning over unseen graphs by learning transferable patterns. However, most existing KGFMs rely solely on graph structure, overlooking the rich semantic signals encoded in textual attributes. We introduce SEMMA, a dual-module KGFM that systematically integrates transferable textual semantics alongside structure. SEMMA leverages Large Language Models (LLMs) to enrich relation identifiers, generating semantic embeddings that subsequently form a textual relation graph, which is fused with the structural component. Across 54 diverse KGs, SEMMA outperforms purely structural baselines like ULTRA in fully inductive link prediction. Crucially, we show that in more challenging generalization settings, where the test-time relation vocabulary is entirely unseen, structural methods collapse while SEMMA is 2x more effective. Our findings demonstrate that textual semantics are critical for generalization in settings where structure alone fails, highlighting the need for foundation models that unify structural and linguistic signals in knowledge reasoning.
Predicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
May 22, 2025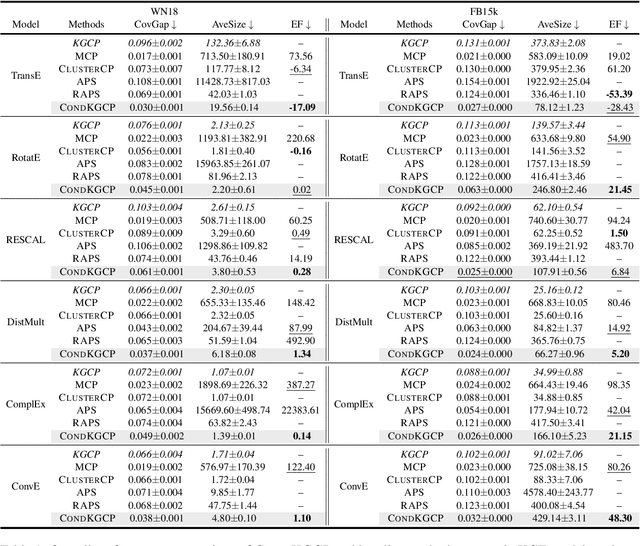
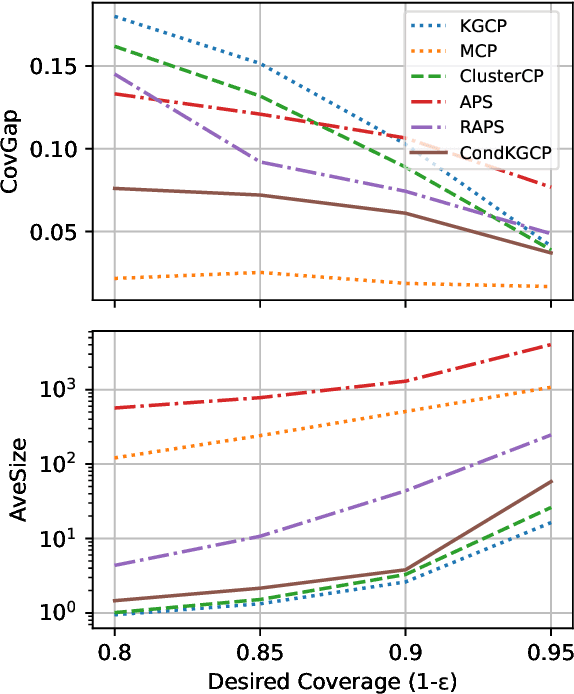
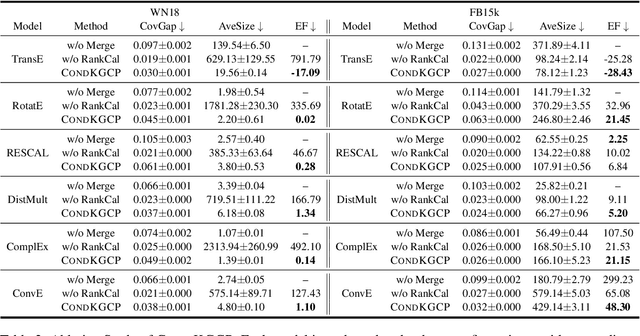
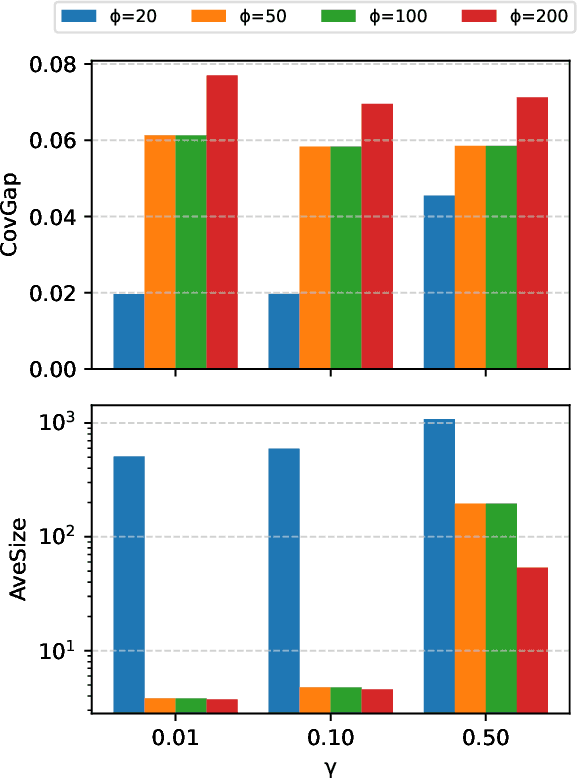
Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
3D Gaussian Adaptive Reconstruction for Fourier Light-Field Microscopy
May 19, 2025Compared to light-field microscopy (LFM), which enables high-speed volumetric imaging but suffers from non-uniform spatial sampling, Fourier light-field microscopy (FLFM) introduces sub-aperture division at the pupil plane, thereby ensuring spatially invariant sampling and enhancing spatial resolution. Conventional FLFM reconstruction methods, such as Richardson-Lucy (RL) deconvolution, exhibit poor axial resolution and signal degradation due to the ill-posed nature of the inverse problem. While data-driven approaches enhance spatial resolution by leveraging high-quality paired datasets or imposing structural priors, Neural Radiance Fields (NeRF)-based methods employ physics-informed self-supervised learning to overcome these limitations, yet they are hindered by substantial computational costs and memory demands. Therefore, we propose 3D Gaussian Adaptive Tomography (3DGAT) for FLFM, a 3D gaussian splatting based self-supervised learning framework that significantly improves the volumetric reconstruction quality of FLFM while maintaining computational efficiency. Experimental results indicate that our approach achieves higher resolution and improved reconstruction accuracy, highlighting its potential to advance FLFM imaging and broaden its applications in 3D optical microscopy.
Spike Imaging Velocimetry: Dense Motion Estimation of Fluids Using Spike Cameras
Apr 26, 2025


The need for accurate and non-intrusive flow measurement methods has led to the widespread adoption of Particle Image Velocimetry (PIV), a powerful diagnostic tool in fluid motion estimation. This study investigates the tremendous potential of spike cameras (a type of ultra-high-speed, high-dynamic-range camera) in PIV. We propose a deep learning framework, Spike Imaging Velocimetry (SIV), designed specifically for highly turbulent and intricate flow fields. To aggregate motion features from the spike stream while minimizing information loss, we incorporate a Detail-Preserving Hierarchical Transform (DPHT) module. Additionally, we introduce a Graph Encoder (GE) to extract contextual features from highly complex fluid flows. Furthermore, we present a spike-based PIV dataset, Particle Scenes with Spike and Displacement (PSSD), which provides labeled data for three challenging fluid dynamics scenarios. Our proposed method achieves superior performance compared to existing baseline methods on PSSD. The datasets and our implementation of SIV are open-sourced in the supplementary materials.
Inter-event Interval Microscopy for Event Cameras
Apr 08, 2025Event cameras, an innovative bio-inspired sensor, differ from traditional cameras by sensing changes in intensity rather than directly perceiving intensity and recording these variations as a continuous stream of "events". The intensity reconstruction from these sparse events has long been a challenging problem. Previous approaches mainly focused on transforming motion-induced events into videos or achieving intensity imaging for static scenes by integrating modulation devices at the event camera acquisition end. In this paper, for the first time, we achieve event-to-intensity conversion using a static event camera for both static and dynamic scenes in fluorescence microscopy. Unlike conventional methods that primarily rely on event integration, the proposed Inter-event Interval Microscopy (IEIM) quantifies the time interval between consecutive events at each pixel. With a fixed threshold in the event camera, the time interval can precisely represent the intensity. At the hardware level, the proposed IEIM integrates a pulse light modulation device within a microscope equipped with an event camera, termed Pulse Modulation-based Event-driven Fluorescence Microscopy. Additionally, we have collected IEIMat dataset under various scenes including high dynamic range and high-speed scenarios. Experimental results on the IEIMat dataset demonstrate that the proposed IEIM achieves superior spatial and temporal resolution, as well as a higher dynamic range, with lower bandwidth compared to other methods. The code and the IEIMat dataset will be made publicly available.
A Value Mapping Virtual Staining Framework for Large-scale Histological Imaging
Jan 07, 2025



The emergence of virtual staining technology provides a rapid and efficient alternative for researchers in tissue pathology. It enables the utilization of unlabeled microscopic samples to generate virtual replicas of chemically stained histological slices, or facilitate the transformation of one staining type into another. The remarkable performance of generative networks, such as CycleGAN, offers an unsupervised learning approach for virtual coloring, overcoming the limitations of high-quality paired data required in supervised learning. Nevertheless, large-scale color transformation necessitates processing large field-of-view images in patches, often resulting in significant boundary inconsistency and artifacts. Additionally, the transformation between different colorized modalities typically needs further efforts to modify loss functions and tune hyperparameters for independent training of networks. In this study, we introduce a general virtual staining framework that is adaptable to various conditions. We propose a loss function based on the value mapping constraint to ensure the accuracy of virtual coloring between different pathological modalities, termed the Value Mapping Generative Adversarial Network (VM-GAN). Meanwhile, we present a confidence-based tiling method to address the challenge of boundary inconsistency arising from patch-wise processing. Experimental results on diverse data with varying staining protocols demonstrate that our method achieves superior quantitative indicators and improved visual perception.
A Systematic Examination of Preference Learning through the Lens of Instruction-Following
Dec 18, 2024Preference learning is a widely adopted post-training technique that aligns large language models (LLMs) to human preferences and improves specific downstream task capabilities. In this work we systematically investigate how specific attributes of preference datasets affect the alignment and downstream performance of LLMs in instruction-following tasks. We use a novel synthetic data generation pipeline to generate 48,000 unique instruction-following prompts with combinations of 23 verifiable constraints that enable fine-grained and automated quality assessments of model responses. With our synthetic prompts, we use two preference dataset curation methods - rejection sampling (RS) and Monte Carlo Tree Search (MCTS) - to obtain pairs of (chosen, rejected) responses. Then, we perform experiments investigating the effects of (1) the presence of shared prefixes between the chosen and rejected responses, (2) the contrast and quality of the chosen, rejected responses and (3) the complexity of the training prompts. Our experiments reveal that shared prefixes in preference pairs, as generated by MCTS, provide marginal but consistent improvements and greater stability across challenging training configurations. High-contrast preference pairs generally outperform low-contrast pairs; however, combining both often yields the best performance by balancing diversity and learning efficiency. Additionally, training on prompts of moderate difficulty leads to better generalization across tasks, even for more complex evaluation scenarios, compared to overly challenging prompts. Our findings provide actionable insights into optimizing preference data curation for instruction-following tasks, offering a scalable and effective framework for enhancing LLM training and alignment.
DAGE: DAG Query Answering via Relational Combinator with Logical Constraints
Oct 29, 2024Predicting answers to queries over knowledge graphs is called a complex reasoning task because answering a query requires subdividing it into subqueries. Existing query embedding methods use this decomposition to compute the embedding of a query as the combination of the embedding of the subqueries. This requirement limits the answerable queries to queries having a single free variable and being decomposable, which are called tree-form queries and correspond to the $\mathcal{SROI}^-$ description logic. In this paper, we define a more general set of queries, called DAG queries and formulated in the $\mathcal{ALCOIR}$ description logic, propose a query embedding method for them, called DAGE, and a new benchmark to evaluate query embeddings on them. Given the computational graph of a DAG query, DAGE combines the possibly multiple paths between two nodes into a single path with a trainable operator that represents the intersection of relations and learns DAG-DL from tautologies. We show that it is possible to implement DAGE on top of existing query embedding methods, and we empirically measure the improvement of our method over the results of vanilla methods evaluated in tree-form queries that approximate the DAG queries of our proposed benchmark.
Visual Representation Learning Guided By Multi-modal Prior Knowledge
Oct 21, 2024Despite the remarkable success of deep neural networks (DNNs) in computer vision, they fail to remain high-performing when facing distribution shifts between training and testing data. In this paper, we propose Knowledge-Guided Visual representation learning (KGV), a distribution-based learning approach leveraging multi-modal prior knowledge, to improve generalization under distribution shift. We use prior knowledge from two distinct modalities: 1) a knowledge graph (KG) with hierarchical and association relationships; and 2) generated synthetic images of visual elements semantically represented in the KG. The respective embeddings are generated from the given modalities in a common latent space, i.e., visual embeddings from original and synthetic images as well as knowledge graph embeddings (KGEs). These embeddings are aligned via a novel variant of translation-based KGE methods, where the node and relation embeddings of the KG are modeled as Gaussian distributions and translations respectively. We claim that incorporating multi-model prior knowledge enables more regularized learning of image representations. Thus, the models are able to better generalize across different data distributions. We evaluate KGV on different image classification tasks with major or minor distribution shifts, namely road sign classification across datasets from Germany, China, and Russia, image classification with the mini-ImageNet dataset and its variants, as well as the DVM-CAR dataset. The results demonstrate that KGV consistently exhibits higher accuracy and data efficiency than the baselines across all experiments.