 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Examination of Preference Learning through the Lens of Instruction-Following
Dec 18, 2024Preference learning is a widely adopted post-training technique that aligns large language models (LLMs) to human preferences and improves specific downstream task capabilities. In this work we systematically investigate how specific attributes of preference datasets affect the alignment and downstream performance of LLMs in instruction-following tasks. We use a novel synthetic data generation pipeline to generate 48,000 unique instruction-following prompts with combinations of 23 verifiable constraints that enable fine-grained and automated quality assessments of model responses. With our synthetic prompts, we use two preference dataset curation methods - rejection sampling (RS) and Monte Carlo Tree Search (MCTS) - to obtain pairs of (chosen, rejected) responses. Then, we perform experiments investigating the effects of (1) the presence of shared prefixes between the chosen and rejected responses, (2) the contrast and quality of the chosen, rejected responses and (3) the complexity of the training prompts. Our experiments reveal that shared prefixes in preference pairs, as generated by MCTS, provide marginal but consistent improvements and greater stability across challenging training configurations. High-contrast preference pairs generally outperform low-contrast pairs; however, combining both often yields the best performance by balancing diversity and learning efficiency. Additionally, training on prompts of moderate difficulty leads to better generalization across tasks, even for more complex evaluation scenarios, compared to overly challenging prompts. Our findings provide actionable insights into optimizing preference data curation for instruction-following tasks, offering a scalable and effective framework for enhancing LLM training and alignment.
Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning
Jun 10, 2024Language agents perform complex tasks by using tools to execute each step precisely. However, most existing agents are based on proprietary models or designed to target specific tasks, such as mathematics or multi-hop question answering. We introduce Husky, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning. Husky iterates between two stages: 1) generating the next action to take towards solving a given task and 2) executing the action using expert models and updating the current solution state. We identify a thorough ontology of actions for addressing complex tasks and curate high-quality data to train expert models for executing these actions. Our experiments show that Husky outperforms prior language agents across 14 evaluation datasets. Moreover, we introduce HuskyQA, a new evaluation set which stress tests language agents for mixed-tool reasoning, with a focus on retrieving missing knowledge and performing numerical reasoning. Despite using 7B models, Husky matches or even exceeds frontier LMs such as GPT-4 on these tasks, showcasing the efficacy of our holistic approach in addressing complex reasoning problems. Our code and models are available at https://github.com/agent-husky/Husky-v1.
TaskWeb: Selecting Better Source Tasks for Multi-task NLP
May 22, 2023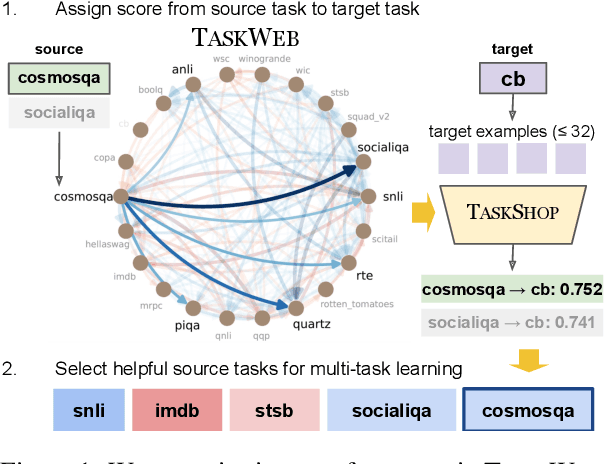
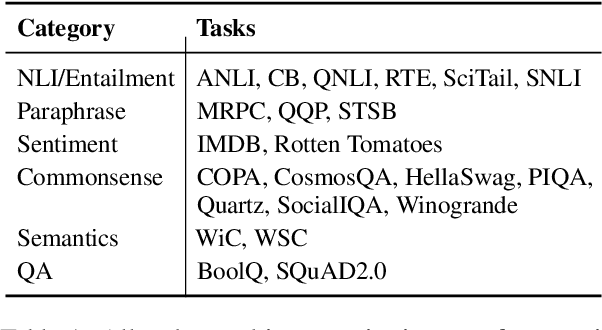
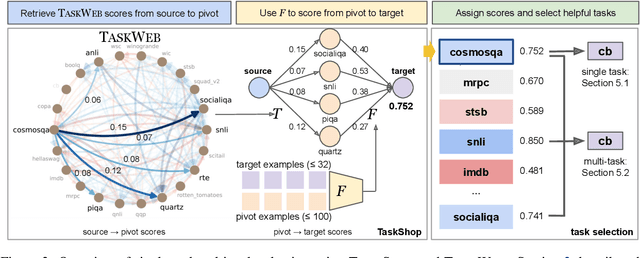
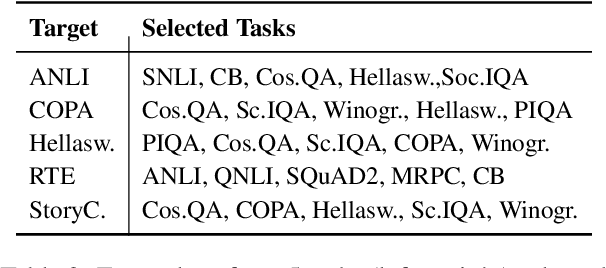
Recent work in NLP has shown promising results in training models on large amounts of tasks to achieve better generalization. However, it is not well-understood how tasks are related, and how helpful training tasks can be chosen for a new task. In this work, we investigate whether knowing task relationships via pairwise task transfer improves choosing one or more source tasks that help to learn a new target task. We provide TaskWeb, a large-scale benchmark of pairwise task transfers for 22 NLP tasks using three different model types, sizes, and adaptation methods, spanning about 25,000 experiments. Then, we design a new method TaskShop based on our analysis of TaskWeb. TaskShop uses TaskWeb to estimate the benefit of using a source task for learning a new target, and to choose a subset of helpful training tasks for multi-task learning. Our method improves overall rankings and top-k precision of source tasks by 12% and 29%, respectively. We also use TaskShop to build smaller multi-task training sets that improve zero-shot performances across 11 different target tasks by at least 4.3%.
Induce, Edit, Retrieve: Language Grounded Multimodal Schema for Instructional Video Retrieval
Nov 17, 2021

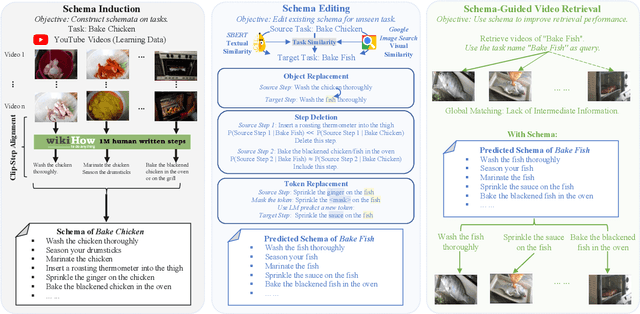
Schemata are structured representations of complex tasks that can aid artificial intelligence by allowing models to break down complex tasks into intermediate steps. We propose a novel system that induces schemata from web videos and generalizes them to capture unseen tasks with the goal of improving video retrieval performance. Our system proceeds in three major phases: (1) Given a task with related videos, we construct an initial schema for a task using a joint video-text model to match video segments with text representing steps from wikiHow; (2) We generalize schemata to unseen tasks by leveraging language models to edit the text within existing schemata. Through generalization, we can allow our schemata to cover a more extensive range of tasks with a small amount of learning data; (3) We conduct zero-shot instructional video retrieval with the unseen task names as the queries. Our schema-guided approach outperforms existing methods for video retrieval, and we demonstrate that the schemata induced by our system are better than those generated by other models.
BiSECT: Learning to Split and Rephrase Sentences with Bitexts
Sep 10, 2021
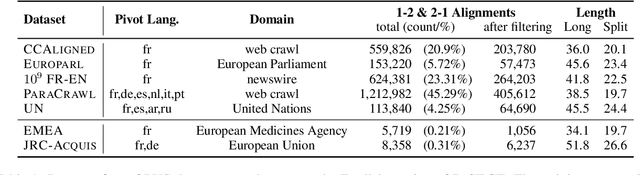
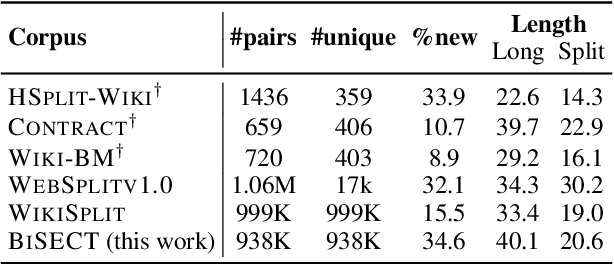
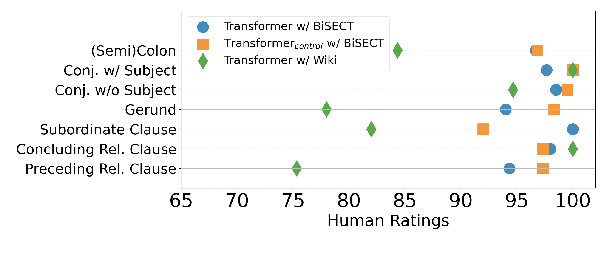
An important task in NLP applications such as sentence simplification is the ability to take a long, complex sentence and split it into shorter sentences, rephrasing as necessary. We introduce a novel dataset and a new model for this `split and rephrase' task. Our BiSECT training data consists of 1 million long English sentences paired with shorter, meaning-equivalent English sentences. We obtain these by extracting 1-2 sentence alignments in bilingual parallel corpora and then using machine translation to convert both sides of the corpus into the same language. BiSECT contains higher quality training examples than previous Split and Rephrase corpora, with sentence splits that require more significant modifications. We categorize examples in our corpus, and use these categories in a novel model that allows us to target specific regions of the input sentence to be split and edited. Moreover, we show that models trained on BiSECT can perform a wider variety of split operations and improve upon previous state-of-the-art approaches in automatic and human evaluations.